
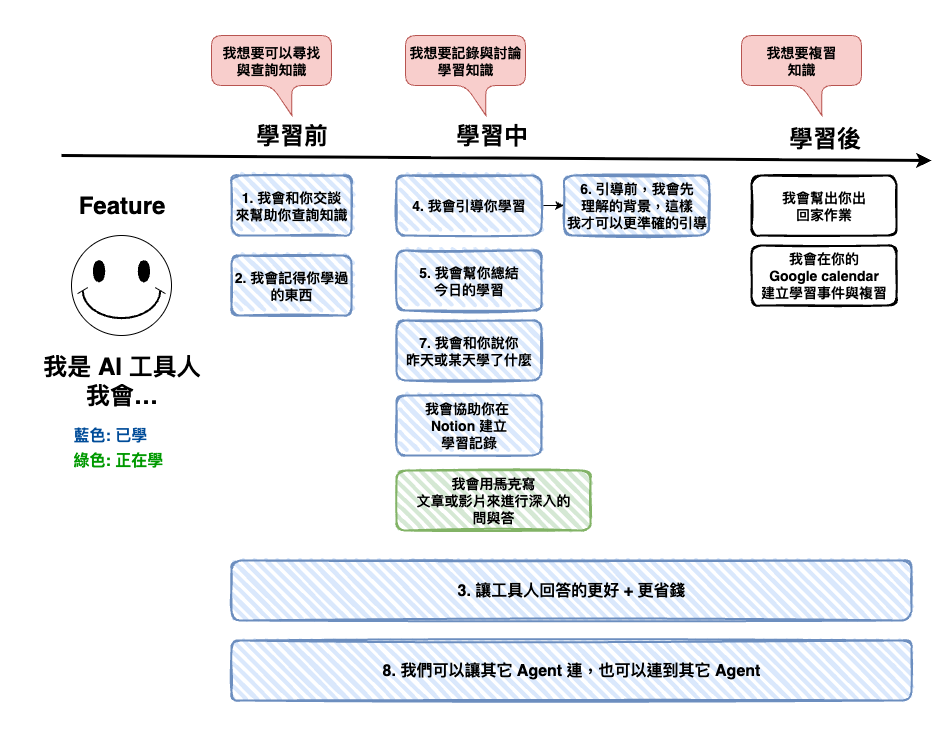
上一篇文章中,我們用最簡單的 Native RAG 來實作出這個功能以後,接下來我們將來幫他升級一下。
根據之前這張圖,我們事實上可以知道 Native RAG 與 Advanced RAG 的差別在於,後者增加了以下兩個階段 :
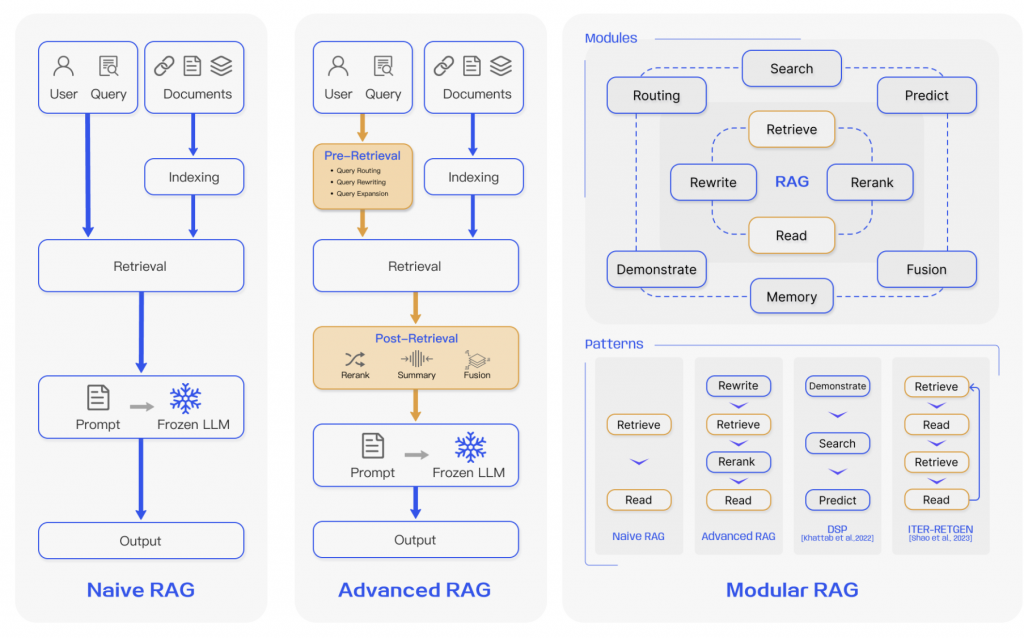
Pre-Retrieval + Post-Retrieval,然後這篇文我們要專注在 Pre-Retrieval
Pre-retrieval process. In this stage, the primary focus is on optimizing the indexing structure and the original query. The goal of optimizing indexing is to enhance the quality of the content being indexed. This involves strategies: enhancing data granularity, optimizing index structures, adding metadata, alignment optimization, and mixed retrieval. While the goal of query optimization is to make the user’s original question clearer and more suitable for the retrieval task. Common methods include query rewriting query transformation, query expansion and other techniques [7], [9]–[11].
