在正式進入案例實作先來聊聊關於進入機器學習, 個人除了演算法理論之外所學到幾件事情:
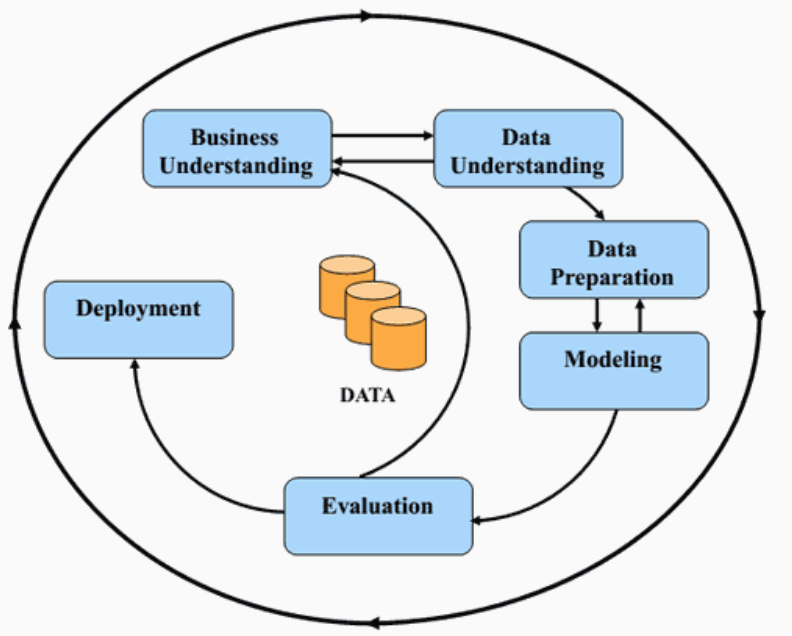
個人覺得這樣流程其實也是適用於在機器學習處理流程, 此外Microsoft在自己推廣的DAT213x Analyzing Big Data with Microsoft R課程裡, 也提出類似的處理流程如下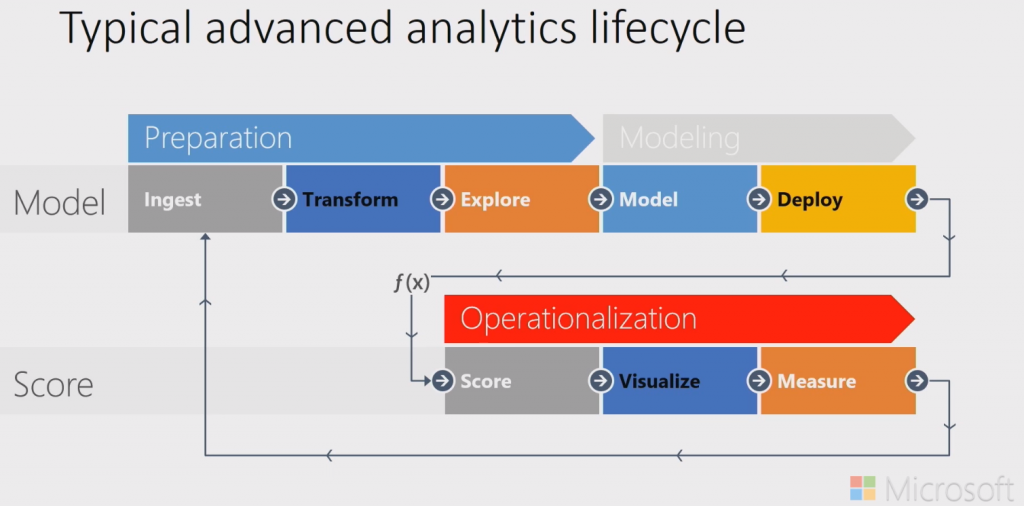
https://www.youtube.com/watch?v=8XZjbI94kpA&feature=youtu.be
所以接下來的案例實作, 也會採行這樣的流程來實作, 而這樣的流程在coding過程中實現的方式, 則是參考Udemy的Machine Learning A-Z™: Hands-On Python & R In Data Science提供的樣板, 依自己需求增減如下
 不過幸好當初念研究所時, 因為要寫論文的關係, 統計學是必修, 而剛碰機器學習領域時, 還特地把研究所用書拿來複習一下如標準差, 變異數, 檢定, 虛無假設, 信賴區間, P value與Regression等, 沒想到出了學校, 還有機會複習一遍. 可能有人會想我只要把所有的資料, 都丟給演算法算一個結果就好了, 何須管統計呢? 但是有時候眉角就在這裡, 若大家用的演算法library都一樣, 為什麼別人做出來的模型就是比較快跟準呢? 先來看一下統計可以分成兩種底下類型:
不過幸好當初念研究所時, 因為要寫論文的關係, 統計學是必修, 而剛碰機器學習領域時, 還特地把研究所用書拿來複習一下如標準差, 變異數, 檢定, 虛無假設, 信賴區間, P value與Regression等, 沒想到出了學校, 還有機會複習一遍. 