分群(Clustering)演算法是使用非監督式學習方法將相似的資料聚集在一起,跟分類(Classfication)演算法不同的地方在於無法提前知道輸出類別有哪些,K-Means 是一種常用的分群演算法,做法是將每筆資料視為一個點,先隨機挑選 K 個點當作群中心,接著計算點與群中心的距離,將點歸類為最近的群,接著重新挑選群中心,一直重複執行後,最後會得到更準確的 K 個群中心
位置:Machine Learning / Initialize Model / Clustering / K-Means Clustering
【Dataset】匯入資料集:Wholesale customers Data Set 批發客戶資料集
【Import Data】資料來源 URL:https://archive.ics.uci.edu/ml/machine-learning-databases/00292/Wholesale%20customers%20data.csv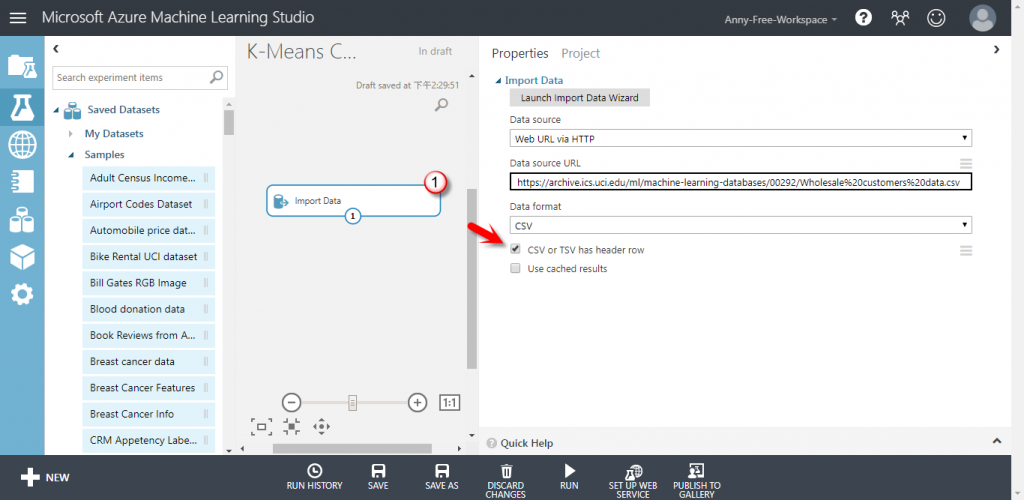
此 CSV 檔的第一筆資料為欄位名稱,所以上方的 CSV or TSV has header row 要勾選,不然的話資料會像下圖,將欄位名稱當成第一筆資料來用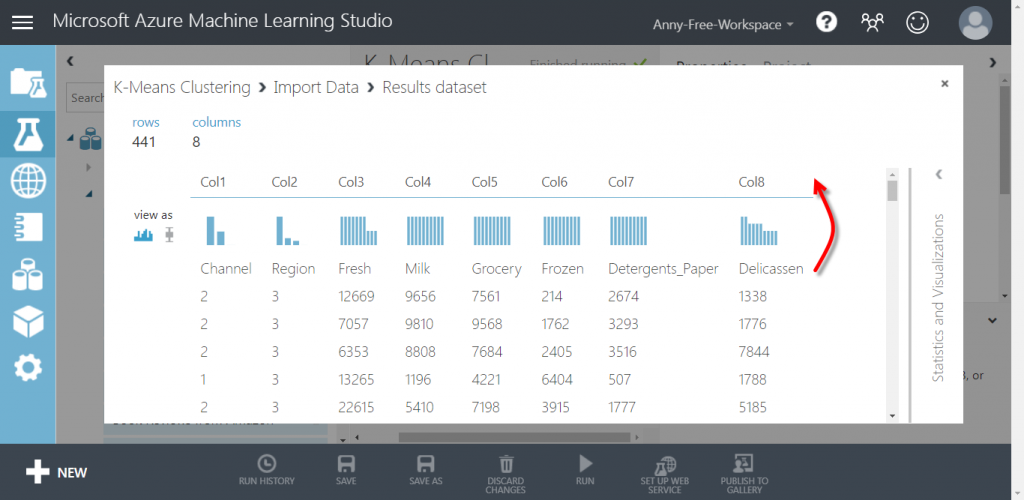
Wholesale customers Data Set 批發客戶資料集有以下欄位:
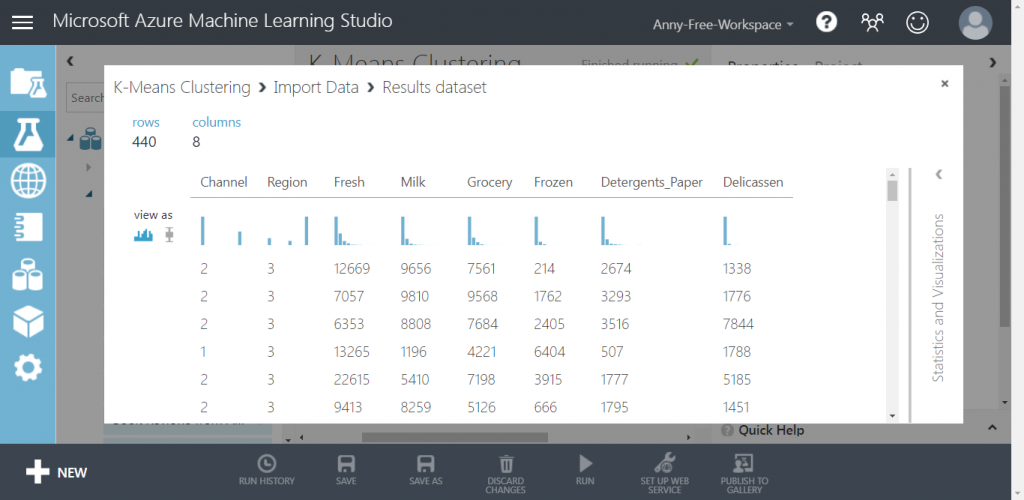
