今天就來玩玩TensorFlow Playground這個平台吧,這個平台一開始可以在左邊選擇想要data與batch size來做設定,接著到features這裡可以設定輸入有幾個,接著增加隱藏層最後輸出一個視覺化的圖像。
在上放可以設定Epoch、學習速率、激活函數、正規化、正規化參數。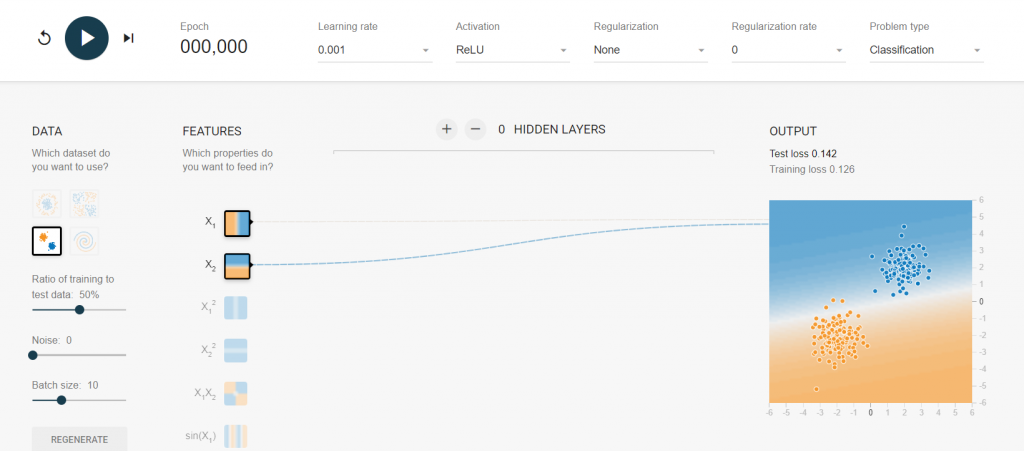
以下是我將學習率從0.001~1跑一個Epoch所呈現的結果,可以很明顯的看到學習速率越大,收斂的時間會越快。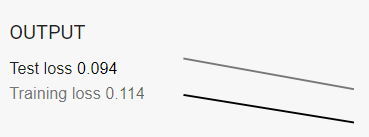
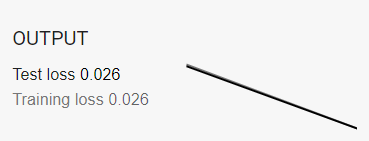
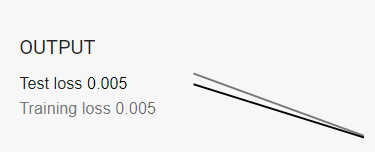
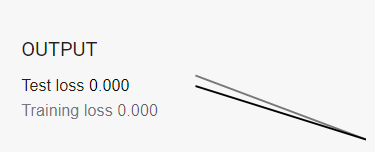
當然如果今天我們的數據並不像上面那張圖那麼漂亮怎麼辦呢?假設是萬橘叢中一點藍要怎麼做分類呢?其實概念完全一模一樣,今天是因為我們在平面看到的圖像感覺不能用一條直線去做區分,那如果今天我把它變成立體的呢?