可能有人會想我只要把所有的資料, 都丟給演算法算一個結果就好了, 何須管統計呢? 但是有時候眉角就在這裡, 若大家用的演算法library都一樣, 為什麼別人做出來的模型就是比較快跟準呢? 先來看一下統計可以分成兩種底下類型:Descriptive Statistics(敘述性統計):包括搜集, 整理, 分布與解釋資料, 對於所獲得的資料,加以整理解釋與分析
Inferential Statistics(推論性統計):機率形式來決斷資料之間是否存在某種關係及用樣本統計值來推 測母體的統計方法。推論統計包括假設檢定和參數估計,最常用的方法有Z 檢定、t 檢定、卡方檢定等等
Descriptive Statistics在機器學習的過程中, 應用在哪一個階段呢? 如下所示
在Explore階段, 也可以稱為是EDA(Exploratory Data Analysis, 探索性數據分析), 這也是就是為什麼當Azure Machine Learning讀取資料之後, 會顯示底下的統計資訊, 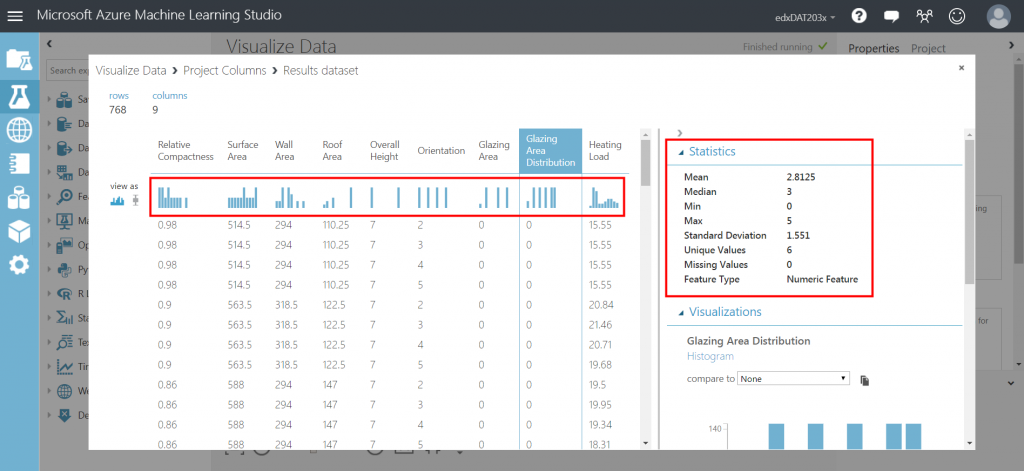
目的就是可以看看資料的分布, 以及兩兩變數的散佈圖與直方圖等, 讓我們可以對資料的全貌有個概括性的瞭解, 再進階一點就是從現有的資料是否再兜出新資料? 舉例來說Datetime的欄位, 可以再切出季度如Q1, Q2,Q3與Q4, 時間也可從24小時分成以4小時為單位, 分成6個時段等分類用的資料
而Inferential Statistics而是在可以用於底下Score階段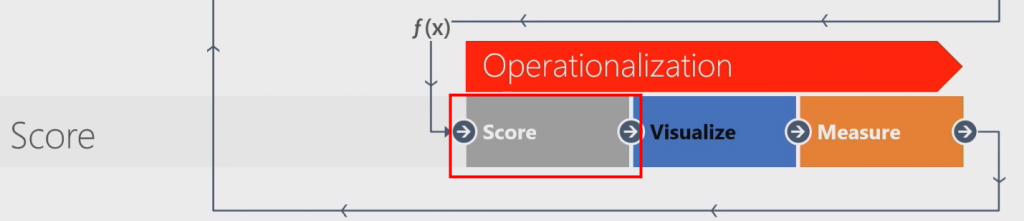
下圖是在R用summary()來檢視線性回歸的Inferential Statistics資訊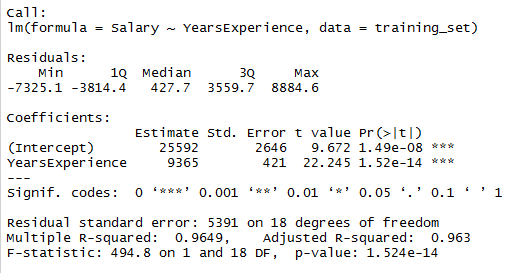
