在 Rewrite 階段,我們最重要的目標是把人說的話變成檢索的話,以下是幾個常見的實作技巧:
GPU → GPU / TPU / ASIC;留存率 → CAC / LTV / NRR。例如:
找新能源車市場趨勢
Rewrite 後:
檢索 2024–2025 年中國與北美市場的 **新能源車銷量/成長率** 與 **政策影響** 相關的 **產業報告** 及 **主流媒體新聞**,並排除部落格的轉載文章
我們可以參考以下提示詞樣板,讓 LLM 扮演一個改寫的角色
請將以下「自然語言查詢」改寫為一個結構化的「檢索導向查詢」。
### 原始查詢:
{user_query}
### 改寫規則:
1. **加入時間範圍 (time_window)**:
* 若原始查詢未明確指定時間,預設為「最近 12 個月」。
* 若原始查詢包含時間資訊,請精確提取並格式化(例如:「2022 財年」、「2023 年 1 月 1 日至 2023 年 6 月 30 日」)。
2. **指定內容類型 (include_types)**:
* 從 [研究報告, 新聞, FAQ, 財報, 產品說明, 技術文件, 市場分析, 法律文件] 中選擇 **1 個或多個** 與查詢內容最相關的類型。
3. **補充領域關鍵詞 (enrich query)**:
* 分析原始查詢,為 `primary_query` 和所有 `sub_queries` 加入與查詢主題相關的專業術語、同義詞或更精確的表達,以提高檢索精準度。這些關鍵詞應融入查詢字串本身。
4. **分解子問題 (sub_queries)**:
* 若原始查詢包含多個不同的方面或子問題,請將其分解為多個獨立且具體的檢索子查詢,存放在 `sub_queries` 陣列中。若無明顯子問題,`sub_queries` 陣列可為空。
5. **明確排除項 (exclude_terms)**:
* 根據查詢意圖,明確列出任何應被排除的、明顯不相關的領域、產品、概念、技術或內容類型關鍵詞。若無排除項,`exclude_terms` 陣列可為空。
---
### 輸出格式 (JSON):
請確保輸出完全符合 JSON 格式結構,並填入具體的數值而非佔位符。
```json
{
"primary_query": "經過關鍵詞補充和優化後的主要檢索主題或問題,應盡量具體且包含領域術語",
"sub_queries": [
"分解出的第一個具體、可獨立檢索的子查詢",
"分解出的第二個具體、可獨立檢索的子查詢"
// ... 如果有更多子查詢
],
"include_types": [
"研究報告",
"新聞"
// ... 如果有更多相關類型
],
"exclude_terms": [
"不相關產品名稱",
"過時技術",
"特定 competitor 公司名稱"
// ... 如果有更多排除詞
