多類別分類(Multiclass Classification)用在當實驗的預測結果不只分成兩類別的時候,像是字母手寫辨識、數字手寫辨識、NBA 季後賽的優勝隊伍預測,就可以使用多類別分類演算法
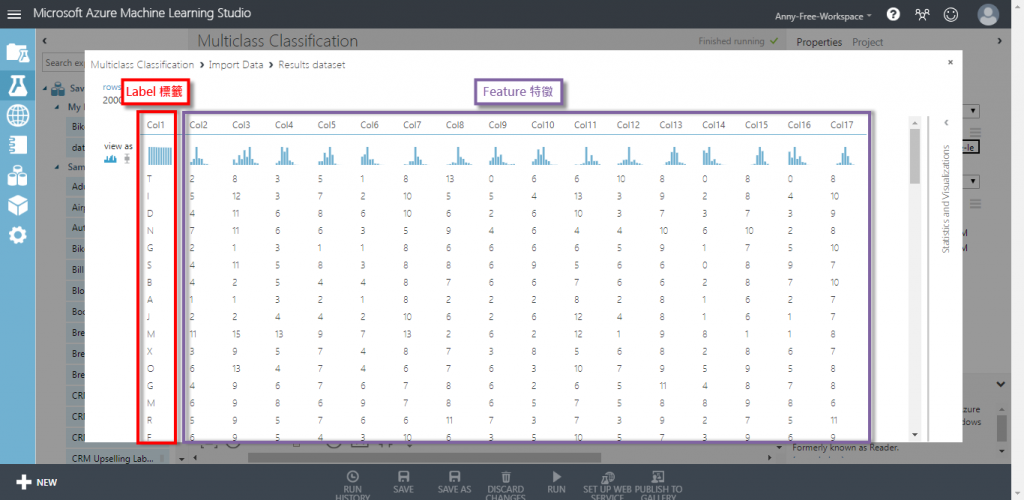
【Dataset】匯入資料集:Letter Recognition Data Set 手寫英文子母資料集
【Import Data】資料來源 URL:http://archive.ics.uci.edu/ml/machine-learning-databases/letter-recognition/letter-recognition.data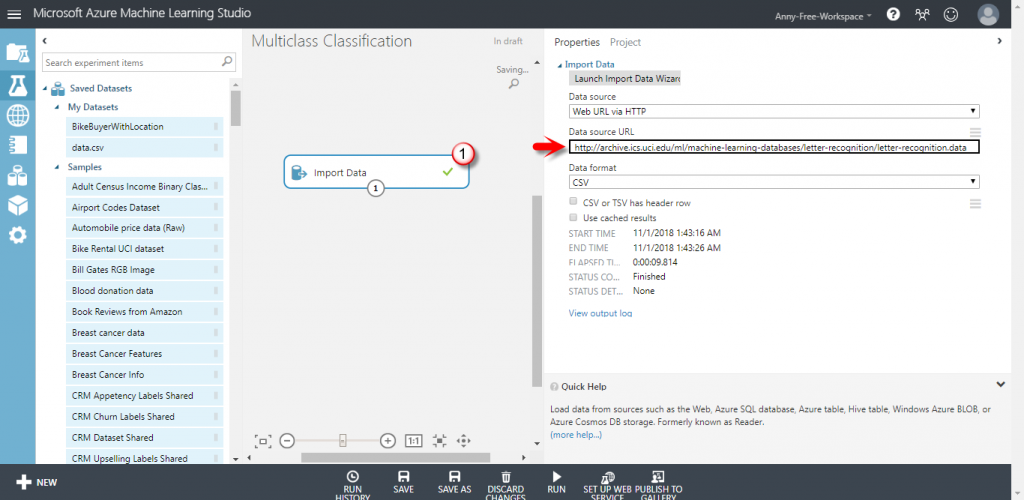
