昨天我們說明了一些蒙地卡羅方法的特色,這些特色使得蒙地卡羅方法有一些不穩定,但我們可以靠分工來彌補這個缺點。今天我們要介紹 Temporal Difference (TD) Learning,現今大多數的強化學習方法,是奠基在這個模式上繼續延伸的。事實上,這個方法可以視為動態規劃方法與蒙地卡羅方法的集大成。
這裡我們先思考一件事情,如果你現在有一個目標值 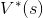 ,這個數值代表狀態 s 的真實狀態價值。可是,你手上只有隨機產生(或初始化產生)的狀態價值
,這個數值代表狀態 s 的真實狀態價值。可是,你手上只有隨機產生(或初始化產生)的狀態價值 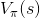 ,這個數值代表在策略
,這個數值代表在策略 下,狀態 s 的估計狀態價值。
假設我們知道目標值的話,就可以很帥氣地寫下: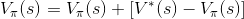
(更新完成,收工)
很難過的是,我們並不知道目標值,不過我們卻可以用這個形式逐漸逼近。首先,我們將上式改為: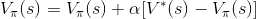 ,其中
,其中 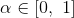
因為我們沒有「目標值」,所以不能使用「目標值」與「現在估計值」的誤差,直接更新現有策略地估計價值。不過,我們有辦法將「目標值」轉換成可以計算的形式。(ex: 動態規劃方法)
話雖如此,但因為目標值也是估計的,所以使用誤差更新時,直接更新的風險太大。因此這邊設定一個參數 表示要更新的比率。我們又可以稱這個誤差為「學習率 (Learning rate)」,表示從誤差中學習、進行更新。
剛剛有提到我們可以將目標值,轉換成可以計算的形式,請回想狀態價值函數的定義: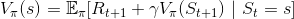
即可得到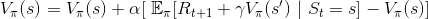
不過我們在更新狀態價值時,並不針對所有的狀態更新。而是像蒙地卡羅方法一樣,放到模擬的環境中運行,移動到的狀態才更新。由於在蒙地卡羅方法模擬時,動作與狀態已經確定了,所以可以在進一步簡化數學式為: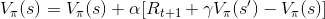
整體流程圖如下:
明天我們將以 temporal difference learning 實作狀態價值估計。

