從文字或影像提取特徵 Feature extraction from texts, images
純 Text 競賽: Allen AI challenge
純 Images 競賽: Data Science Bowl
文字特徵有兩種處理方法, 詞袋跟word2vec, 詞袋較簡單.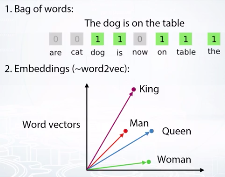
截圖自coursera
BOW 詞袋的概念, 是把文字轉化成向量, 請參考下列名詞解釋.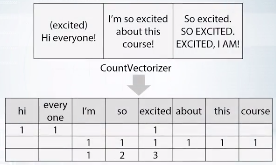
截圖自coursera
sklearn.feature_extractin.text.CountVectorizer
tf = 1/x.sum(axis=1)[:,None]
x = x * tf
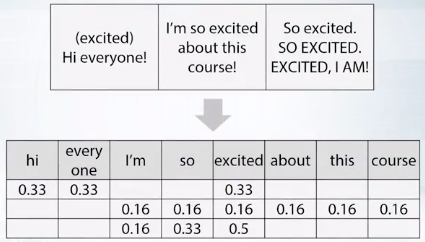
截圖自coursera
idf = np.log(x.shape[0]/(x>0),sum(0))
x = x * idf
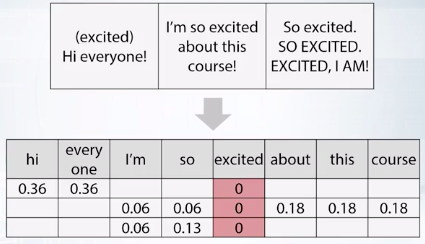
截圖自coursera
sklearn.feature_extraction.textTfidfVectorizer
引用自曾元顯 2012年10月圖書館學與資訊科學大辭典
http://terms.naer.edu.tw/detail/1679006/
詞袋模型(bag of words model)重點不在於這個想像中的袋子,而在於其對待袋子中的詞彙方式,亦即每個詞彙都是獨立的單位,不考慮其相依性。例如:文件A中的內容(如篇名)若為:「病人與醫生的糾紛研究」,以詞袋模型表示,則該文件可以表達成:「病人、糾紛、醫生、研究」這四個獨立的詞彙。
文件中的詞彙代表空間中的一個維度,而維度與維度之間是獨立的,如此形成文件向量,便於後續的向量計算。如上例,文件A與文件B以(病人、醫生、糾紛、研究、醫療、缺失、改善、探討),8個詞當維度,可以分別表示成(1, 1, 1, 1, 0, 0, 0, 0)與(0, 0, 0, 0, 1, 1, 1, 1)的向量。
sklearn.feature_extraction.text.CountVectorizer: Ngram_range, analyzer
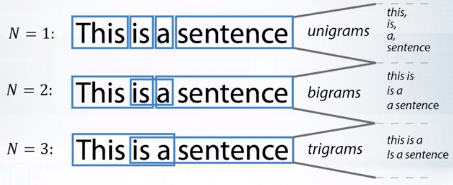
截圖自coursera
引用自2003年6月資訊與通信術語辭典
http://terms.naer.edu.tw/detail/1283111/
建立在n-1階馬可夫模型上的一種概率語法,依據語句中n個語詞之同現概率的統計資料,來推斷句子的結構關係。當n=2時,稱為二元語法(bigram);當n=3時,稱為三元語法(trigram)。
NLTK, Natural Language Toolkit library for python
sklearn.feature_extraction.text.CountVectorizer: max_df
-預處理 Lowercase, Stemming, Lemmatization 及 Stopwords
-Ngram
-後製 : TFiTF