可以透過上述的資訊, 來判斷模型的優劣, 若對統計無基本的認識, 上面的資訊無疑是天書啊, 可見統計的重要性了, 在機器學習領域, 不一是要是統計學的專家, 但是一定需要懂基本的統計理論, 屆時才不會像筆者一樣書到用時方恨少啊. 台灣資料科學年會理事長陳昇瑋亦曾提及資料科學家必須周遊在各個產業領域之間, 不是只需要具備程式設計能力。資料科學家的位置介於資料工程師(Data Engineer)與資料分析師(Data Analyst)中間, 資料工程師需要的是電腦科學(Computer Science)專業;資料分析師需要的是統計(Statistical Skills)專業,資料科學家還得再加上一項領域知識(Domain Expertise)
https://www.bnext.com.tw/article/40317/bn-2016-07-25-163129-178
再推一句吳牧恩教授的臉書貼文, 鐵噹噹的數學
Full Stack Worker
近幾年很流行Full Stack(全棧式), 所以有了Full-Stack Web Developer等職稱, 來看一下Carlos Arias對於Full-Stack Web Developer工作定義如下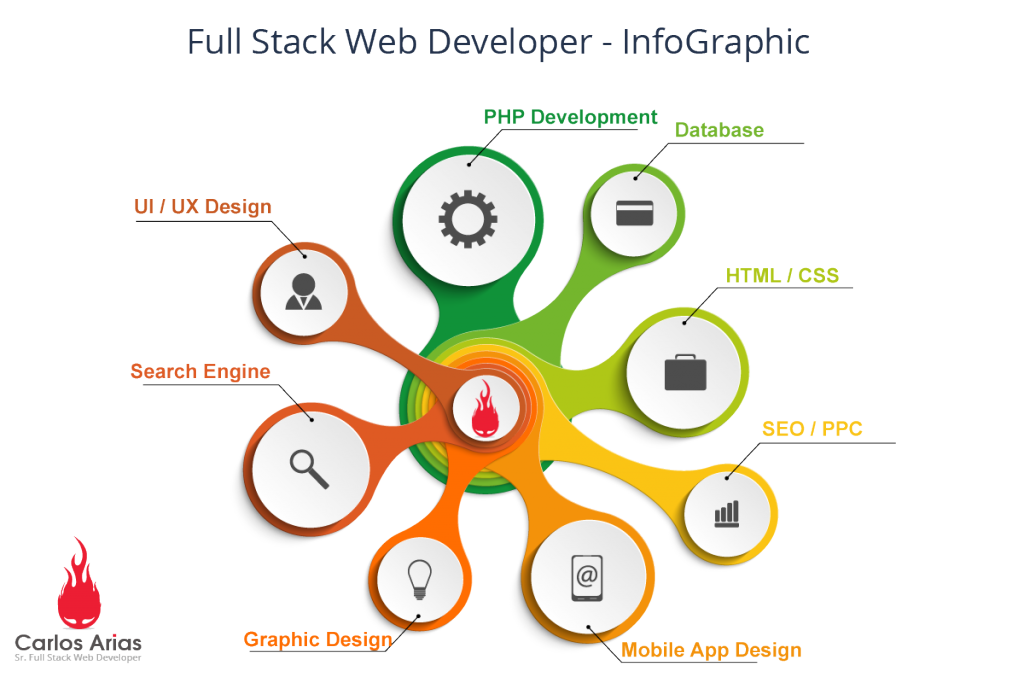
https://www.carlosja.com/full-stack-web-developer/
若加上DevOps, CI, CD等工作進來, Full-Stack Web Developer對個人而言是複雜度極高的工作, 但是接觸到Data Scientist後, Data Scientist亦不惶多讓啊, 來看一下Becoming A Data Scientist是如何定義Data Scientist的工作?
