
又出現一個新的東西了Dataprep,這邊先簡單講一下他有點像是能夠圖像化呈現數值,並且找到一些關鍵的統計數據,在這實驗當中我們會仔細去做使用,那這次的實驗是使用之前常用到的出租車的數據集利用Dataprep來做量化,並且透過各種篩選的方式來取的我們所需的數值
第一步先創建做為儲存使用的Bucket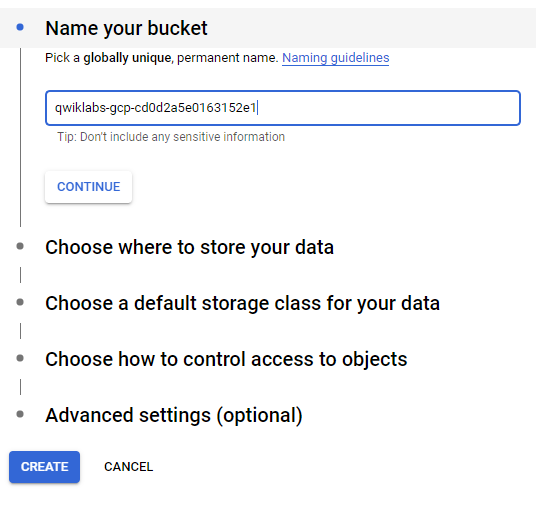
接著創建到BigQuery頁面選擇創造一個新的Dataset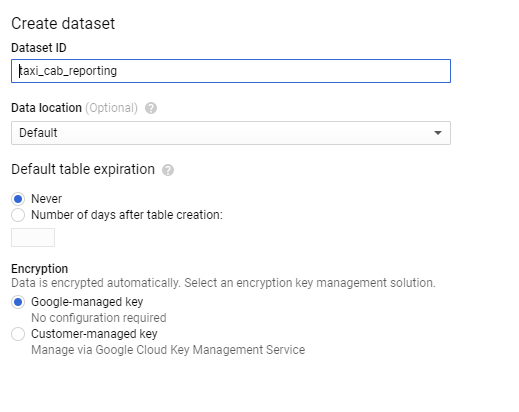
連接到Dataprep,並且予許Dataprep做存取
進入到畫面後必須選擇存放資料的位置(選擇Bucket位置)
建置完成後接著創建flows,並給予名稱與描述
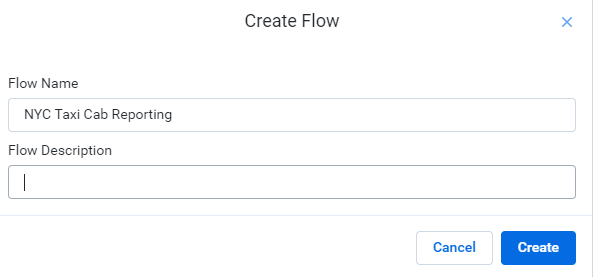
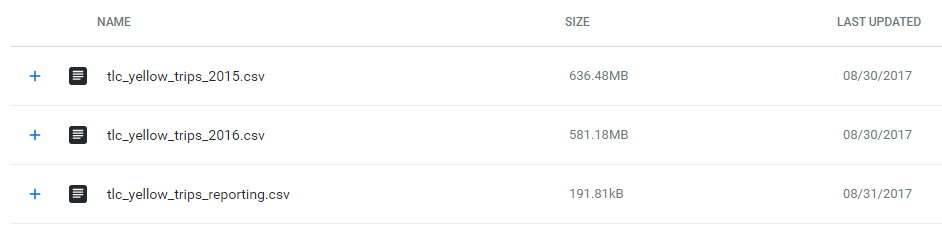
新增dataset,這邊選擇GCS裡面有搜尋asl-ml-immersion/nyctaxicab選擇要的檔案做加入,這邊選擇2015、2016年的資料,點選加入資料

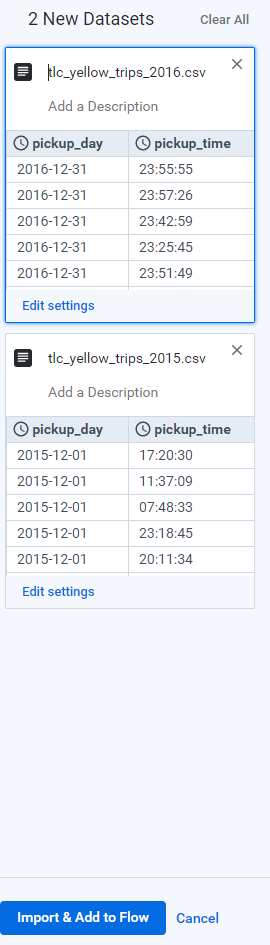
