資料是政府開放資料的地區年齡性別統計表-急性病毒性B型肝炎的名單,是.json檔,不必下載可以直接讀取。首先處理名單年齡層問題,因為對電腦而言年齡的資料是
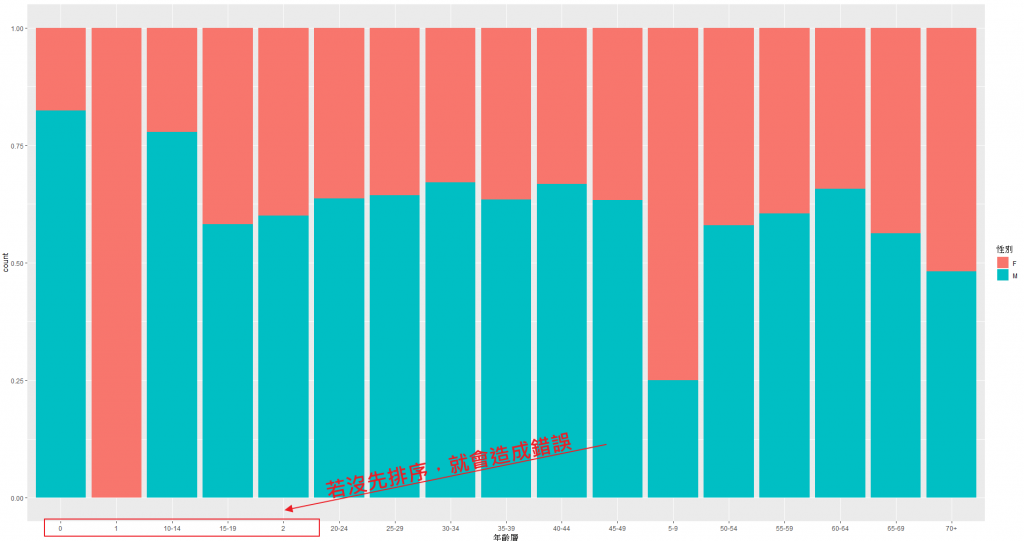
2應該要在1之後,而不是在19之後才對。
library(jsonlite)
library(tidyverse)
data <- fromJSON("https://od.cdc.gov.tw/eic/Weekly_Age_County_Gender_0703.json")
as.tibble(data)
View(data)
我的處理方法就是,"補0",數字小的就補0,"1"變成"01","2"變成"02"這樣順序就會對了,問題就在於說怎樣能夠準確地補0呢?我們用文字處理的nchar(),他可以告訴我資料的長度,nchar("1")就是1,nchar("10-14")就是5,這樣我們就可以用ifelse準確的做到我想要的效果,然後我的這筆資料是分1,2,3,4,5-9,因此我為了要讓5-9也跑到正確的排序位置,我用grepl("5-9",x),這樣可以判讀x是不是5-9,是的話就補。
table(data[,3])
hist(as.numeric(data[,3]))
table(data[,6])
table(data[,c(6,8)])

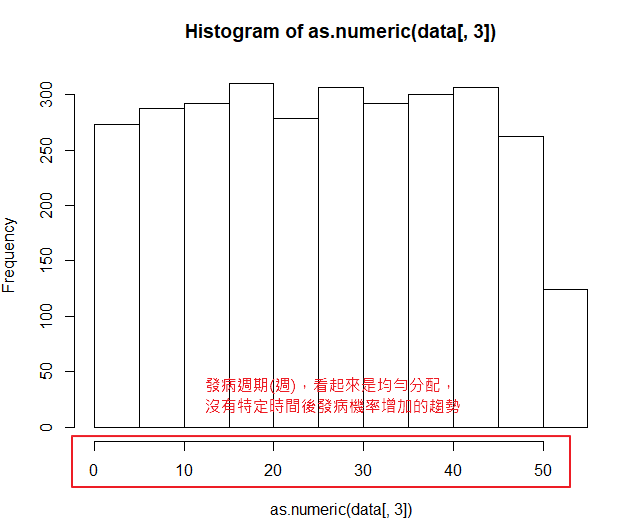
*資料探索順便畫的。
data[,8] = ifelse(nchar(data[,8]) == 1 | grepl("5-9",data[,8]) , paste0("0",(data[,8])), data[,8])
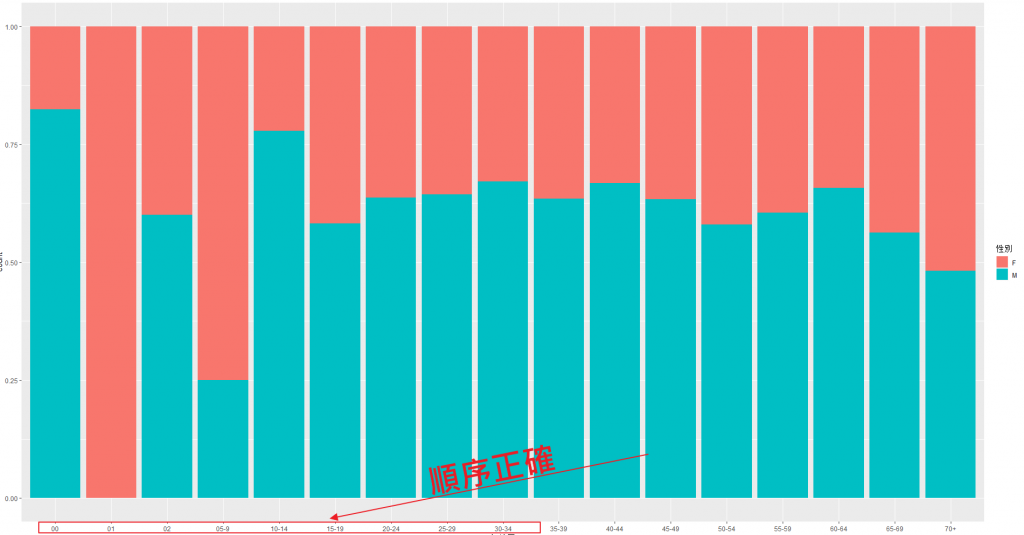
最後完成我們的目標:累積長條圖。
ggplot(data, aes(x = 年齡層, fill = 性別)) +
geom_bar(position = "fill") #fill是累積的概念


資料集:https://data.gov.tw/dataset/9882