根據這篇 Retrieval-Augmented Generation for Large Language Models: A Survey 論文中,提到 Pre-retrieval 的過程中,核心的優化手法有兩個,以下是純英文轉中文 :
優化索引結構 ( Index ) : 索引優化的目標是提升被索引內容的品質。常用策略包括:提升資料粒度、優化索引結構、加入中繼資料( metadata )、對齊優化,以及混合式檢索。優化原始查詢 ( Query ) : 目標是讓使用者的原始問題更清晰、且更適合檢索任務。常見方法包括查詢改寫與查詢轉換。看了一下優化索引結構的部份,其它資料粒度應該就是我們說的 chunking 相關的東西,而 metadata 這個會影響到之後我們也可以用它來進行檢索的東西,然後現在這樣看來,我們上一篇文章事實上已經有做到一些 Advanced RAG 的東西了……
30-21: [實作-10] 用字幕檔實作 AI 課程問答功能 - Native RAG + MongoDB Atlas
論文中提到的 Query 優化手法 :
論文中提到的 Index 優化手法 :
接下來我們就根據上面的東西,來優化優化看看,但不太可能每個都試看看,因為有些不太適合我們這個情境。
我們會用原始的問題,生成多個問題,為了增加查詢的多樣性與覆蓋面,你想想有沒有可能你只用第一個問題查詢,會沒有你要的結果呢。
!!! 注意這裡的程式碼是單一使用 Query Expansion 的範例,我們越往下優化,會合併起來
🤔 主要產生多個問題的程式碼部份,我們這裡就是請 LLM 產生
private async generateMultiQueries(
originalQuery: string,
numQueries: number = 3
) {
const prompt = `你是一個查詢擴展專家。請根據用戶的原始問題,生成 ${numQueries} 個語義相似但表達方式不同的問題變體。
原始問題: ${originalQuery}
## Instructions:
- 每個變體應該保持原問題的核心意圖
- 使用不同的措辭和表達方式
- 涵蓋不同的角度和細節層次
- 只輸出問題,每行一個,不要編號
變體問題:`;
const result = await this.llm.invoke([
{
role: "user",
content: prompt,
},
]);
const queries = result.content
.toString()
.split("\n")
.map((q) => q.trim())
.filter((q) => q.length > 0);
return [originalQuery, ...queries];
}
🤔 接下來進行 retrieve 的地方,它就是會 retrieve 多次,然後在合併+排序+取 k 個
async retrieve(
originalQuery: string,
k: number = 5
): Promise<
{
pageContent: string;
metadata: any;
score: number;
}[]
> {
const queries = await this.generateMultiQueries(originalQuery, k);
const allResults = new Map<string, any>();
for (const query of queries) {
const results = await this.vectorStore.similaritySearchWithScore(
query,
k
);
for (const result of results) {
const [doc, score] = result;
const docId = doc.metadata.utt_id;
if (!allResults.has(docId)) {
allResults.set(docId, { doc, totalScore: 0 });
}
allResults.get(docId).totalScore += score;
}
}
const finalResults = Array.from(allResults.values())
.sort((a, b) => b.totalScore - a.totalScore)
.slice(0, k);
return finalResults.map((result) => {
return {
pageContent: result.doc.pageContent,
metadata: result.doc.metadata,
score: result.totalScore,
};
});
}
🤔 最後使用的地方
const query = async (message: string) => {
const retriever = new MultiQueryRetriever();
const contexts = await retriever.retrieve(message);
console.log(contexts);
const model = new ChatOpenAI({