匯入進來後選擇Add new Recipe,就可以進行編輯動作了
接著要將兩筆資料集作加入,這邊看到的是兩筆分開的資料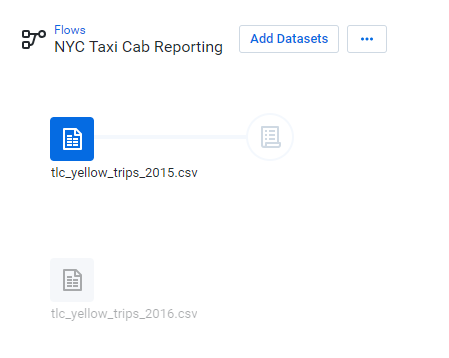
選擇Add Step,輸入union,選擇要加入的檔案,我們可以從pickup_day可以看到變成兩筆了確定有正確匯入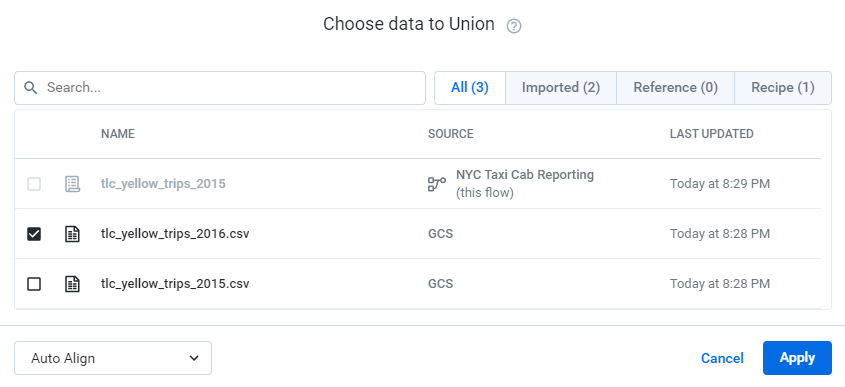
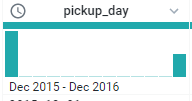
接著可以利用merge把年份跟時間連結起來,變成新的colunm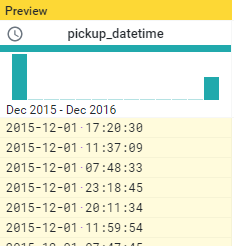
加入derive進行運算,這邊將日期與時間中間的符號拿掉,生成新的一欄,,為了識別為DATETIME同時可以增加分、秒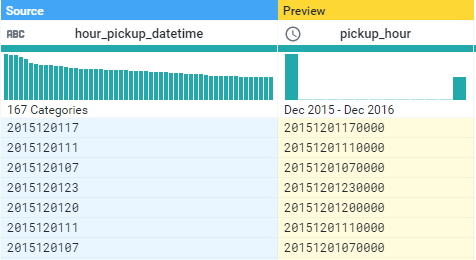
利用AVERAGE來計算fare_amount的平均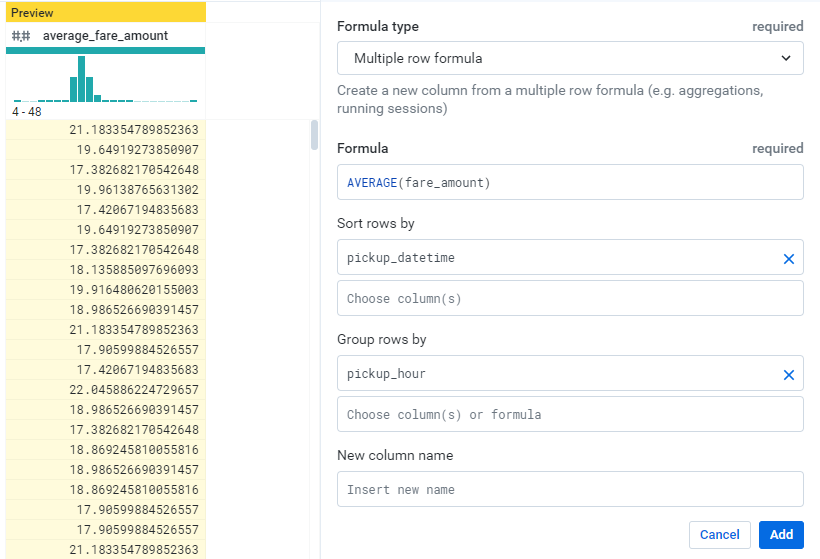
輸入window來計算他的移動平均數,這邊設定三小時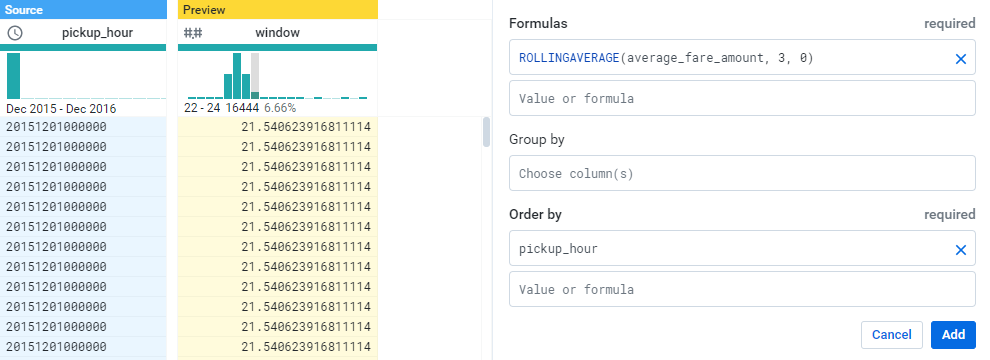
