單純的 Retrieve → Read (Naive RAG) 架構在初期導入時,確實能快速看到成效,從使用者提問、系統檢索文件、到透過大型語言模型生成答案。整個流程直觀且容易上線。然而,隨著應用深入,很快就會發現失敗案例大多源於一個根本問題,就是使用者說的話太模糊、指令不清楚
例如,當使用者輸入幫我分析 AI 晶片最新發展時,模型可能只會給出教科書式的基礎知識,或是隨機拼貼幾個不完全相關的段落。這並非檢索器或 LLM 不夠強大,而是因為輸入的自然語言本質上不適合直接用於機器檢索
人類比較習慣用自然語言表達模糊、概括性的需求,但檢索器需要的是結構化、明確且可執行的查詢指令。為了解決這個問題,我們可以將流程向前延伸一步,加入了 Rewrite 環節 (原本只有 Retrieve → Read)
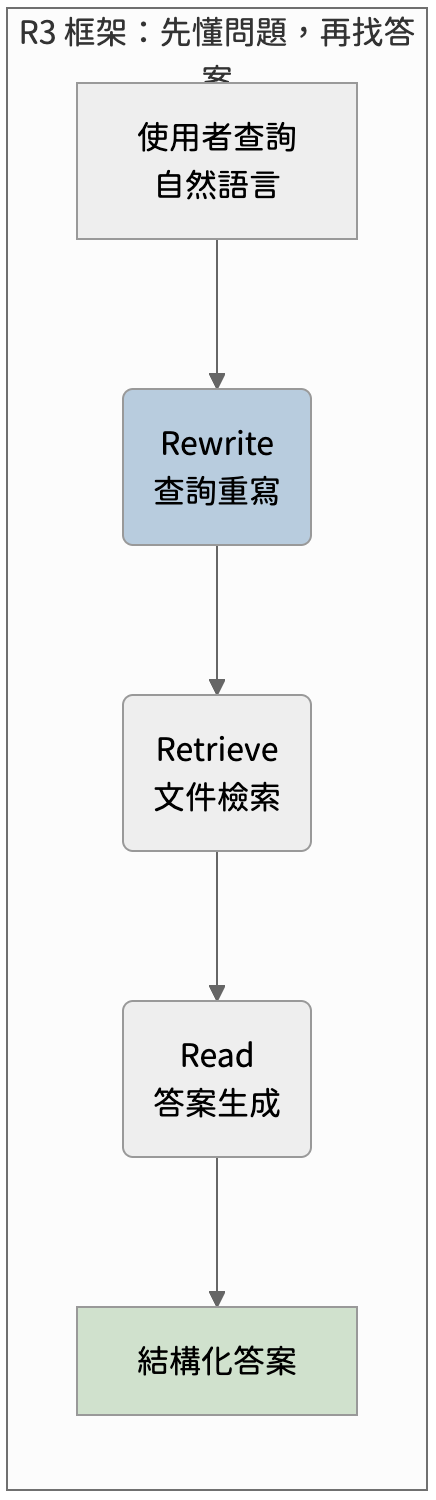
我們可以將 Rewrite 想成是 API Gateway 的請求預處理器,將使用者輸入的高自由度的人話,轉成後端檢索器、重排器和閱讀器都能夠穩定處理的標準化 payload
如果你曾導入過 RAG 系統,以下這些問題想必不陌生。這些問題都共同指向一件事:查詢本身需要被精心設計。而 R3 框架正是將查詢設計這件事系統化。


 iThome鐵人賽
iThome鐵人賽