我們昨天用 workflow 架構了我們的 Baseline RAG,並且跑出了對應的回答
我們今天有三個需求:
我們昨天有跑出兩份答案,一份是把 retriever 的 top-k 設成 3,另一份是把 top-k 設成 8
我們分別對兩份答案使用 correctness evaluator 計算 correctness score
來人,我們上圖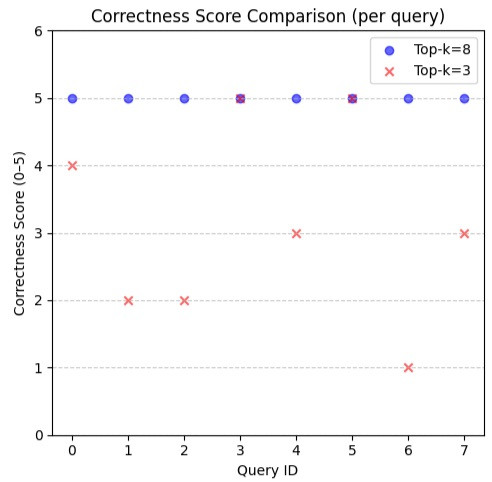
x 軸是 query 的 id, y 軸是對應的 Correctness score (1-5) 越高越好
可以看到 top-k=8 的版本 (藍色圓點) 都給出了 5 分滿分
而 top-k=3 的版本:
由於題數不多,我們人工確認過,top-k=8的答案都是正確答案,而 top-k=3 除了滿分題以外,都是錯誤的
這反映了我們先前的直覺,由於 llm 傾向於給出部分分數,所以就算答的不好 correctness 也不會直接是最低分
但以產品角度來說,我們的階段性目標確實應該設為大部分都要給出滿分評價,少部分沒有滿分的是 corner 或者 fail case
最後我們給出 rag pipeline 的單一數值指標,就是把所有題目的 correctness 取平均
top-k=8: 5.0
top-k=3: 3.125
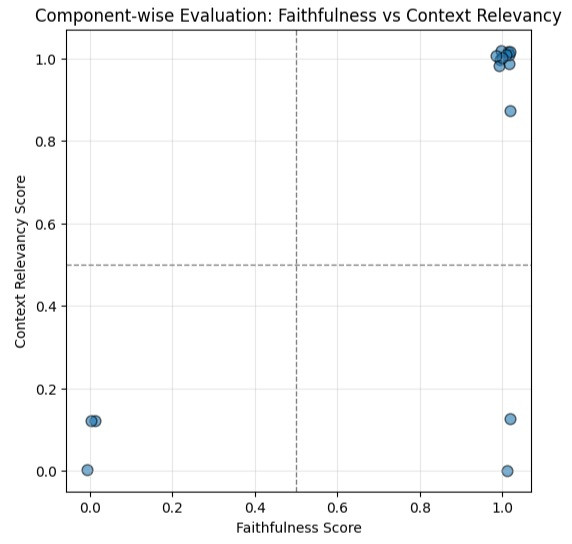
我們先看一下這張圖的四個象限代表著什麼:
我們接著分開看看是 topk=3 的問題還是 topk=8 的問題:
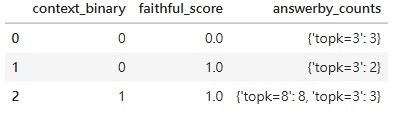
最後我們檢查當 faithful_score 跟 context_binary 都是 1 的時候,我們 correctness 的分數: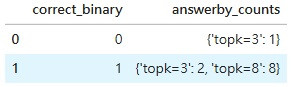
它的原始回答在:這裡
"1) 是否與使用者問題主題相符?
評估:是,相符(2/2)
回饋:檢索到的內容主要在說明作業的規劃與繳交期限,包含「每一個作業基本上都留給大家三週的時間來完成」、「前兩個作業截止日延後到10月17日」及「最後一個作業截止日為明年1月9日」等明確時程資訊,這直接對應到使用者在詢問「課程中保留多少時間給作業/需要訓練的作業」這類與作業時程有關的問題。
2) 檢索到的內容能否單獨用來完整回答使用者問題?
評估:可以(2/2)
回饋:文中明確指出「基本上的每一個作業…都是留給大家三週的時間來完成」,這足以直接回答「每個作業保留多少時間」的問題。另外也列出例外(前兩個作業延後到10月17日、最後一個作業截止在1月9日),因此該段內容可單獨用來完整回應使用者對於作業所保留時間的詢問。說明:若使用者特別指「需要訓練(training)時間」為某類技術性訓練或模型訓練的具體運算時長,文中並無提及,但就作業可用時間(可完成期限)而言,檢索內容已足夠。
總分:4.0
[RESULT] 4.0"
answer relevancy,他做的事情是直接 prompt llm 回答 這個 答案有沒有回答到使用者的問題
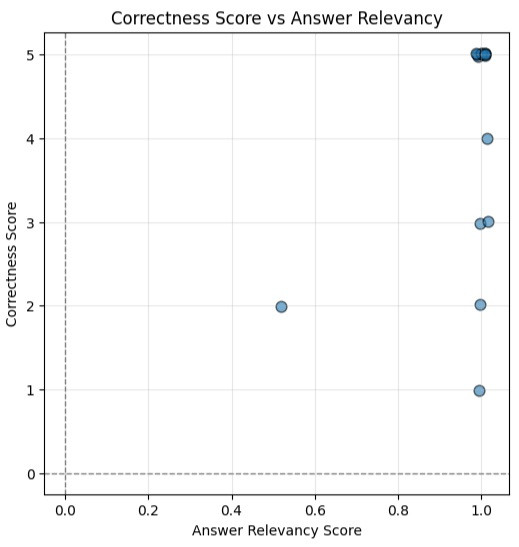
那什麼適合作為沒有 reference_answer 情況下 correctness 的 proxy 呢?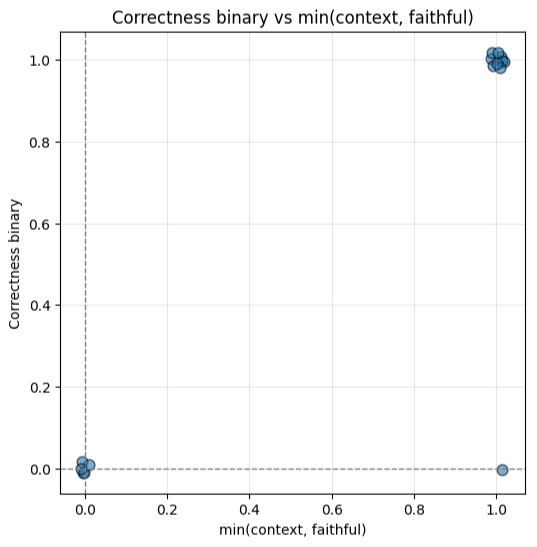


 iThome鐵人賽
iThome鐵人賽