modelName: "gpt-5-mini",
});
const result = await model.invoke([
{
role: "system",
content: `
# Context: ${contexts
.map((context) => {
return JSON.stringify({
content: context.pageContent,
startAt: context.metadata.start_ms,
endAt: context.metadata.end_ms,
});
})
.join("\n")}
# Additional & Limit:
- 你只能根據 Context 回答相關的問題,並且說明答案的來源時間範圍
- 時間範圍格式為 "MM:SS~MM:SS"
- 限制在 300 個字以內
`,
},
{ role: "user", content: message },
]);
console.log(result);
};
(async () => {
await query("為什麼要用 RAG 呢?");
})();
這裡總共有三種手法
以下三種手法的概念圖如下 :
// Query Rewriting (查詢重寫) =============================================
// 原始查詢 (可能不清晰、有歧義)
"llm 記憶體不夠怎麼辦"
↓ Query Rewriting ↓
// 重寫後 (更精確、更標準)
"如何優化大型語言模型的記憶體使用和處理記憶體限制問題"
// HyDE ( Hypothetical Document Embeddings ) ================================
// 原始查詢
"為什麼要用 RAG?"
↓ HyDE ↓
// 生成假設性答案
"RAG 結合了檢索和生成的優勢,能有效減少大型語言模型的幻覺問題..."
↓ 用假設答案檢索 ↓
// 重點: 答案對答案的 embedding 相似度
// 而非問題對答案
// Step-back Prompting ========================================================
// 原始查詢 (具體問題)
"GPT-4 Turbo 的 token 限制是多少?"
↓ Step-back ↓
// Step-back 問題 (高層次概念)
"大型語言模型的 token 限制機制是什麼?"
↓ 檢索 ↓
// 同時用兩個問題檢索
// 1. 原始問題 → 找具體答案
// 2. Step-back 問題 → 找背景知識
🤔 那這裡我們要像大人一樣全都要嗎 ?
我們今天這裡只用 HyDE ( Hypothetical Document Embeddings )
因為在我們這個情境下,教學影片的字幕通常是講者在「回答問題」或「解釋概念」,然後更準確的說可以想成是去字幕找到對應的答案,所以以這種情境來說,我們用 HyDE 先產出答案後,再去字幕找答案,會更準確。
但我們都有答案了,還需要 RAG 嗎 ? 要,因為在我們不能確保 LLM 直接的答案是對的,或是符合課程當初自課時回答時空那時的答案 ( 當然也會另外在補充說現在時空的答案,給學習者知道隨這時間改變,答案也已經改變了 )
而至於 Step-back Prompting 這個方法我們比較適用在整個課程的問與答上,因為課程是有結構的,但我們現在這個實作是單一章節的,所以這裡就先不實作囉 ~~
最後由於 Query Rewriting,我自已是覺得我們都有實作 Query Expansion 感覺應該這個部份的優化效果會比較少。
🤔 程式碼新增的地方
!!! 這裡有加上 Query Expansion
這裡先說一下,我們本來的想法是 :
先用 Query Expansion 後,再將每個產生的 Query 都再用 HyDE
但是後來想了一下,還有與 AI 討論後,決定先用 :
Orign 進行 HyDE 後的結果 + Query Expansion 後的結果 => 最後再抓 Top K 個結果
主要的原因還是在於成本太高,雖然可能成果比較好,但 CP 值沒有很好,所以這裡決定先嘗試實作上面這種方式。
然後下面就是實作的部份,應該是很好懂。
/**
* 混合檢索:Query Expansion + HyDE (分數加總版本)
*/
async retrieve(
originalQuery: string,
k: number = 5
): Promise<
{
pageContent: string;
metadata: any;
score: number;
}[]
> {
// 1. Query Expansion: 生成查詢變體
const variantQueryies = await this.generateMultiQueries(originalQuery, 2);
// 2. HyDE: 只對原始查詢生成假設答案
const hypotheticalAnswer = await this.generateHypotheticalAnswer(
originalQuery
);
// 3. 準備所有檢索查詢