做完上述的動作後,啟動這個工作按下run job
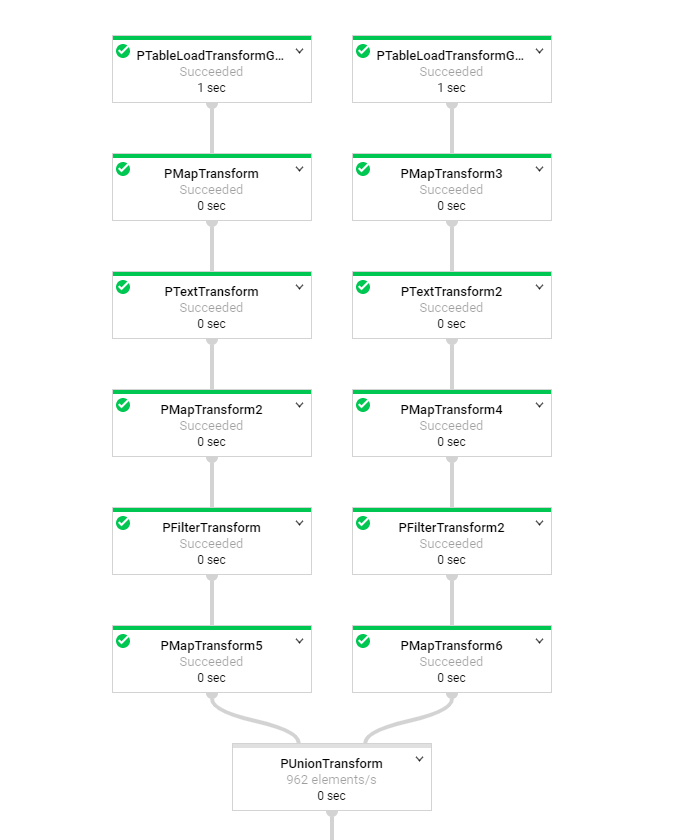
最後若是希望在BigQuery做查詢
#standardSQL
SELECT
pickup_hour,
FORMAT("$%.2f",ROUND(average_3hr_rolling_fare,2)) AS avg_recent_fare,
ROUND(average_trip_distance,2) AS average_trip_distance_miles,
FORMAT("%'d",sum_passenger_count) AS total_passengers_by_hour
FROM
`asl-ml-immersion.demo.nyc_taxi_reporting`
ORDER BY
pickup_hour DESC;
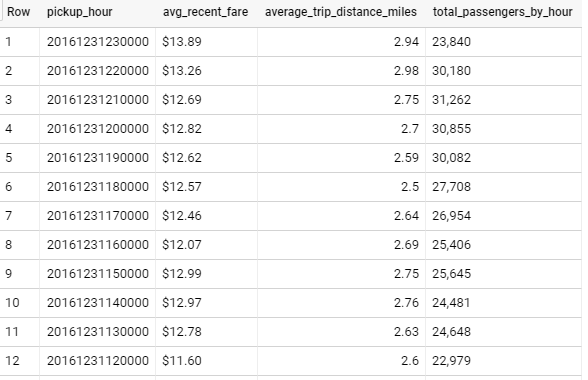
這邊最主要的觀念就是透過視覺化的架構建構出屬於自己的資料集
而Dataprep在這邊就是非常好用的一套系統
在GCP平台上進行特徵的選擇、製作,比起人工的方式上述這些方法是會比較容易去理解與使用
