
今天的內容算是前幾天的複習,如果大家熟悉前幾天介紹的dplyr ,那麼這次老闆交代的任務其實非常簡單,首先,我們使用list.files 把所有下載下來的資料集合起來。
fruit_price_data <- list.files(path="downloaded/", pattern="*.csv", full.names=TRUE) %>%
map_df(~read_csv(.))
結果你應該會發現出現了幾筆非常詭異的資料。
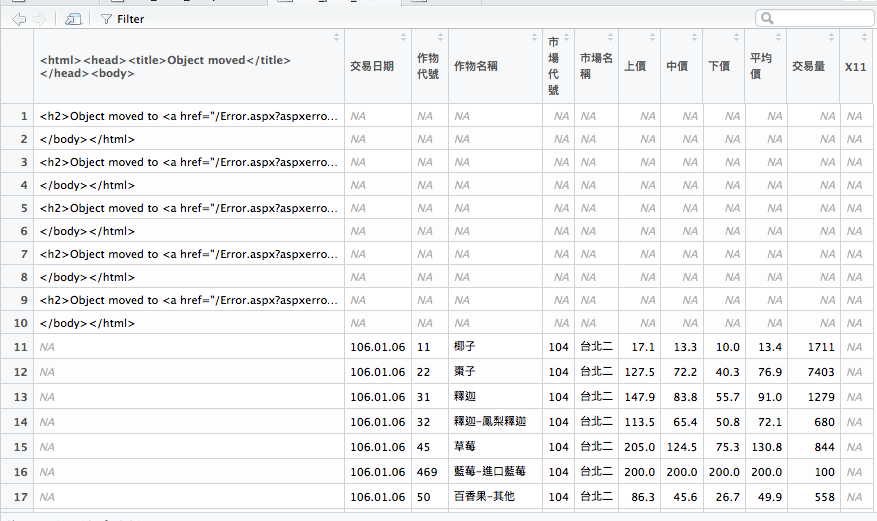
這問題其實在資料清潔時非常容易遇到,你手上的資料有很大的機率跟你預期很不一樣,我們發現下載下來的資料中,有某幾天的資料根本是空的。
使用Number/Excel 打開資料長這樣...
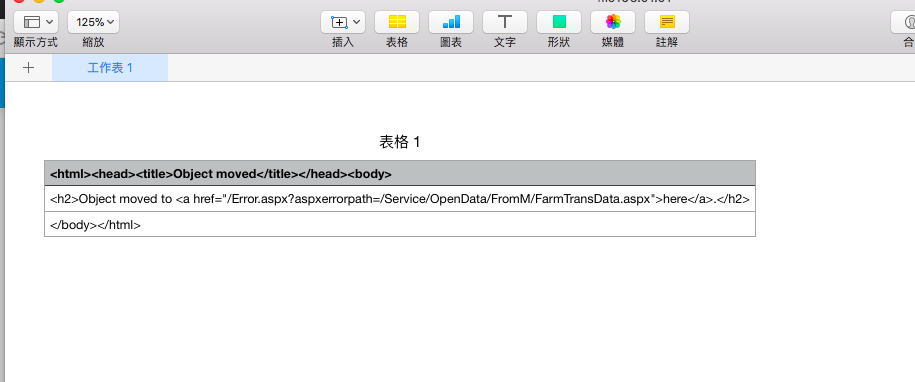
不過之前有介紹過dplyr ,我們可以用這樣的方式去除空資料。
result <- fruit_price_data %>%
filter_at(1, any_vars(is.na(.))) %>%
select_at(-1)
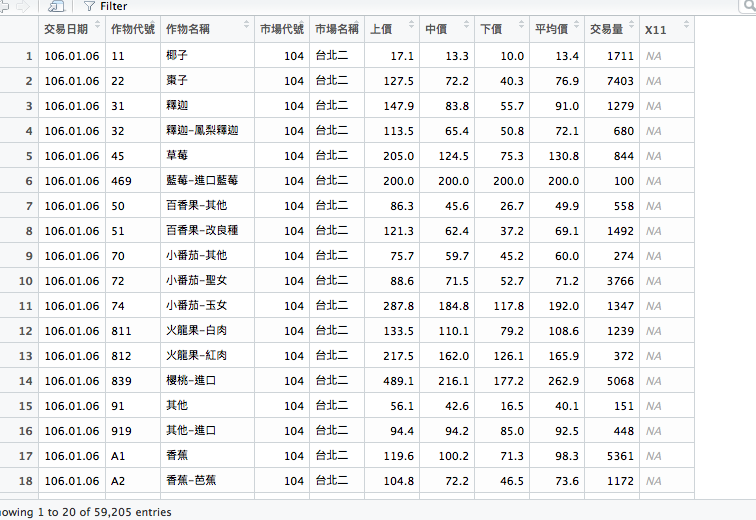
再來,根據物品名稱去group,求得各個欄位後再排序。
result <- fruit_price_data %>%
filter_at(1, any_vars(is.na(.))) %>%
select_at(-1) %>%
group_by(作物代號, 作物名稱) %>%
summarise(上價平均=mean(上價, na.rm = TRUE) ,
中價平均=mean(中價, na.rm = TRUE) ,
下價平均=mean(下價, na.rm = TRUE) ,
總交易量=sum(交易量, na.rm = TRUE)) %>%
filter(200 < 上價平均) %>%
arrange(desc(總交易量))
就可以得出結果。
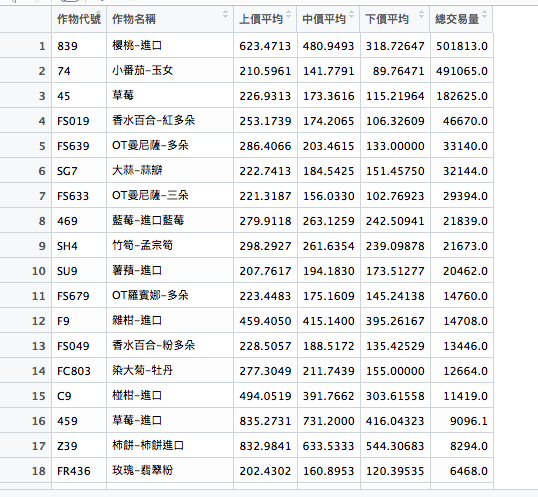
從結果發現,大部分符合如此條件的作物都是進口品或者是花卉。
ref
day13原始碼