資料來源:UCI Mahchine Learning Repositury - Wholesale customers Data Set 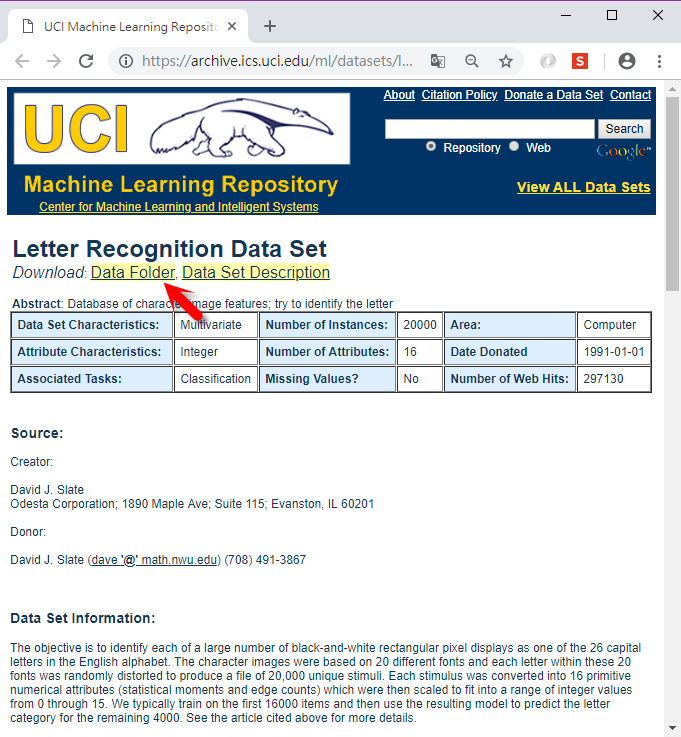
【Train Clustering Model】分群訓練模型:選擇所有欄位
【Clustering】演算法:K-Means Clustering,設定 K=4 ,將資料分為 4 群,選擇 Euclidean 歐幾里得距離測量方法、Iterations 迭代次數設定預設的 100 ,也就是重新挑選群中心的次數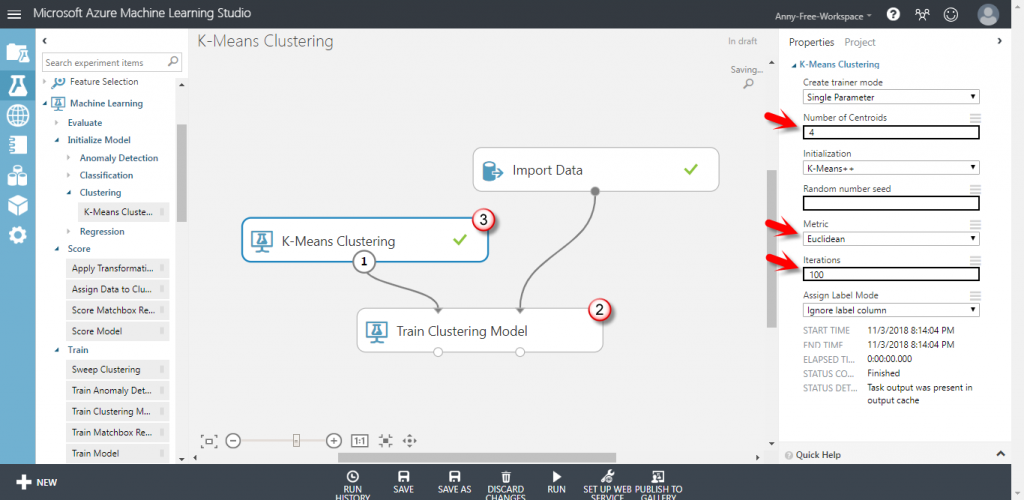
執行完成後,可以看到分群後的結果為下圖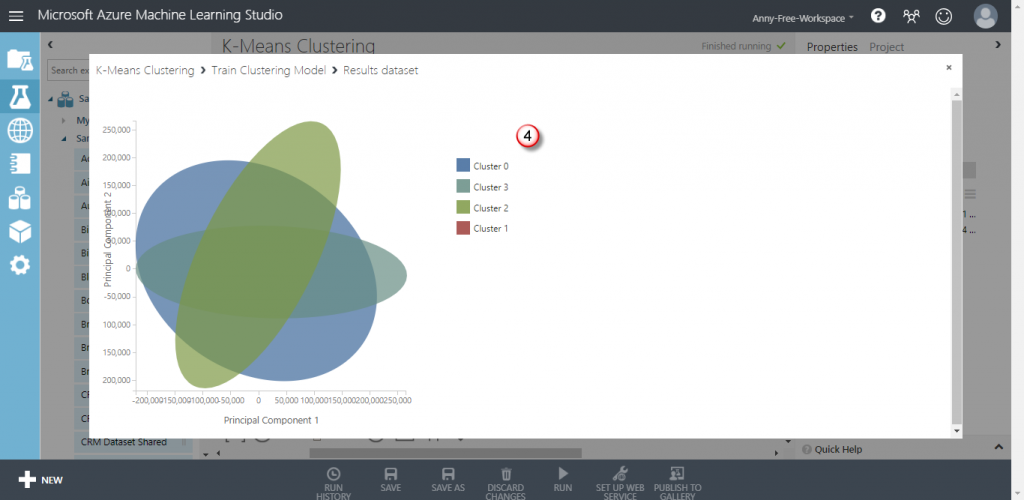