資料來源:UCI Mahchine Learning Repositury - Letter Recognition Data Set
【Split Data】設定比例為 0.7:70% 訓練集、30% 測試集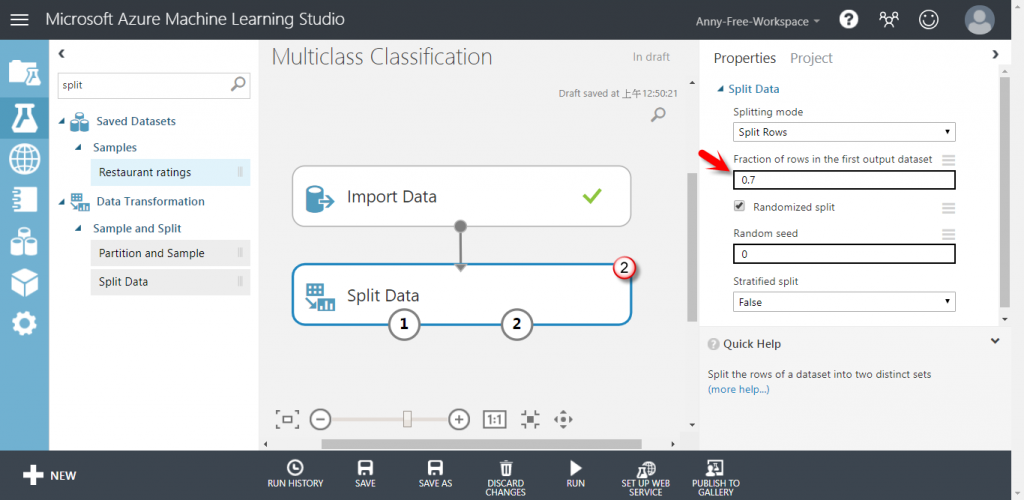
【Train Model】訓練模型:設定要預測的目標欄位 - Col1 英文字母
【Classification】演算法:Multiclass Decision Jungle 多元分類決策叢林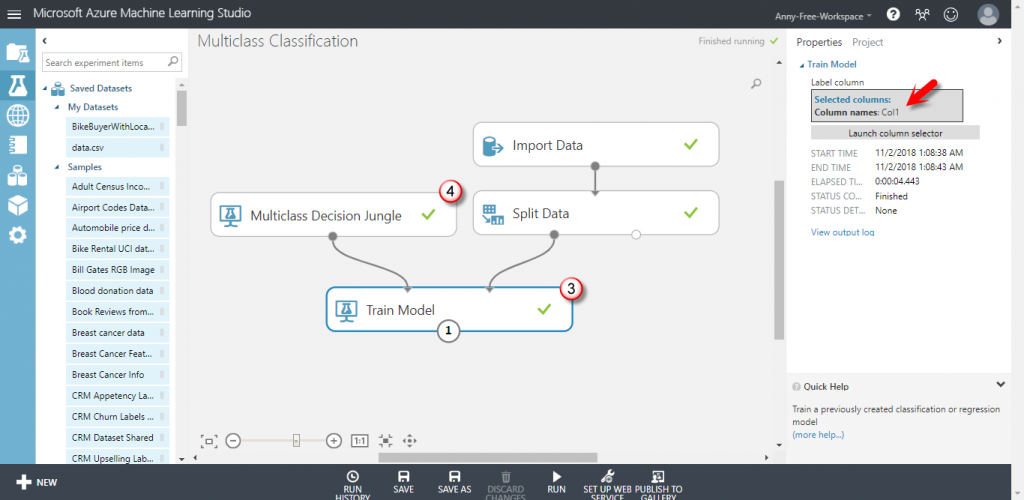
【Score Model】計分模型:執行預測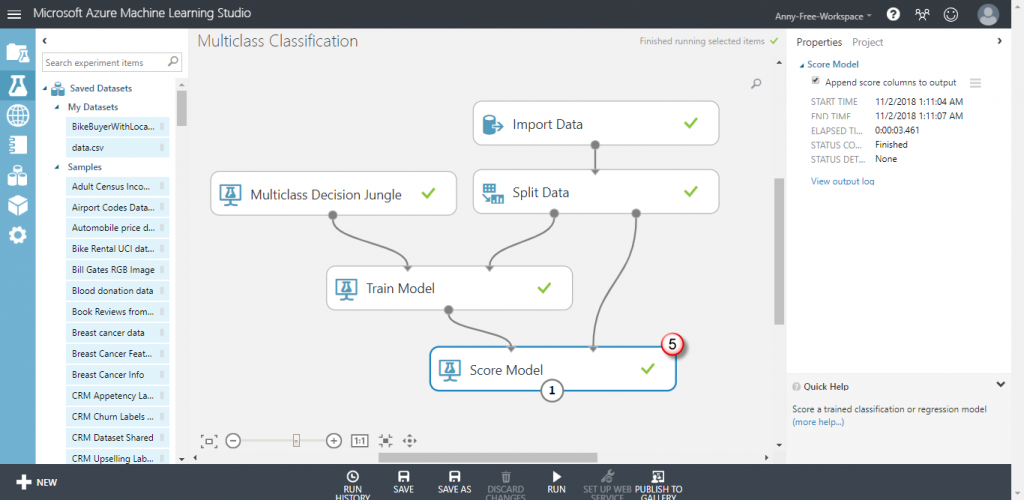
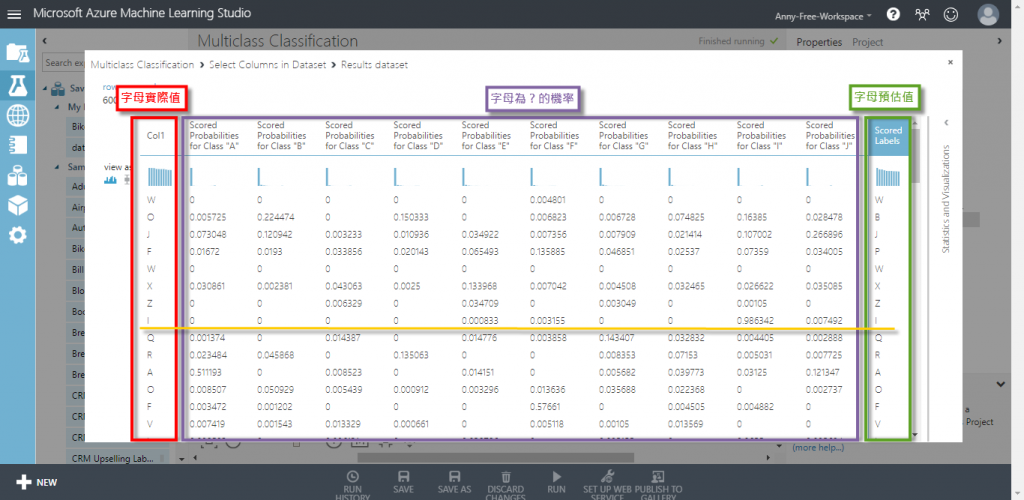
