為了讓一張圖上的資料更豐富,我在這張長條圖上做了許多小細節的改動,稍微介紹一下一些需要注意的點。
就這樣,過去29天了,不得不說一開始寫文章的時候是真的很盡心盡力,甚至我同學都明顯感受到我胖了,(每天多坐在電腦桌前幾個小時不胖也說不過去),然後去趟北海道的那幾天真的很硬,坐飛機都還在想鐵人賽的事,終於最後一篇了(Day30我估計是感謝文啦哈哈),後來覺得時間調配上真的不行這樣一直坐在電腦前,才慢慢的寫的比較輕鬆。這篇要介紹的也是工作上需求,要畫一張能放很多資訊的圖,然後才做的研究。
讀檔
library(jsonlite)
library(tidyverse)
data <- fromJSON("https://od.cdc.gov.tw/eic/Weekly_Age_County_Gender_0703.json")
data[,8] = ifelse(nchar(data[,8]) == 1 | grepl("5-9",data[,8]) , paste0("0",(data[,8])), data[,8])
data
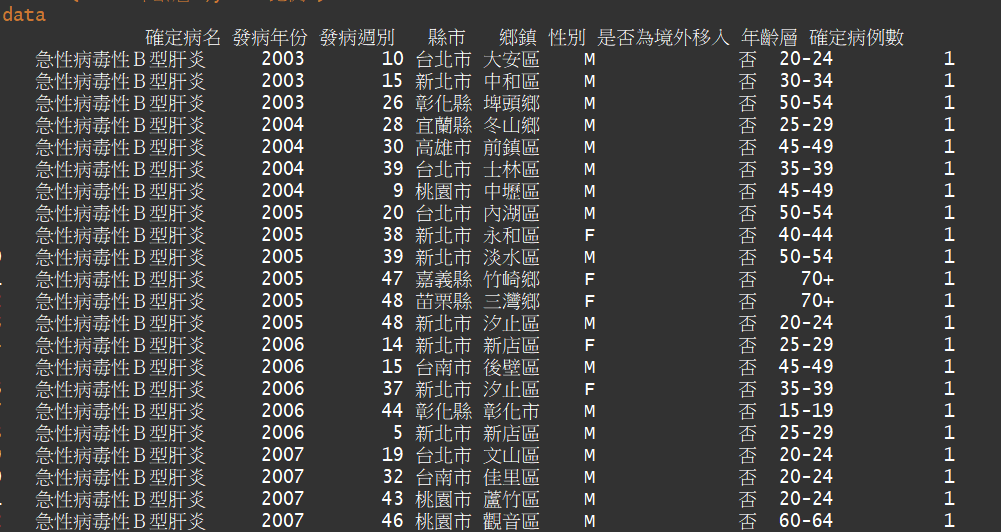
這裡的細節是
1.plyr跟dplyr兩個package有衝突,要使用的時候記得要解除安解除安裝(detach)另外一個。
2.然後factor(.$性別)的部分,雖然性別本來就是因子變數,但是我在工作上的資料這邊是樹執行的連續變數,會導致資料雖然能畫圖但是會不知所云。要改成因子變數才行。
3.我其實是用累積長條圖的方式去畫百分比長條圖的,因為我找不到百分比長條圖如何加文字,因此我是將資料變成百分比的形式,才去做累積長條圖,這樣就會讓累積長條圖每個都累積到100%看起來就像是百分比長條圖了。
library(plyr)
#----統計起來為了做長條圖----#
ess2 = ddply(data,.(年齡層),function(.){
res = prop.table(table(factor(.$性別)))
res2 = table(factor(.$性別))
data.frame(lab=names(res), y=c(res),yy =c(res2))
})
detach("package:plyr", unload=TRUE)
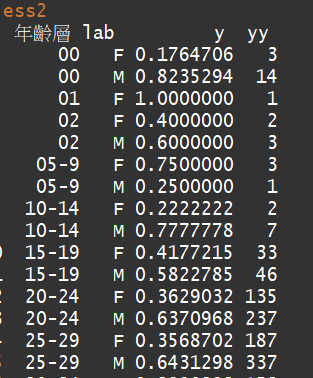
我建立for_show資料集,單純是因為我想要將每一條長條圖的資料數量記錄在圖片上,因此透過group_by跟summarise統計每一條長條圖的數量為何。
library(dplyr)
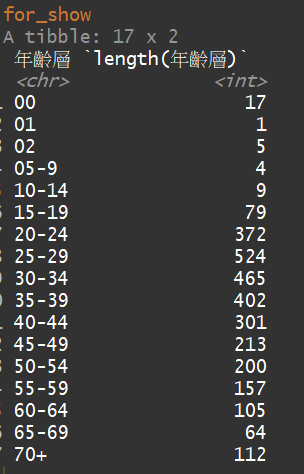
for_show = data %>% group_by(年齡層) %>% summarise(length(年齡層))
內建字體不是說不好看,不過我喜歡微軟正黑體,也方便如果有需求想要換華康少女體的時候,可以直接修改這裡。
windowsFonts(A=windowsFont("微軟正黑體"))
因為我並不是畫百分比長條圖,所以我必須用畫累積長條圖的方式去做畫。
geom_bar(stat = "identity") 這部分算是預設
theme_classic(base_size = 16) 這行可以讓X軸、Y軸線條好看一些
