分類資料是AI經常最會被使用的場景,因為日常生活就是一連串分類抉擇,像過馬路時,車來了要不要停,上班時,門禁系統讓不讓你通過,當AI接收到輸入資料x後輸出資料y,就完成了一個判別動作,寫成機率的話會像是p(y|x)=p(停下來|車來了),而除了判別問題外,AI也能生成資料,像電腦自動畫畫、自動寫詩,寫成機率的話會是P(x)=p(山水畫),相較於判別問題,資料生成看起來更像人類會做的事,而電腦是如何辦到的呢?
以較專業角度來說,資料生成是以生成式模型所產生,而分類資料則屬於判別式模型,在訓練模型難度上生成式模型難度高於判別式,因為判別式模型只要在資料中找到一條線能夠將資料分成兩半就完成任務,但生成式模型則需要將資料屬性全部學起來後才能生成以假亂真的資料。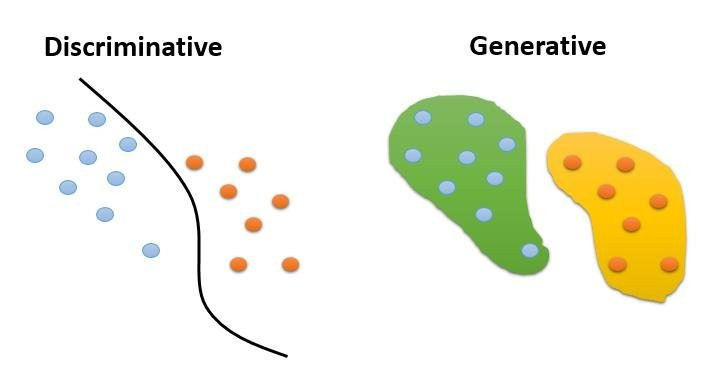
既然可以讓AI產生資料,那要怎麼產生資料
2014年Generative adversarial network(GAN)生成式模型首次被提出,相較於傳統的模型,GAN對資料及模型沒有任何假設,是一種更為通用的生成模型,更被類神經網路支柱之一的Yann LeCun學者稱做「the most interesting idea in the last ten years」。
GAN的運作方式就如上圖右一樣,透過將資料向量化後,在另一個數學空間中會呈現某種分布形狀,而GAN會學習模仿這個分布,經過大資料量加上無數次模型訓練,最終會學習到非常像原始資料的分布,學起來後,透過從分布中抽樣資料出來,就能得到看起來跟原始資料一模一樣的新資料。
1.圖像資料
因為資料分布空間的特性,在分布中不同位置抽樣就能得到不同資料,如果抽樣位置非常接近則會得到相近的資料,因此首次提出來的GAN是模仿圖形資料,相似的圖形只有少數個像素改變,不相似則多數個像素改變,完全符合空間特性。
2.文字資料
文字資料空間不像圖片一樣能夠改幾個像素就產生新文字,因此有學者在2016年提出使用policy gradient網路(增強式學習)來繞過這個問題,從此GAN也能夠產生文字資料。
而其他類型如聲音、影像等,只要能夠向量化資料GAN都可以支持,因此現在很多應用都是基於GAN模型做變化,尤其是在圖形、影像這塊。
模仿是對已知的事物進行重製的動作,所以基於模仿學習的GAN,對於不曾見過的事物是無法模仿的,只有鄉村畫的訓練資料,GAN是不可能產生山水畫,因此GAN通常需要非常大量的訓練資料才有較佳的效果。
今年初名為"Deepfake" app在美國reddit論壇火爆起來,透過GAN應用Deepfake能夠將圖片的人臉進行置換,因此許多網友製作許多假圖片大量散發,導致reddit對此發出警告。
雖然GAN只是AI中的一個分支模型,限制也還非常的多,但基於GAN產生各種以假亂真的資料技術已經發展起來,如同Deepfake一樣,只要能適當運用GAN,未來能使用上的情境將會非常多。