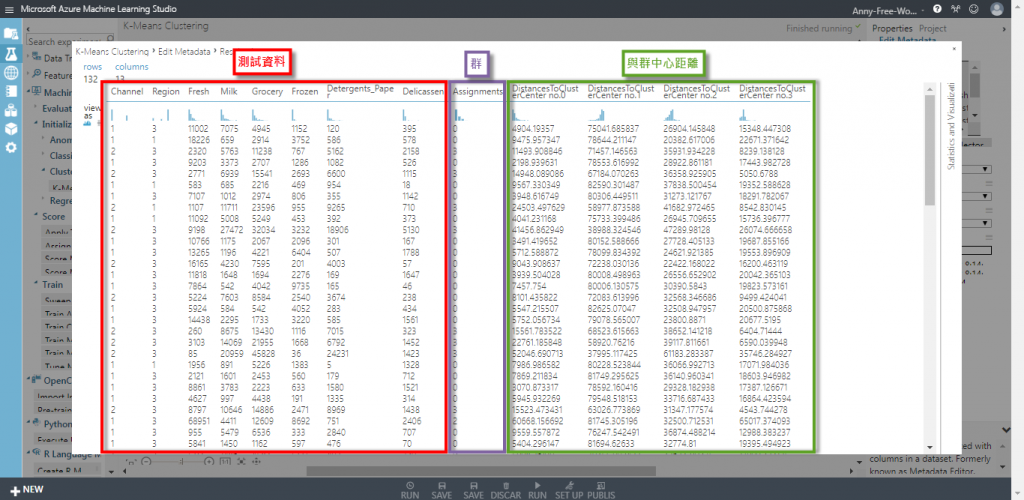
【Edit Metadata】可以使用 Edit Metadata 看分群結果的數據值,選擇所有欄位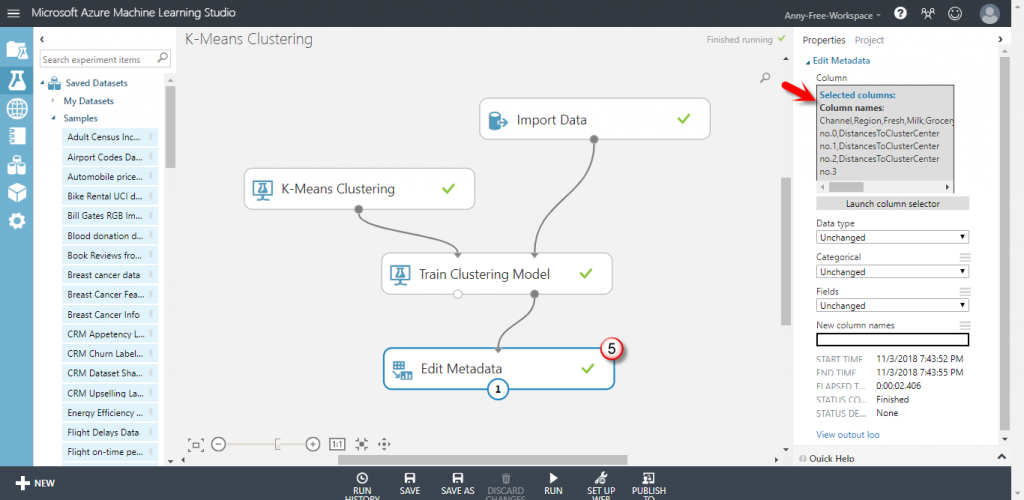
執行後結果為下圖,前部分為原資料、Assignments 是分成哪一群、後方的DistancesToClusterCenter no.X 代表此資料與各個群中心的距離,例如:第 1 筆資料距離群 0 的距離 = 8102.728234、距離群 1 的距離 = 63300.236988、距離群 2 的距離 = 24730.050289、距離群 3 的距離 = 