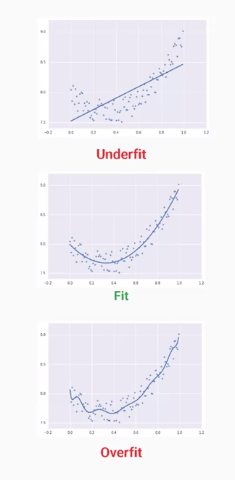
在介紹這次實驗之前,有幾個滿重要的觀念以及技巧要先提及,第一個就是有關如何利用圖形來判別此次的結果是否可以使用,大多會分為三種underfitting、fitting、overfitting,其中只有fitting是可以使用的,另外兩個叫做欠擬合、過擬合,很好理解的是過擬合就是太符合實驗數據,如果有新的資料進來就很有機會判斷錯誤,因為它能判斷其訓練的數據。
而欠擬合顧名思義就是欠缺擬合,就是連訓練資料丟進去他都不知道是甚麼,這種模型你敢用嗎ㄏㄏ?
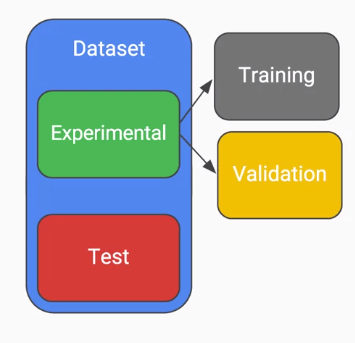
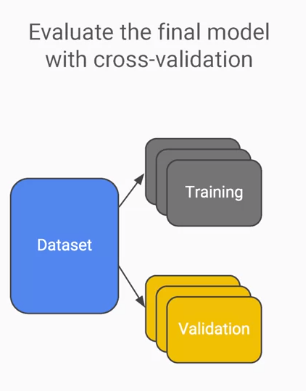
另外一個觀念就是dataset的設置,很重要的一點就是我們必須把所有資料集分成兩塊,一組是實驗數據、一組是測試數據,這樣分別的原因是為了不讓測試數據參雜實驗數據進而在預測的時候影響其結果;接著必須再將實驗數據分成訓練與驗證,做這個的目的主要為了在訓練的時候,能夠避免過擬合的情況發生,因為全部都是訓練資料模型就只會解同樣的問題,更好的方式是加入cross-validation的觀念,在訓練時輪流使用測試與驗證集,確保模型都學會所有數據集藉此提高準確率。
接著開始介紹實作部分,此次要做實驗的主題是Lab: Creating Repeatable Dataset Splits in BigQuery。這個實驗最主要的目的也就是希望我們利用GCP平台來進行資料的分類。
第一步就是要創建一個AI平台,並且要需有編輯程式碼功能
進入畫面後要來設定相關規格
等待一段時間就可以看到有一個選項OPEN JUPYTERLAB
