前一篇中我們主要觀察了第一個卷積層的輸出以及內部結構.那我們今天要來觀察的就是第二個卷積層的作用.
還記得前一層中最後的結果是 14 x 14 x 32 的輸出,而這輸出就是要在把它餵入第二個卷積層.第二個卷積層構造跟前一個幾乎是一模一樣
好的那讓我們看一下各個位置的輸出:
# 印出第二層的 weights
plot_conv_weights(W_conv2, 64)
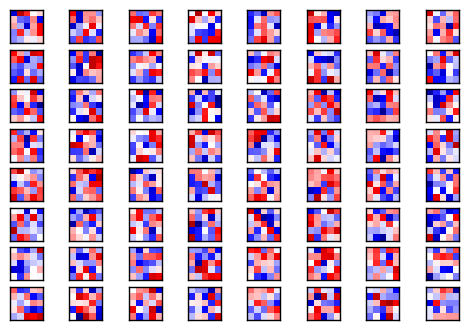
# 印出第二層經過過濾器的結果
plot_conv_layer(conv2d(h_pool1, W_conv2), mnist.test.images[0], 64)

# 印出第二層經過 ReLU 的結果
plot_conv_layer(tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2), mnist.test.images[0], 64)

# 印出第二層經過 MaxPooling 的結果
plot_conv_layer(max_pool_2x2(tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)), mnist.test.images[0], 64)

為什麼最後需要這一個全連結層呢?
可以想像的是,前面的層學出了很多的 特徵 ,而這些特徵的 組合 可以幫助我們分辨現在這個影像輸入是哪一個數字!然後加入全連結層是一個非常簡便的方法來把這些特徵集合組合在一起然後從中做分類.
而在全連結層之後會接一個 dropout 函數,而它是為了來避免 overfitting 的神器,通常在訓練過程會使用(這裡的 p = 0.5)意思就是會這些神經元會隨機的被關掉,要這樣的做的原因是避免神經網路在訓練的時候防止特徵之間有合作的關係.
隨機的關掉一些節點後,原本的神經網路就被逼迫著從剩下不完整的網路來學習,而不是每次都透過特定神經元的特徵來分類.
通俗的講法就是,我們要百般刁難這個網路,讓它在各種很艱困的情形下學習,不經一番寒徹骨,哪得梅花撲鼻香(怎麼越來越覺得訓練網路好像在做軍事訓練一樣...)
看完了以上 CNN 的結構以後,那為什麼這個方法叫做深度學習呢?
因為呀就是大家發現如果越多層效果會越好!!
試了一下把第二個卷積層拿掉以後,準確率就掉到了 98.88%.
而在知名的圖片比賽 ImageNet,更可以看到這幾年贏的模型,可說是越來越深呢...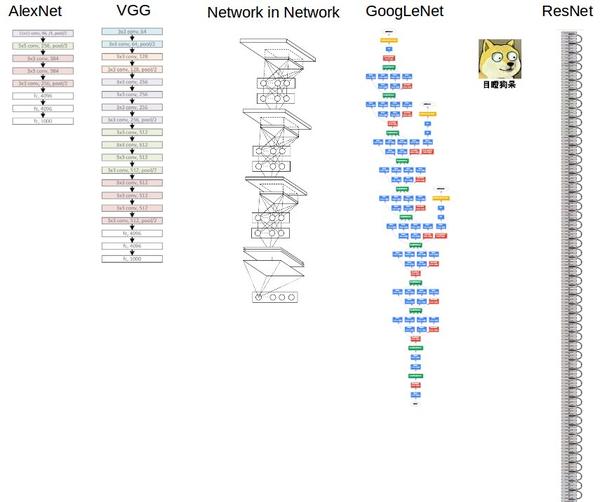
(原圖連結:https://www.zhihu.com/question/43370067)
今天從第二層的輸出看到了和第一層不同辨識特徵的差別,然後了解了為什麼後面還要接一個全連接層和 dropout 的原因.今天文字比較少的原因是我想要把它多加幾層結果就...
MNIST_Convolutional_Network Jupyter Notebook 全文傳送門
連結的最後面多了一個")",要手動把")"拿掉才能正確開啟網頁
錯誤:
https://www.zhihu.com/question/43370067)
全連結,Dropout 的原因寫得不錯
不過全文傳送門 404 Not found
看來作者懶得更新了= =
https://github.com/c1mone/Tensorflow-101/blob/master/notebooks/2_MNIST_Convolutional_Network.ipynb


