匿名是保護資料免於用來找出真實資料的一種模式, 例如雜湊 hash 處理較敏感或機密的資料, 參賽者可透過合法的方式解匿名, 例如下面例子的 x1~x6 匿名特徵.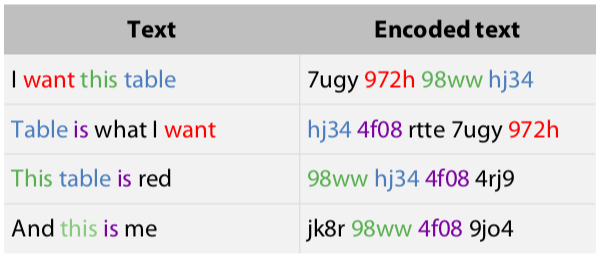
截圖自coursera
-猜測欄位意思
-猜測欄位類別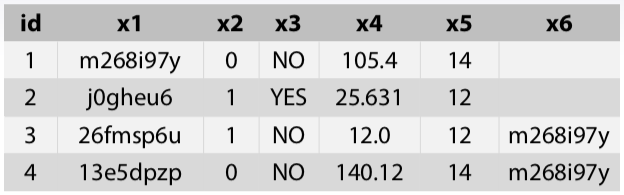
截圖自coursera
| x1 | 文字或實體記錄 |
|---|---|
| x2 | 二元資料 |
| x3 | 二元資料 |
| x4 | 數值資料 |
| x5 | 類別或數值資料 |
| xn | ..... |
在資料多時, 無法目視判斷, 可用下列函數
df.dtypes
df.info()
x.value_counts()
x.isnull
-找出配對
-找出群組
截圖自coursera