23779.390318,所以會被分類到距離最近的群 0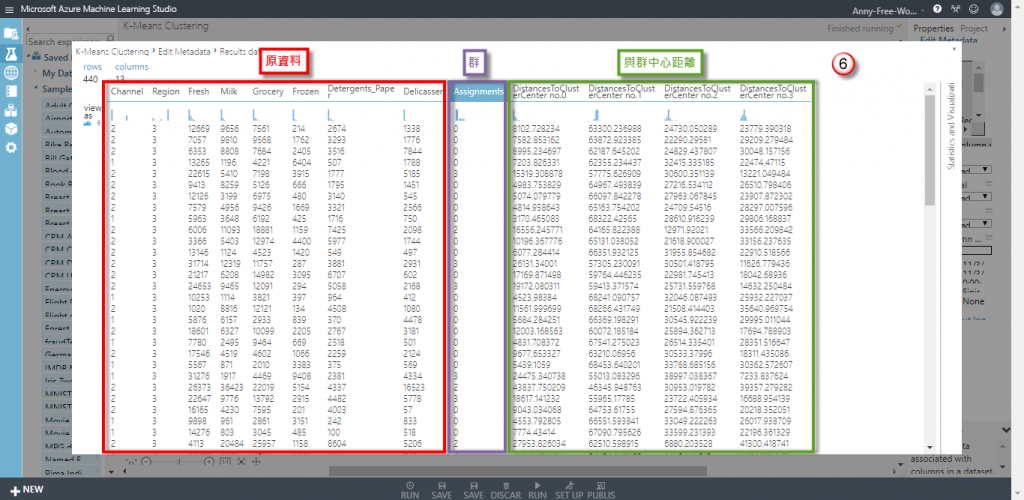
開啟右手邊的統計數據也可以看各個群的數量,可以看到群 0 佔最多數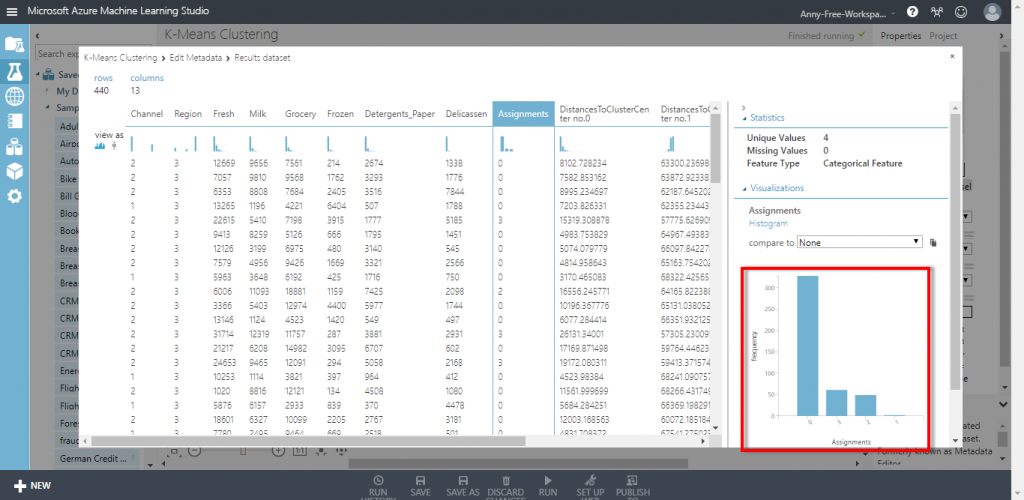
以相同的資料集與分群訓練模型,再額外新增 Split Data 將資料分為訓練集與測試集,以及新增 Assign to Clusters,左半邊的輸入接 Train Clustering Model 的輸出、右半邊的輸入接 Split Data 測試集的資料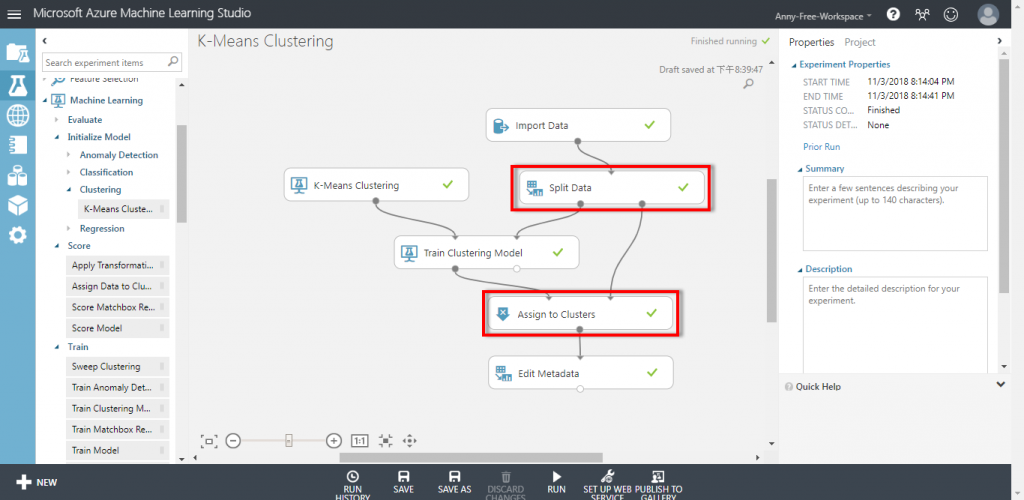
重新執行結果,就可以看到新資料分別會被分在哪一群中