geom_text(mapping = aes(label = sprintf("%.2f%%",y100)),
size = 5, colour = 'black', vjust = 2, hjust = .5, position = position_stack())
這行就是加字了(百分比的部分) 顏色為black黑色,大小size為5,vjust表示上下的距離hjust是左右
sprintf("%.2f%%",y100) 是讓數字變成百分比的方法
theme(axis.text.x=element_text(face="bold",size=20,angle=360,color="#333333")) 因為X軸的字顯示太小了,用這行可以把size調成20比較方便看
scale_y_continuous(breaks = c(0,0.25,0.5,0.75,1) ,labels =c("0%","25%","50%","75%","100%"))
把Y軸的0 0.25 改成%數 0% 25% ,也可以改成文字,用法很多樣
scale_fill_discrete(name="性別",labels=c("女","男")) 這部分是改右邊的圖例
labs( x= "年齡層",y = "比例") 改變X、Y軸呈現的文字
geom_hline(yintercept=0.5,linetype="twodash",colour="#0000ff",size = 1) #增加一條中線,可以加強判斷
ggplot(ess2,aes(x = 年齡層,y=y,fill = lab))+
geom_bar(stat = "identity") +
theme_classic(base_size = 16)+
geom_text(mapping = aes(label = sprintf("%.2f%%",y*100)),
size = 5, colour = 'black', vjust = 2, hjust = .5, position = position_stack())+
annotate('text',x = 1:nrow(for_show),y=0.1,label= unlist(for_show[,2]),family = "A",size = 5.5,fontface =2)+
theme(axis.text.y=element_text(face="bold",size=15,color="#333333"))+##調整y軸字型
theme(axis.text.x=element_text(face="bold",size=20,angle=360,color="#333333"))+#x軸字型(筆數的數字)
scale_y_continuous(breaks = c(0,0.25,0.5,0.75,1) ,labels =c("0%","25%","50%","75%","100%"))+
scale_fill_discrete(name="性別",labels=c("女","男"))+
labs( x= "年齡層",y = "比例")
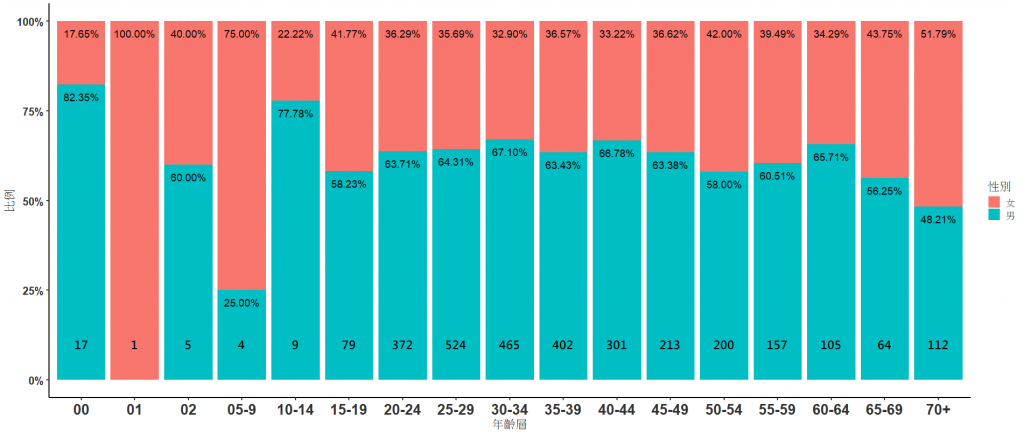
這樣就完成啦~

