
斷捨離無用的特徵, train set 跟 test set 的特徵值一模一樣,也只是在佔記憶體位置, 對 model 沒有幫助下, 最好方法就是移除它, 例如 f0 欄位(特徵)在train set 跟 test set 的值都一樣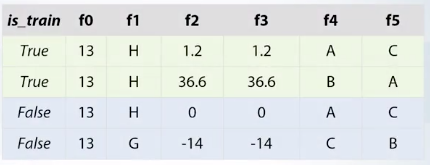
截圖自coursera
traintest.nunique(axis=1) == 1
沿用上圖, f2, f3 則是兩個一模一樣的特徵, 一樣的, 最好方法就是移除它
traintest.T.drop_duplicates()
沿用上圖, f4, f5 是重複的類別型 categorical features, 例如 f5 的 C變A, A變B, B變C, 那就變得跟 f4 一模一樣了. 但怎麼找出來, 可以用 label encoding. 做法是 encode 但是 f4 top down, f5 bottom up
| encode | f4 | f5 |
|---|---|---|
| A | 1 | 3 |
| B | 2 | 2 |
| C | 3 | 1 |
for f in categorical_feats:
traintest[f] =raintest[f].factorize()
traintest.T.drop_duplicates()
Seaborn https://seaborn.pydata.org/
Plotly https://plot.ly/python/
Bokeh https://github.com/bokeh/bokeh
ggplot http://ggplot.yhathq.com/
Graph visualization with NetworkX https://networkx.github.io/
Others
Biclustering algorithms for sorting corrplots http://scikit-learn.org/stable/auto_examples/bicluster/plot_spectral_biclustering.html