git clone https://github.com/GoogleCloudPlatform/training-data-analyst下載教材
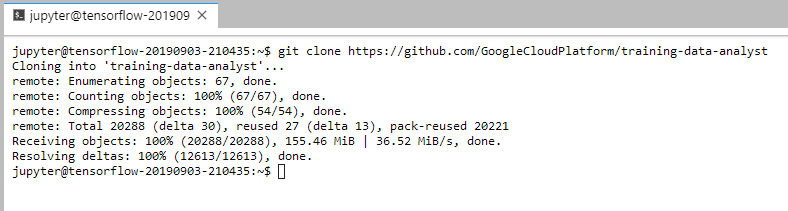
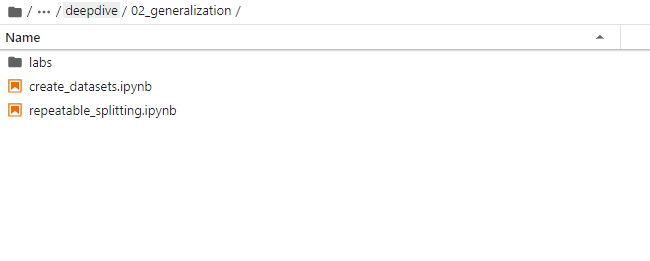
接著切換至training-data-analyst > courses > machine_learning > deepdive > 02_generalization路徑下
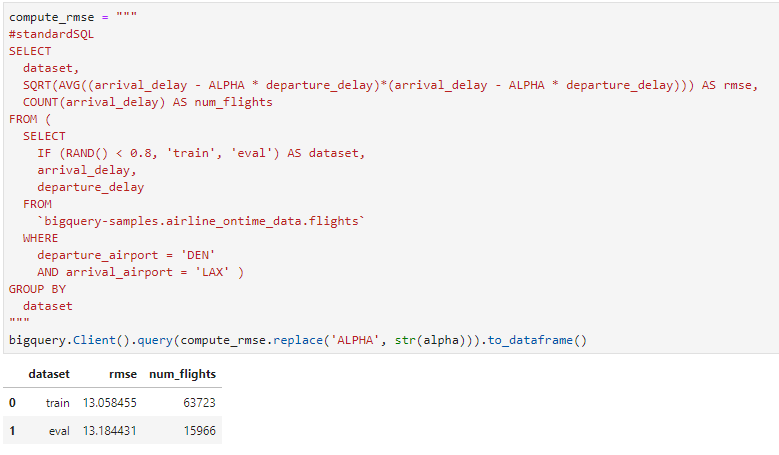
首先匯入BigQuery套件from google.cloud import bigquery
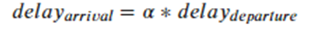

接著利用BigQuery來抓取資料
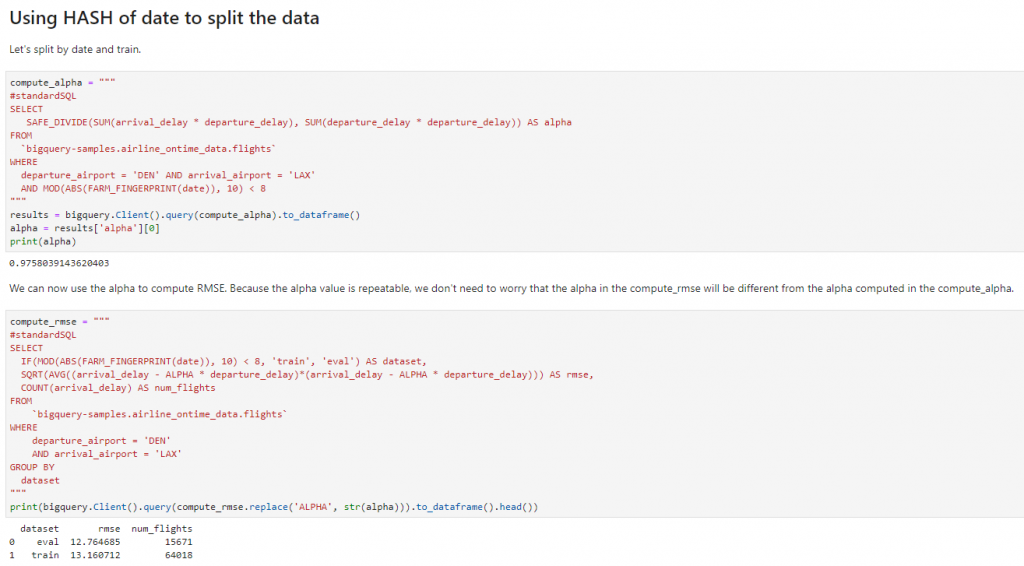
RAND()函數來進行隨機分配,但會發現一個非常明顯的問題,仔細看下列數字α,會發現其實每次執行結果都會不一樣,這個原因就是使用RAND()函數,它是從0~1隨機取一個數值來進行切割。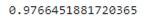
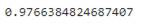
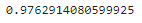
但這樣對於我們實驗的數據有甚麼影響呢?
HASH的方式來做切割,這邊作者是使用date取得的時間進行切割,因為時間數據時間並不會一直變,所以可以看到結果,α並不會因為我一直重複執行而有所改變,並且分割的資料集每次都會一樣,這才是我們真正想要的分割方式。※圖片參考至 Launching into Machine Learning slide