第一週曾有說過天下沒白吃的午餐, 預處理後的重點仍是瞭解資料, EDA 幫助我們找出資料 insight , 理出真正的問題, 才能有對的, 好的解決方法, 不夠了解資料生不出 powerful features(find new feature, find magic feature), 不會有 accrate model.
這一週會提到 Pandas, Matplotlib, 他們都是視覺化的好工具, 視覺化重點在立即看出 patterns, 並且運用 pattern 去做出更好得 model.
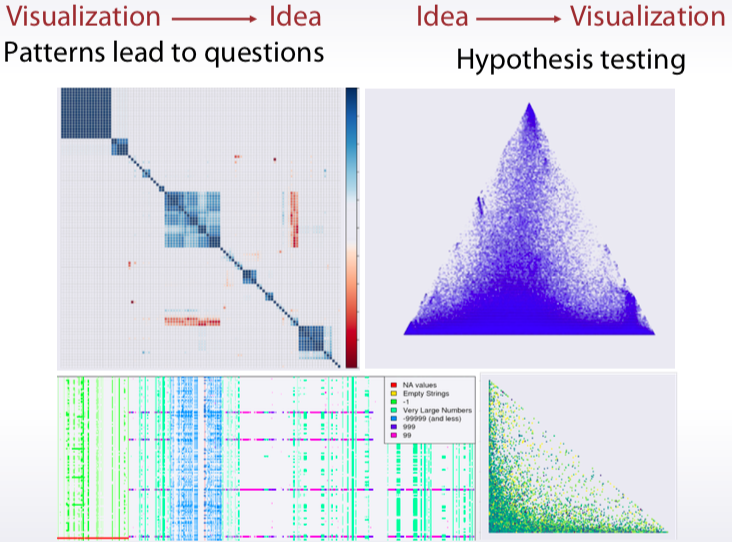
截圖自coursera
Do EDA first, Do not immediately dig into modeling.
三步驟 :
[https://eyusuwbavdctmvzkdnmwro.coursera-apps.org/notebooks/readonly/reading_materials/EDA_video2.ipynb]
以Google adwords為例
注意 test and train 欄位數不同 -- target 是 Cost 欄位, 留意近似的欄位, 像 Clicks, Conversions. test set 刪掉很多相關欄位
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
data_path = './data'
train = pd.read_csv('%s/train.csv.gz' % data_path, parse_dates=['Date'])
test = pd.read_csv('%s/test.csv.gz' % data_path, parse_dates=['Date'])
train.head().T
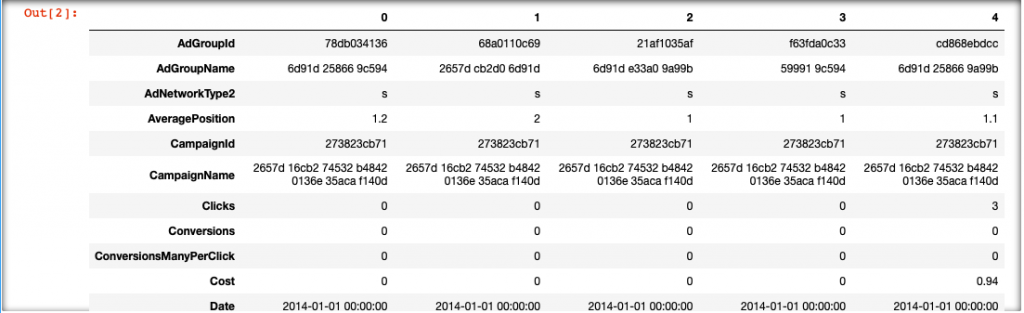
test.head().T
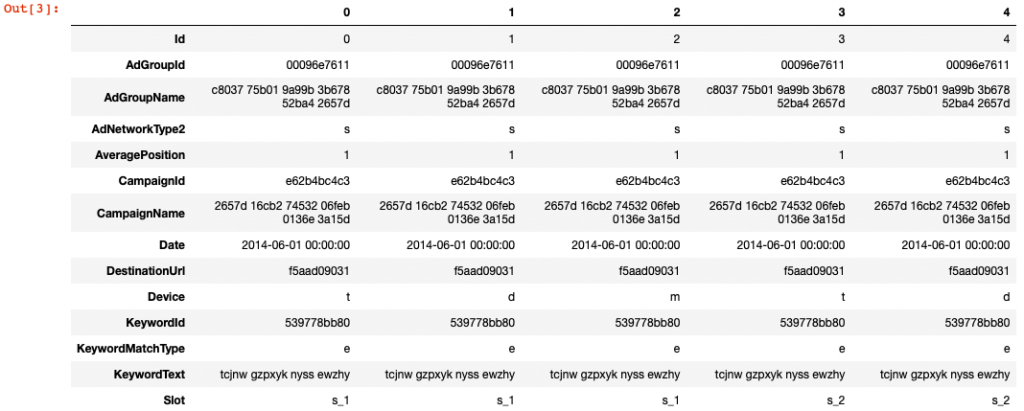
別急著跑 model, 要記得老師說的要仔細研究 data
print 'Train min/max date: %s / %s' % (train.Date.min().date(), train.Date.max().date())
print 'Test min/max date: %s / %s' % ( test.Date.min().date(), test.Date.max().date())
print ''
print 'Number of days in train: %d' % ((train.Date.max() - train.Date.min()).days + 1)
print 'Number of days in test: %d' % (( test.Date.max() - test.Date.min()).days + 1)
print ''
print 'Train shape: %d rows' % train.shape[0]
print 'Test shape: %d rows' % test.shape[0]
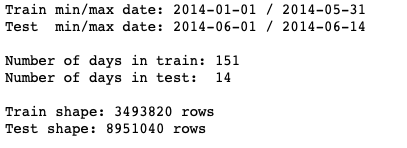
發現了什麼嗎? train set 比 test set 整整大了 10 倍, 能再做的就是深入調查緣由. 有興趣的可以直接點選上面連結的文章, 狄米崔老師有很詳細的調查經過在 reading materal https://eyusuwbavdctmvzkdnmwro.coursera-apps.org/notebooks/readonly/reading_materials/EDA_video2.ipynb#Investigation.

