我們在前面談過上下文的容量限制與策略設計,提到 Token 限制是大型語言模型不可違背的規則。當對話越聊越長,或者多個使用者同時和 AI 互動時,如果沒有好的記憶管理,AI 要嘛忘東忘西,要嘛被過多資訊干擾。這就像工程師寫程式卻不做垃圾回收,最終整個應用程式的效能將會崩潰。
那麼,對話歷史要怎麼保存?保留多少才有價值?什麼該存、什麼該丟?這篇文章我會從工程實作角度,談談對話歷史的管理與壓縮策略,並結合一些實務範例與 Prompt 設計。
先講一個殘酷的事實:全部保留是不可能的。這背後的原因主要有三點:
因此,關鍵問題不是能儲存多少?而是該儲存什麼?
最值得保存的通常是以下三類資訊:
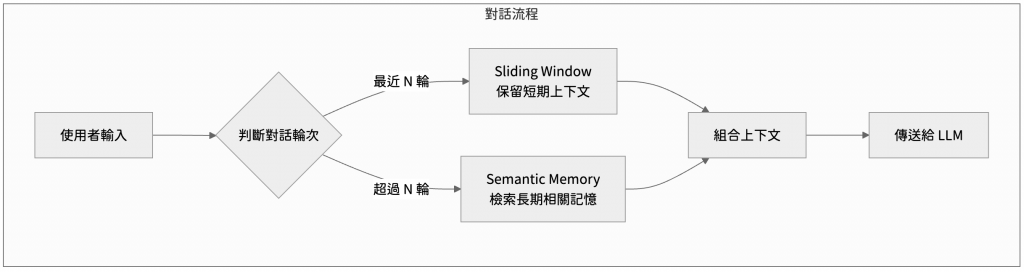
為了有效管理對話歷史,業界發展出兩種主流策略:滑動視窗和語義記憶
這是最常見的方法,概念非常簡單:只保留最近 N 輪的對話,更早的歷史紀錄則直接拋棄。
另一種是語義記憶,它會將歷史對話轉換為嵌入式向量存入向量資料庫。當有新的對話產生時,系統會檢索並拉回語義上最相關的記憶片段,這讓模型不必費力消化所有內容,而是能動態喚起相關的長期記憶
優點:能夠跨越時間限制,保留重要的長期資訊
缺點:實作複雜度較高,需要額外的檢索步驟,可能增加延遲
適合場景:
實務上最有效的方法通常是兩者混合使用,模擬人腦的記憶模式:
這就像人腦一樣:短期記憶處理當下事務,反應快但容量有限;長期記憶則能持久保存重要知識,需要時再提取
如果直接把完整的歷史對話存進向量資料庫,成本和雜訊問題依然存在。因此,更常見的做法是先進行摘要,再進行向量化
例如這段原始對話:我們昨天深入討論了下個月產品發表會的詳細流程,其中包括簡報的視覺設計風格、主持人需要用到的腳本,以及預先規劃的 Q&A 問答環節
做成摘要版本後變成:「主題:產品發表會流程;細節:簡報設計、主持人腳本、Q&A 規劃」
我們存入資料庫的是這個濃縮後的關鍵描述,而非完整的對話紀錄。以下是一個可以用來自動生成摘要的提示詞範例:
你是一個專業的對話紀錄整理器。
請將以下對話濃縮為 3 句以內的摘要,只保留與核心任務相關的資訊,並徹底去除所有寒暄、口頭禪與無關的細節。
# 對話內容:
使用者:嗨,我們昨天好像有討論到那個產品發表會的流程,對吧?我想確認一下,我們是不是有提到簡報設計、主持人腳本,還有那個 Q&A 的部分?
