「AI 模型知道的,不一定是你想要的。」
這句話完美說明了為什麼 RAG(Retrieval-Augmented Generation)
會成為 2024 年後企業導入 AI 的核心技術之一。
大型語言模型(LLM)非常聰明,
但它有兩個天生限制:
知識是固定的:
模型的知識來自訓練資料,更新緩慢。
想讓它學新東西,只能重訓(成本高、效率低)。
回答可能「看似正確」但其實錯誤:
這種現象叫 幻覺(Hallucination)。
模型會根據語意邏輯「編」出合理但錯的答案。
這時,RAG 就登場了——
讓 LLM 在回答之前,先去查「真實資料庫」,
再根據找到的內容生成答案。
RAG(Retrieval-Augmented Generation)
直譯為「檢索增強生成」。
它的核心思想是:
讓 AI 模型在生成答案前,
先從外部知識庫中找出與問題相關的內容,
再根據檢索結果生成最終回覆。
這樣模型回答的依據不再只是訓練數據,
而是最新、最真實、最可控的知識來源。
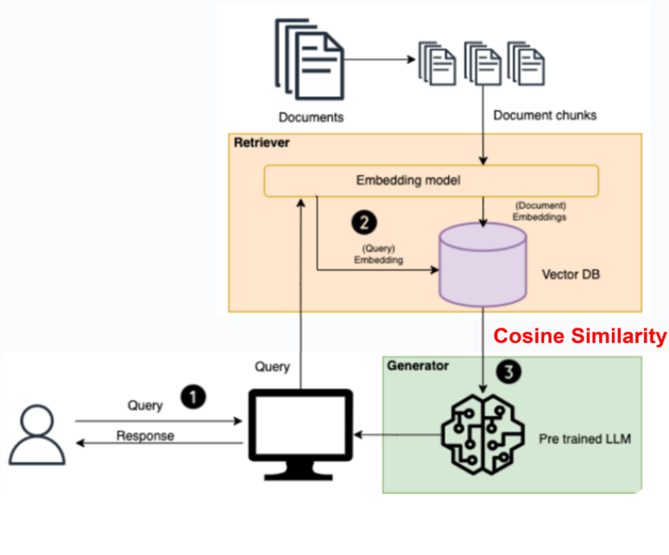
說明:
使用者輸入查詢(Query)
→ 系統接收問題,並準備檢索相關資料。
Retriever 模組:
將使用者的 Query 經由 Embedding 模型 轉成向量,
與知識庫中已向量化的文件(Document Embeddings)
進行 餘弦相似度(Cosine Similarity) 比對,
找出最相關的幾段文件。
Generator 模組(LLM):
將「使用者問題 + 檢索內容」整合後交給語言模型(如 GPT、Ollama、Claude)。
模型根據上下文生成更準確、有依據的回答。
| 步驟 | 名稱 | 功能 | 技術重點 |
|---|---|---|---|
| ① | 資料向量化 (Embedding) | 將文字轉換為可比較的數值向量 | 使用 OpenAI Embedding、Ollama Embedding 等 |
| ② | 相似度檢索 (Retrieval) | 找出與問題最接近的內容片段 | 使用 Vector DB(如 Qdrant、PgVector、Redis) |
| ③ | 生成 (Generation) | 將檢索到的內容放進 Prompt,請模型生成答案 | 結合 Chat 模型(OpenAI、Ollama、Claude...) |
| 類型 | 應用說明 | 實例 |
|---|---|---|
| 知識型問答 | 使用內部文件回答問題 | 企業文件助理、法規查詢系統 |
| 文件摘要 | 根據檔案內容自動生成重點 | 研究報告摘要、自動會議紀錄 |
| 客戶支援系統 | 回答 FAQ、產品說明 | 智慧客服中心 |
| 程式文件助理 | 根據專案文件提供 API 說明 | DevOps 文件查詢 |
| 私有資料查詢 | 保留資料安全,避免外洩 | 本地 Qdrant + Ollama 架構 |
| 項目 | 傳統 LLM | RAG 模型 |
|---|---|---|
| 資料來源 | 模型訓練時的內建知識 | 即時檢索的外部文件 |
| 回答依據 | 憑語意生成(可能誤) | 有文件依據(可引用) |
| 更新方式 | 需重新訓練模型 | 只需更新知識庫 |
| 準確度 | 易產生幻覺 | 更具可驗證性 |
| 成本 | 高 | 中等(可用本地模型) |
| 優勢 | 挑戰 |
|---|---|
| 回答更準確,能引用文件依據 | 需設計良好的資料切分策略 |
| 知識可動態更新 | 向量資料庫維運成本 |
| 適合企業應用(文件、FAQ、內部系統) | 若檢索品質差,仍會出錯 |
| 不需重新訓練模型 | Embedding 成本與延遲需考量 |


 iThome鐵人賽
iThome鐵人賽