預測結果包含 17 欄原資料,以及 26 欄英文字母的預測機率值和 1 欄預測值,為了方便查看預測結果,會拿掉特徵值 16 個欄位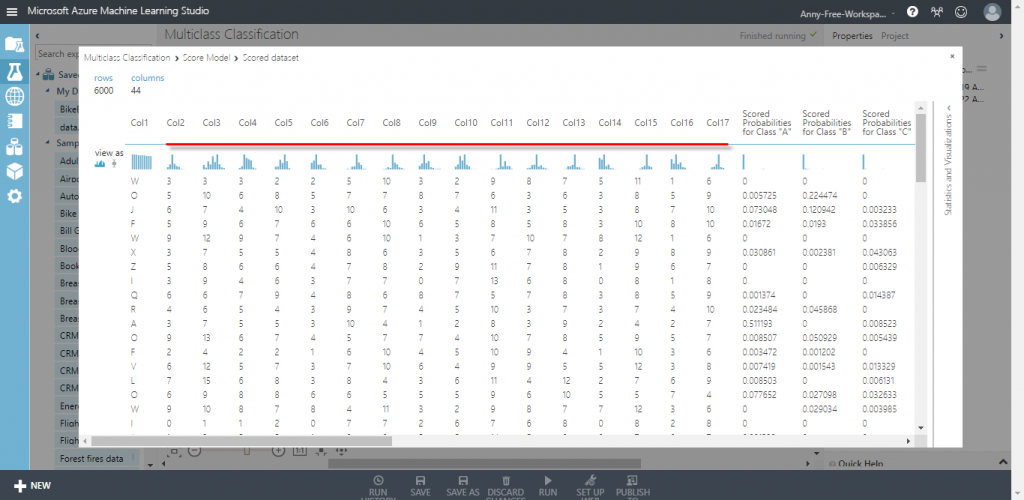
【Select Columns in Dataset】選取資料集欄位:只選取結果 Col1 英文字母實際值 + 後半部的預測結果欄位,排除原特徵欄位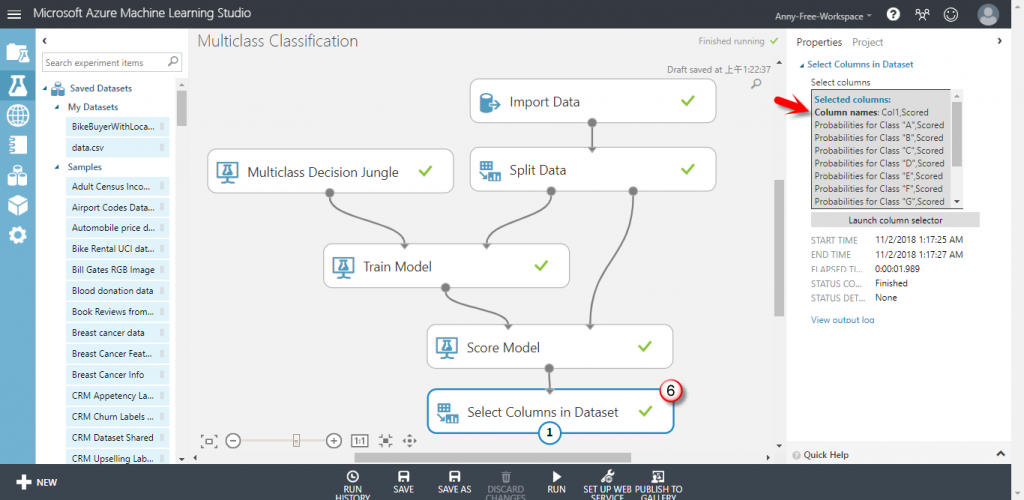
Scored Probabilities for Class " ? " 是英文字母為 ? 的機率,Scored Labels 是英文字母預估值,例如:第 8 筆資料,預估為英文字母 E 的機率為 0.000833,預估為英文字母 A、B、C、D、G、H 的機率為 0,預估為英文字母 I 的機率為 0.986342,字母預估值選機率最高的 I