https://becomingadatascientist.wordpress.com/2013/07/26/choosing-a-data-science-technology-stack-w-survey/
每項工作挑一項至少也要會八個, 還不含要懂機器學習與統計理論, 寫到這是否有點想打退堂鼓? , 還是來跟吳牧恩教授一樣, 快快樂樂寫R就好了
, 還是來跟吳牧恩教授一樣, 快快樂樂寫R就好了
Danger Zone
個人覺得berkeleysciencereview.繪製的下面這張圖非常的傳神, 一定要貼一下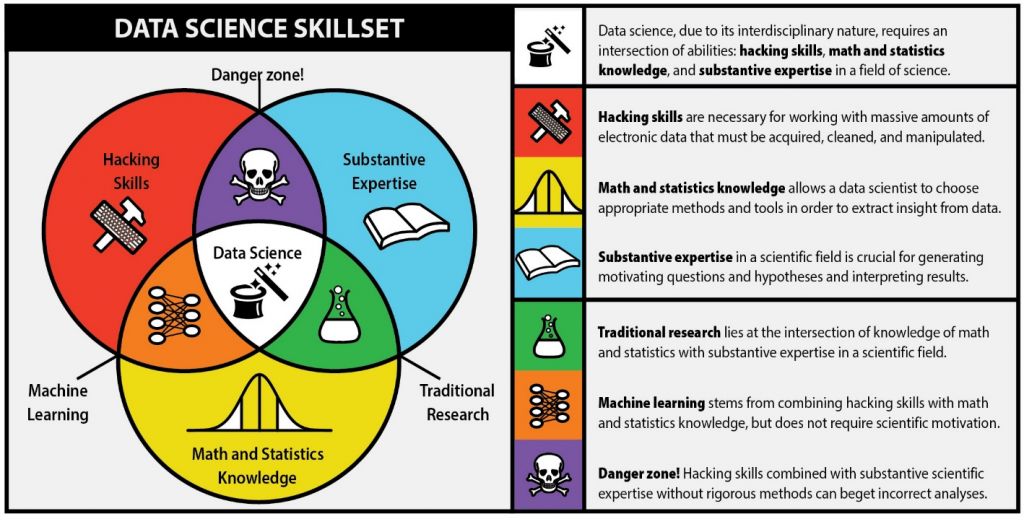
http://berkeleysciencereview.com/how-to-become-a-data-scientist-before-you-graduate/
簡而言之就是Data Science的工作若沒有數學與統計的支持就是踩到雷區, 進而做出錯誤分析, 萬一用在重要決策上, 有可能會有不好的結果甚至災難!
寫完了自己入坑的心得,接下來就是實作的部分呢?該挑哪一個來做呢? 還記得林軒田教授在研討會有提到 Regression是機器學習的基礎, 就從Regression開始吧
我也上過Machine Learning A-Z™
裡面有很多良好的範例和簡單的實作
可惜的是對於數學的原理就比較少著墨
真心推薦Andrew Ng與田神的課
Andrew Ng 是我第一個學習的地方 算是很好上手
林軒田教授我有上完基石 上完後發現我還是先把數學學好再說好了XD
一起加油吧! 田神的課, 小弟也是有空的時候再拿出來看一下, 田神師傅的課也參考
https://work.caltech.edu/lectures.html


