舉例: 醫療保健公司目標是改善患者的生活,我們可以預測患者是否會在不久的將來被診斷為某種疾病。
因此, 創建的 model 必須能適用於未來, 包括掌控 model 的犯錯數量及確保品質. 對於過去的患者訓練數據集和未來未知的患者測試數據不同, 會取決於我們確實掌控 model 的品質, 所以 train data 會切割部分作為 Validation / 驗證.

截圖自coursera
排行榜是 public 的, 而day 2曾提過的 private 是為了保有競爭精神不會公開, 若在 排行榜因 overfitting 獲得好成績, 但是 private 卻下滑. 因此 underfitting 欠擬合和overfitting 過度擬合的拿捏很重要
模型過於簡單, 無法捕獲線下方, 而得到較差的結果。這被稱為 underfitting 欠配合。若希望結果得到改善,可增加模型的複雜性,但可能會發現訓練數據的品質下降。機器學習中 overfitting 過度擬合的含義以及 overfitting 過度擬合競爭的含義略有不同。
右圖 overfitting 若製作過於複雜的模型,他將開始描述訓練數據中的 noise 噪音,而不會應用在測試數據。這將導致 model 品質下降。這稱為 overfitting 過度擬合。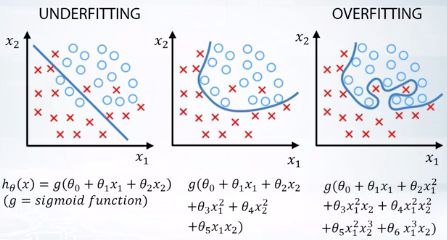
截圖自coursera
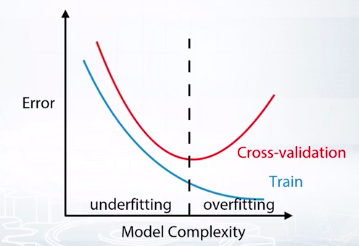
截圖自coursera