const searchQueries = [originalQuery, ...variantQueryies, hypotheticalAnswer];
// 4. 對每個查詢執行檢索
const allResults = new Map<
string,
{
doc: any;
score: number;
}
>();
for (const query of searchQueries) {
const results = await this.vectorStore.similaritySearchWithScore(
query,
k
);
for (const result of results) {
const [doc, score] = result;
const docId = doc.metadata.utt_id;
if (!allResults.has(docId)) {
allResults.set(docId, { doc, score: 0 });
}
allResults.get(docId)!.score += score;
}
}
// 5. 排序並返回 top-k
const finalResults = Array.from(allResults.values())
.sort((a, b) => b.score - a.score)
.slice(0, k);
return finalResults.map((result) => ({
pageContent: result.doc.pageContent,
metadata: result.doc.metadata,
score: result.score,
}));
}
/**
* HyDE: 生成假設性答案(只對原始查詢)
*/
private async generateHypotheticalAnswer(query: string): Promise<string> {
const prompt = `你是一位經驗豐富的線上課程講師,正在錄製教學影片。現在有學生問了以下問題,請用自然、口語化的方式回答,就像你在影片中講解一樣。
學生問題: ${query}
## Instructions:
- 使用口語化、自然的表達方式(可以用"那個"、"然後"、"其實"、"嗯"等口語詞彙)
- 像在教學一樣循序漸進地解釋,不要太正式或太書面化
- 包含關鍵概念和實際的解釋
- 長度控制在 100-200 字
- 如果涉及技術概念,要解釋得清楚易懂
- 可以舉簡單的例子或類比
講師的口語化回答:`;
const llm = new ChatOpenAI({
modelName: "gpt-4o-mini",
temperature: 0.7,
});
const result = await llm.invoke([
{
role: "user",
content: prompt,
},
]);
const answer = result.content.toString().trim();
console.log("\n[HyDE] 生成的假設答案:");
console.log(
` ${answer.substring(0, 150)}${answer.length > 150 ? "..." : ""}`
);
return answer;
}
它的概念圖有點像這樣,這個事實上在整個 Agentic AI 體系實作上很常見,也是被公認很有效的方法,因為要在一個地方處理所有情境太複雜,也太困難了。
用戶查詢
↓
Query Router (分類器)
↓
┌───┴───┬───────┬────────┐
↓ ↓ ↓ ↓
事實型 概念型 操作型 其他
↓ ↓ ↓ ↓
直接 HyDE Multi Standard
檢索 Query
然後實作上我們是會像之前一樣建一個 Route 然後再來決定去用那個方法來處理。
class QueryRouter {
private llm: ChatOpenAI;
constructor() {
this.llm = new ChatOpenAI({
modelName: "gpt-4o-mini",
temperature: 0, // 分類任務需要確定性
});
}
/**
* 分類查詢類型
*/
async classify(query: string): Promise<QueryClassification> {
const prompt = `你是一個查詢分類專家。請分析用戶的查詢並判斷其類型。
用戶查詢: ${query}
## 查詢類型定義:
1. **factual** (事實型): 尋找具體的事實、數據、名稱、時間等
- 範例: "OpenAI 的 GPT-4 有多少參數?"、"RAG 是什麼意思?"
2. **conceptual** (概念型): 理解原理、概念、為什麼
- 範例: "為什麼要用 RAG?"、"Transformer 的原理是什麼?"
3. **procedural** (操作型): 如何做某事、步驟、教程
- 範例: "如何實作 RAG?"、"怎麼優化向量檢索?"
4. **comparative** (比較型): 比較多個選項、優缺點
- 範例: "RAG 和 Fine-tuning 的差異?"、"哪個 embedding 模型更好?"
