昨天做了一些前處理,今天把昨天的處理好的資料做進一步的整合。
首先是宜蘭縣鐵道(polyline)
import geopandas as gpd
rail_yilan=gpd.read_file('output/Rail_yilan.shp',encoding='utf-8')
rail_yilan
匯入車站資料,並進一步篩選通話中的車站
station=gpd.read_file('output/station.shp',encoding='utf-8')
station_list=['貢寮','福隆','大里','大溪','龜山','頭城','宜蘭','二結','羅東','冬山','新馬']
station=station[station['Station_Na'].isin(station_list)]
station=station.reset_index(drop=True)
station
最後的是對話資料
import pandas as pd
talk=pd.read_csv('output/talk.csv',encoding='utf-8')
talk['time']=[row['time'][:-2]+"00" for idx,row in talk.iterrows()]
talk
接下來,我們把原始的路線資料切成通訊對話逐字稿的模式,這裡會用到graph的資訊計算,
福隆-貢寮 或是 宜蘭-二結的這種模式的線
## 這邊先手動整理對照表(對照上表)
routes=[[9,10],
[3,4],
[3,3],
[2,3],
[6,7],
[6,6],
[0,2],
[8,9] ,
[1,0],
[4,5]]
from shapely.geometry import LineString,Point
from s2g import ShapeGraph
import networkx as nx
sg = ShapeGraph(shapefile='output/Rail_yilan.shp', to_graph=True)
graph = sg.to_networkx()
line_gs=[]
line_name=[]
for route in routes:
min_distance=999
start_id=0
for num in range(sg.nodes_counter):
xy=sg.node_xy[num]
if Point(xy).distance(station.at[route[0],'geometry'])<min_distance:
min_distance=Point(xy).distance(station.at[route[0],'geometry'])
start_id=num
min_distance=999
end_id=0
for num in range(sg.nodes_counter):
xy=sg.node_xy[num]
if Point(xy).distance(station.at[route[1],'geometry'])<min_distance:
min_distance=Point(xy).distance(station.at[route[1],'geometry'])
end_id=num
nearest_path= nx.shortest_path(graph, source=start_id, target=end_id)
geoms=[]
for item in nearest_path:
geoms.append(sg.node_xy[item])
try:
line_gs.append(LineString(geoms))
line_name.append("(地點:"+station.at[route[0],'Station_Na']+"-"+station.at[route[1],'Station_Na']+")")
except:pass
train_lines = gpd.GeoDataFrame(crs= {'init' :'epsg:4326'},geometry=line_gs)
train_lines['location']=line_name
train_lines
以下是我們要的路線整合結果: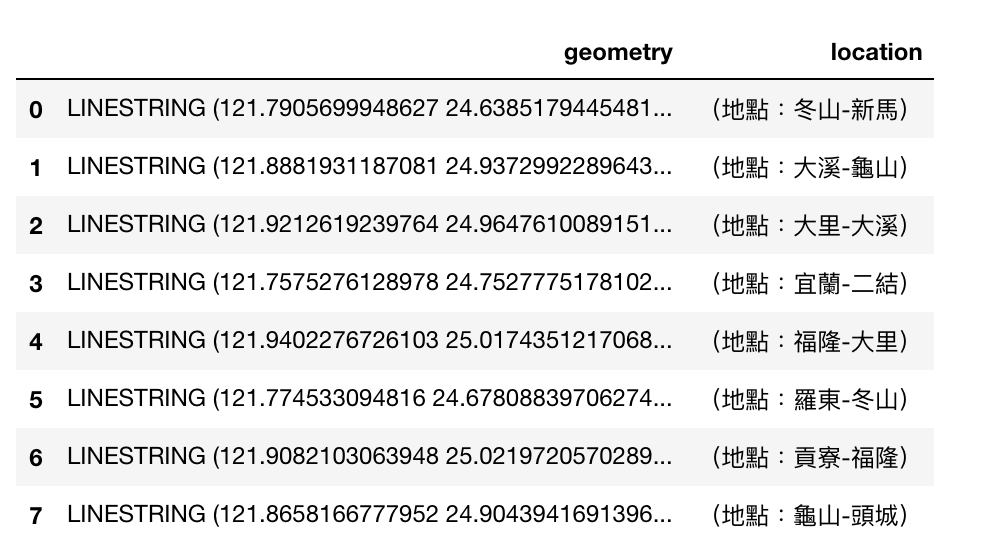
最後整合對話與路線,
# 初始化
talk['geometry']=talk['location']
for i1,r1 in talk.iterrows():
for i2,r2 in train_lines.iterrows():
if r1['location']==r2['location']:
talk.at[i1,'geometry']=r2['geometry']
break
else:
talk.at[i1,'geometry']=talk.at[0,'geometry']
st=talk.at[0,'time']
temp_text=""
geoms=[]
temp_location=talk.at[0,'location']
for i1,r1 in talk.iterrows():
if temp_location!=talk.at[i1,'location']:
geoms.append([talk.at[i1-1,'geometry'],[st,talk.at[i1-1,'time']],talk.at[i1-1,'location'],temp_text])
##release
temp_location=talk.at[i1,'location']
temp_text=""
st=talk.at[i1,'time']
else:
temp_text+=talk.at[i1,'content']+";"
geoms.append([talk.at[i1,'geometry'],[st,talk.at[i1,'time']],talk.at[i1,'location'],temp_text])
train_lines_talk= gpd.GeoDataFrame(geoms)
train_lines_talk.columns=['geometry','time','location','text']
train_lines_talk
最終成果: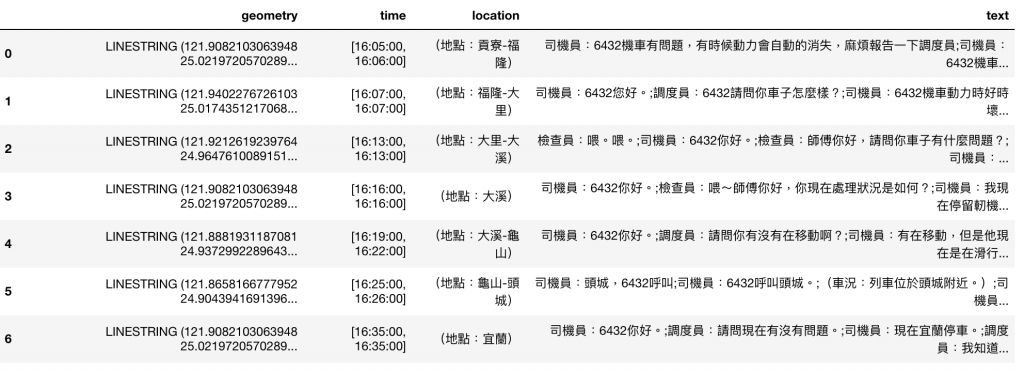


 iThome鐵人賽
iThome鐵人賽