],
"time_window": "最近 12 個月" // 例如 "最近 12 個月", "2023 財年", "2023-01-01 至 2023-06-30"
}
經過 Rewrite 的處理與優化後,就會到 Retrieve 進行檢索,預期從龐大的知識庫或文件中,快速且有效地找出與使用者查詢最為相關的原始段落或資訊片段
Retrieve 通常會整合多種檢索技術,最常聽到的應該就是向量檢索,他在 Retrieve 階段扮演了很重要的角色。
向量檢索是將各種格式的資料,例如文字段落、圖片、音檔甚至是程式碼,透過一種特殊的轉換模型 ( Embedding 模型) 轉換成一串固定長度的數字列表,我們稱之為向量或嵌入,這些向量代表了原始數據在某個語意空間中的位置
我們將每個詞彙或段落想像成一個點,然後把它投射到一個巨大的多維地圖上。在這個地圖上,語意相似的詞彙或段落,它們所代表的點就會在空間中彼此靠近;而語意不相關的內容,它們的點則會距離較遠。例如,蘋果手機和 iPhone 所產生的向量會非常接近,而香蕉的向量則會遠離這兩者。
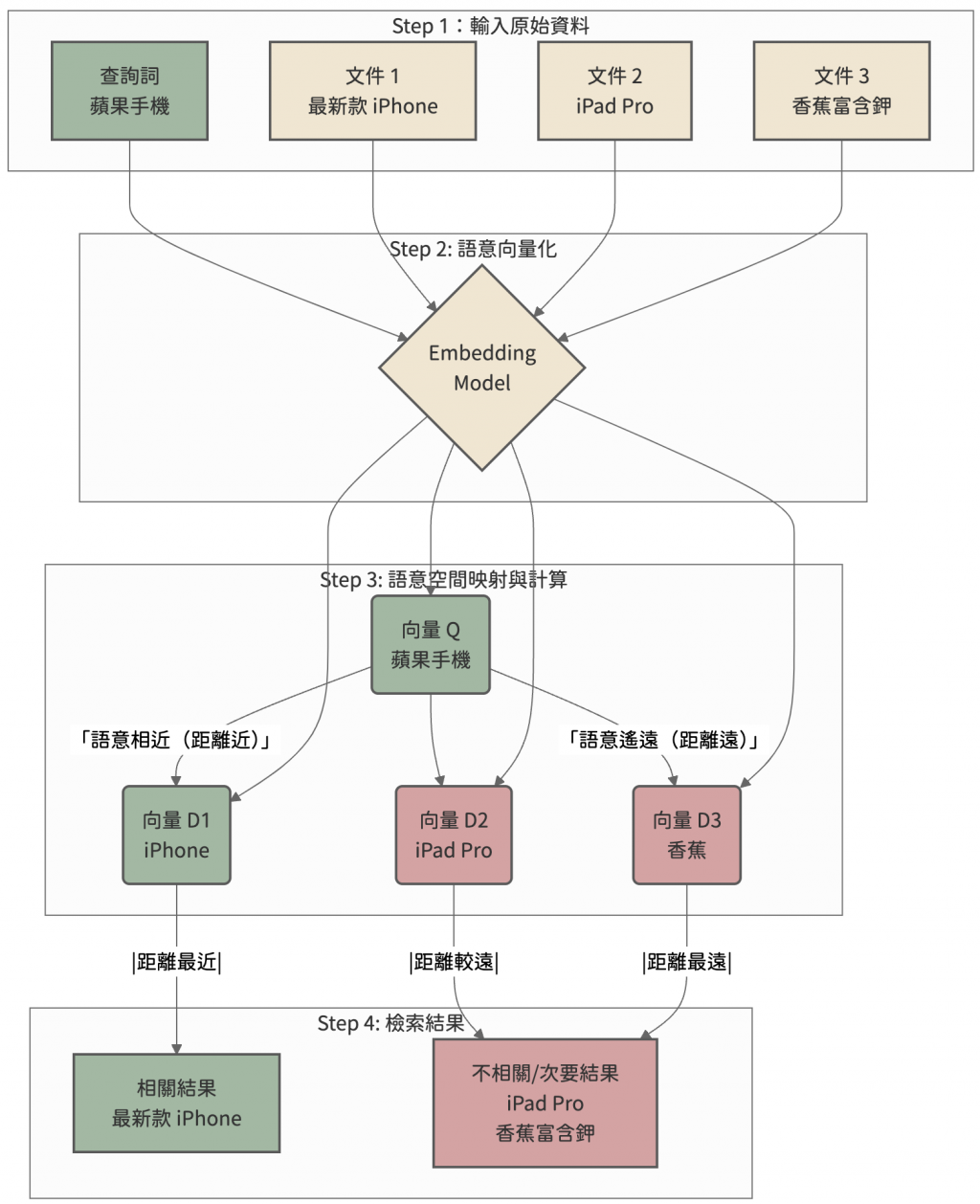
向量檢索的優勢是能夠捕捉人類語言的深層語意,對於查詢中的變體、同義詞、甚至口語化表達,都能展現出良好的容忍度,不再受限於關鍵字必須精確匹配
此外不只文字,他的圖片相似度搜尋、語音內容識別等跨模態的搜尋也是基於向量化技術實現的,所以很適合作為一個基石,從海量資料庫中找出與使用者問題最相關的上下文資訊。
儘管向量檢索如此優異,但關鍵字檢索依然扮演著不可或缺的角色,我們會使用他的精確與直觀性,作為向量檢索的補充,強強相加一起建構出更全面的檢索系統。
關鍵字檢索的重點是字面匹配,他不需要理解詞彙的深層語意,只要專注在「這些詞句出現在哪裡?」即可,通常包含以下技術:
總的來說,關鍵字檢索的強項在於它能夠迅速、準確地找出使用者指定的詞彙
大家都聽過這句至理名言:「小孩子才做選擇,我全都要」,所以我們透過混合檢索,將向量跟關鍵字整合在一起,彼此相輔相成。
關鍵字檢索負責提供精確的字面匹配結果,確保重要的專有名詞和關鍵詞不會被遺漏;而向量檢索則負責捕捉查詢的語意廣度,提升檢索的召回率和對查詢意圖的理解。這樣就能在精確性與召回率之間找到最佳平衡。
召回率:在所有真正相關的項目中,我們的系統成功找回了多少比例。 簡言之,它評估的是檢索系統沒有錯過的能力,此數值愈高愈好。
使用 Rewrite 將人類的話改成檢索專用的話語,並用 Retrieve 進行篩選,最後將交給 LLM 閱讀、消化這些上下文。我們通常會提出以下需求,這部分前面有提過,我這邊就快速再統整一次:
R3 框架把職責拆分得很清楚,整個框架也環環相扣,並將海量資料一層一層的進行篩選:


 iThome鐵人賽
iThome鐵人賽