5. **exploratory** (探索型): 開放式、廣泛的探索
- 範例: "RAG 的最佳實踐有哪些?"、"告訴我關於向量資料庫的一切"
## 請以 JSON 格式回答:
{
"type": "查詢類型 (factual/conceptual/procedural/comparative/exploratory)",
"confidence": 信心度 (0-1之間的數字),
"reasoning": "判斷理由 (簡短說明)"
}
只輸出 JSON,不要其他內容:`;
const result = await this.llm.invoke([
{
role: "user",
content: prompt,
},
]);
const response = result.content.toString().trim();
// 移除可能的 markdown 代碼塊標記
const jsonStr = response.replace(/```json\n?/g, '').replace(/```\n?/g, '').trim();
const classification = JSON.parse(jsonStr);
return {
type: classification.type as QueryType,
confidence: classification.confidence,
reasoning: classification.reasoning,
};
}
然後使用上大概就如下:
// 1. 查詢分類
const router = new QueryRouter()
const classification = await this.router.classify(query);
switch (classification) {
case "direct":
results = await this.directRetrieval(query, k);
break;
case "hyde":
results = await this.hydeRetrieval(query, k);
break;
case "multi-query":
results = await this.multiQueryRetrieval(query, k);
break;
case "hybrid":
results = await this.hybridRetrieval(query, k);
break;
default:
results = await this.directRetrieval(query, k);
事實上我們在上一篇文章中,有處理了以下兩個部份 :
其中 Chunking 主要是這一塊,然後我們的處理手法的業務規則是 :
🤔 Chunking
如果字幕片段太短 (少於 3 秒或 8 字)、或跟下一句幾乎連在一起(間隔不到 1 秒),就合併起來變成一段完整的話,目標抓 8-12 秒,最多不超過 20 秒。
不過事實上這個不是最優解,之後有時間再來嘗試用Small2Big 這個東西來處理看看,這篇有點太長了。
/**
* 合併片段
*/
static mergeSegments(
segments: SRTSegment[],
options: {
minDuration?: number; // 最小片段時長 (ms)
minChars?: number; // 最小字數
maxGap?: number; // 最大間隔 (ms)
targetDuration?: number; // 目標時長 (ms)
maxDuration?: number; // 最大時長 (ms)
} = {}
): SRTSegment[] {
const {
minDuration = 3000,
minChars = 8,
maxGap = 700,
targetDuration = 8500,
maxDuration = 20000,
} = options;
const merged: SRTSegment[] = [];
let current: SRTSegment | null = null;
for (let i = 0; i < segments.length; i++) {
const segment = segments[i];
const nextSegment = segments[i + 1];
if (!current) {
current = { ...segment };
continue;
}
// 計算間隔
const gap = segment.start_ms - current.end_ms;
const currentChars = current.text.length;
const wouldBeDuration = segment.end_ms - current.start_ms;
// 判斷是否應該合併
const shouldMerge =
(current.duration_ms < minDuration ||
currentChars < minChars ||
gap <= maxGap) &&
wouldBeDuration <= maxDuration;
if (shouldMerge) {
// 合併
current.text += "\n" + segment.text;
current.end_ms = segment.end_ms;
current.duration_ms = current.end_ms - current.start_ms;
} else {
// 儲存當前,開始新的
merged.push(current);
current = { ...segment };
}
// 如果已達目標時長且不是最後一段,考慮結束合併
if (current.duration_ms >= targetDuration && nextSegment) {
const nextGap = nextSegment.start_ms - current.end_ms;
if (nextGap > maxGap) {
merged.push(current);
current = null;
}
}
}
// 加入最後一段
if (current) {
merged.push(current);
}
return merged;
}
🤔 Metadata
我們事實上也有在資料庫中,在每個 Chunk 都有儲放 metadata,這個在之後我們可以用它來進行 multi query。
const client = new MongoClient(MONGODB_URI);
const collection = client.db(DATABASE_NAME).collection(COLLECTION_NAME);
const embeddings = new OpenAIEmbeddings({
modelName: "text-embedding-3-small",
});
const vectorStore = new MongoDBAtlasVectorSearch(embeddings, {
collection,
indexName: VECTOR_INDEX_NAME,
textKey: "text",
embeddingKey: "embedding",
});
const indexing = async () => {
const srtContent = fs.readFileSync("./test.srt", "utf-8");
const processed = SRTProcessor.process(srtContent, "30-21");
for (const item of processed) {
await vectorStore.addDocuments([
{
pageContent: item.text_clean,
metadata: item,
},
]);
}
};
今天寫到現在,真的發現到了今天,我才開始有在深入 RAG 的東西,不然後之前就再想,那個感覺很簡單,但實際上看了每個優化手法,發現他的水很深啊……
明天將要來進行 Post-Retrieval 的研究。