AI:是的,您好。根據紀錄,我們昨天確認了這三個主要項目。我會優先幫您整理簡報設計部分的重點。
# 輸出格式:
- 主要主題:
- 次要細節:
- 未解決問題:
一個完整的記憶系統包含資料庫設計、檢索演算法與壓縮策略
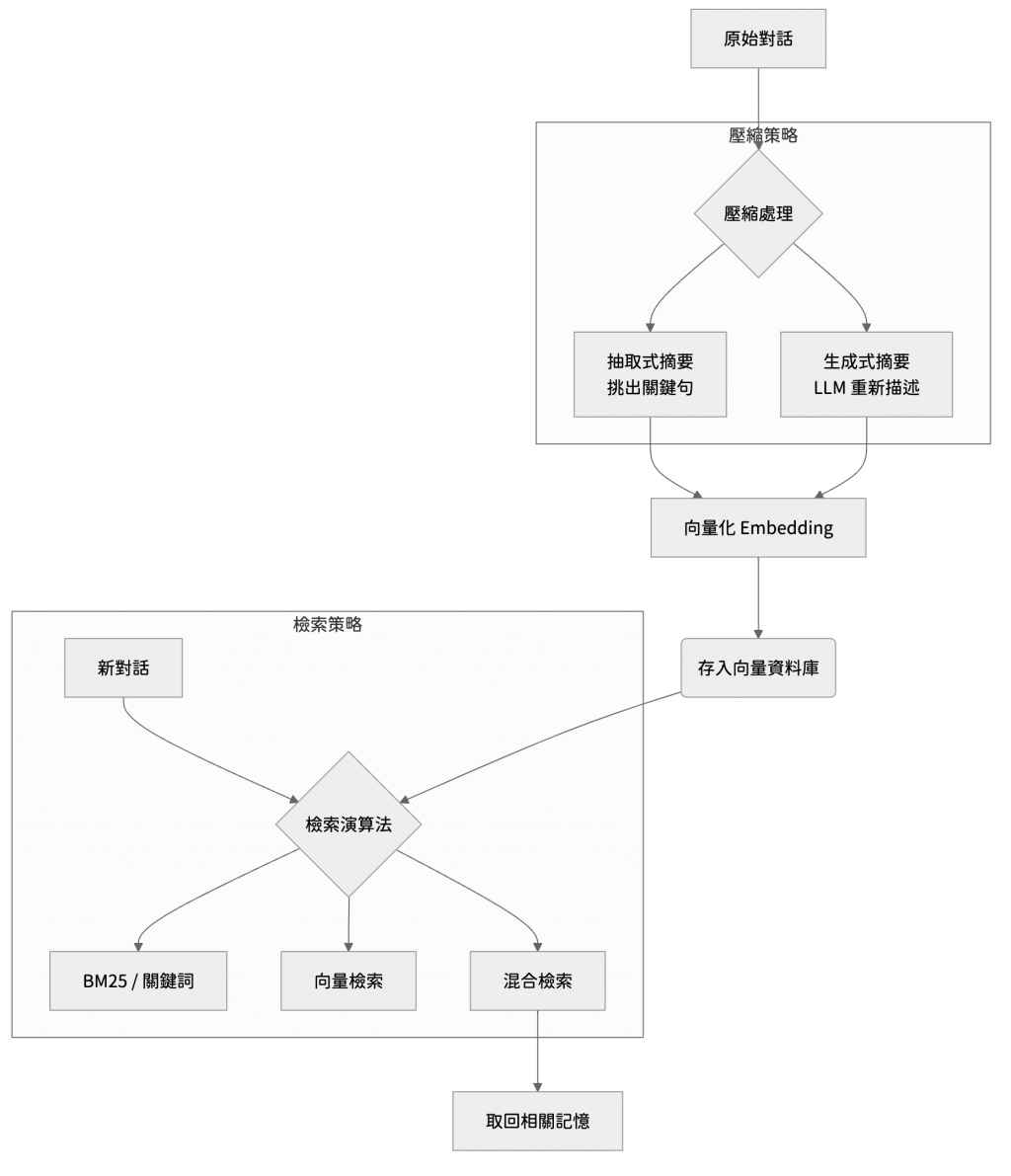
一個簡單但實用的資料庫 Schema 可以這樣設計,以支援多種查詢方式:
{
"id": "uuid-1234-abcd-5678",
"timestamp": "2025-10-05T12:30:00Z",
"summary": "討論產品發表會流程,包含簡報設計、主持人腳本與 Q&A。",
"embedding": [0.12, 0.45, -0.08, ...],
"tags": ["meeting", "product-launch", "event-planning"],
"source_conversation_id": "conv-xyz"
}
這樣的結構能同時支援語義、篩選時間並過濾主題
建議保留最近 5 輪對話,捨棄更早的紀錄,因為客服對話通常是單一、短期的任務,使用者不太會提及數天前的問題。此策略簡單快速,適合高併發的場景
保留最近 10 輪的完整上下文,並在每次對話結束後,生成摘要並存入向量資料庫,這樣當員工再次詢問「上次會議是誰決定了最終的產品價格?」時,系統可以透過語義檢索,準確找到相關的會議摘要並回答。
將程式碼的上下文拆分成更小的區塊,例如函式、類別或模組,只保存與使用者當前編輯位置最相關的程式碼區塊。這部分要注意的是如何準確切分程式碼,並確保檢索到的上下文邊界是完整且正確的
對話歷史管理的本質,已經從盡力儲存進化到只存對的東西,Sliding Window 幫我們保住了短期上下文,Semantic Memory 則讓我們提取長期知識


 iThome鐵人賽
iThome鐵人賽