是不是可能會找到一個平面去將它做分割,官網還有很多其他的圖形可以給大家做嘗試這邊我先舉底下這個例子做為參考,當然也可以調整Batch size、Hidden layer、neurons、加入更多的輸出等條件來看看不同輸入的輸出結果。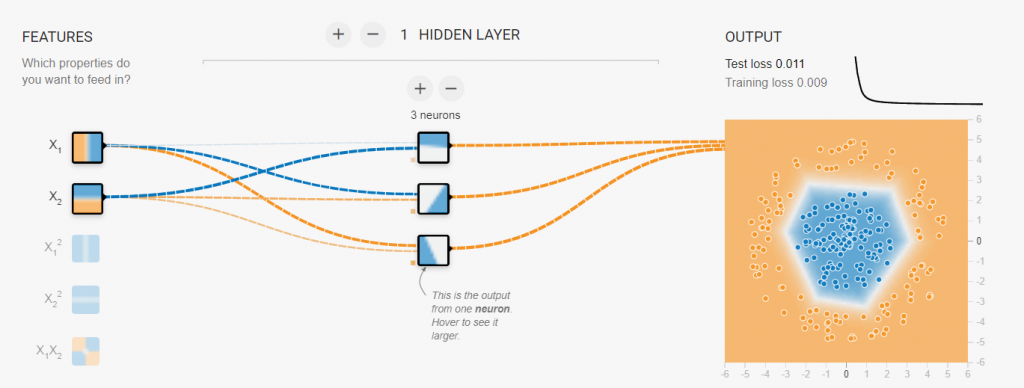
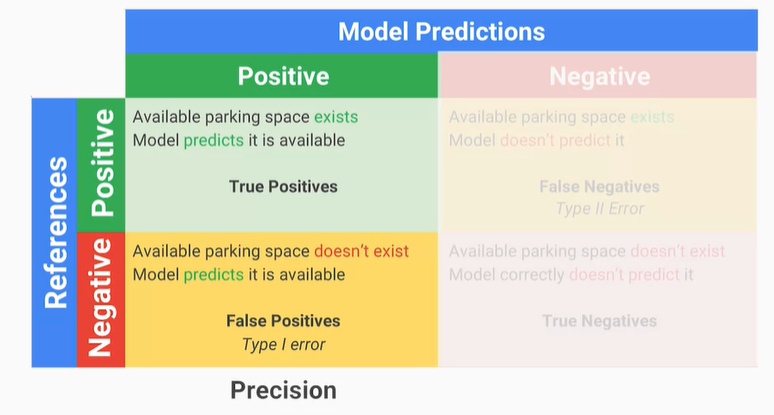
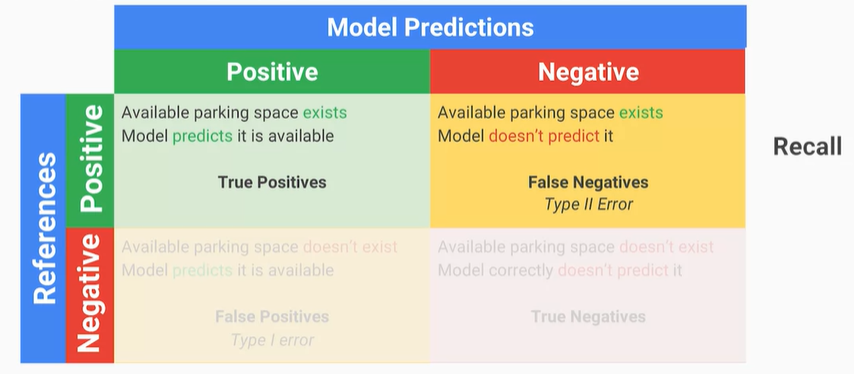
有了這些方法後,要怎麼實際評估模型的好壞呢?之前就有稍微提到一下,也就是混淆矩陣跟前面不太一樣,有兩個專有名詞Precision、Recall,用來定義模型優劣。
Precision是在預測正向的狀況下,正確的機率有多少,也就可以把它想成精準度的一種方式,舉個例子假設今天停車場有空位且Precision趨近於1,那就表示實際上停車場有空位;反之可能模型預測有空位但實際到現場是沒空位的。
Recall是實際狀況是正向的情況下,模型可以召回多少正確答案的狀況,一樣使用停車的例子,如果Recall趨近於1,那麼就代表找到可用的停車場空位就是都可以用的;反之就是明明有位子但模型跟我說沒有,也可以把它想成所謂的誤報機率。
※圖片參考至 Launching into Machine Learning slide