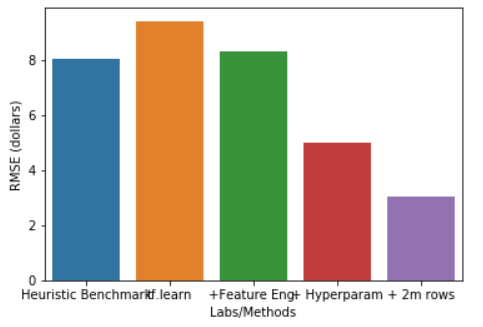
那這些觀念實際上應用要怎麼使用呢???此次實驗最主要的目的是要預估我們之前常講的出租車例子,要怎麼利用加入Feature Crosses觀念來提高我模型的準確率,一樣先創建bucket、notebooks接著切換至training-data-analyst> courses> machine_learning> deepdive> 04_features>taxifeateng 打開 feateng.ipynb,開始進行實驗。
import os
PROJECT = 'xxx' #改成自己的資訊
BUCKET = 'xxx'
REGION = 'xxx'
接著定義要如何在bigquery中獲取資料,並且先將相關資料做篩選,像是經緯度的設置、費用的多寡、時間或日期等資訊,接著將資料利用hash function分為train、valid、test的資料集。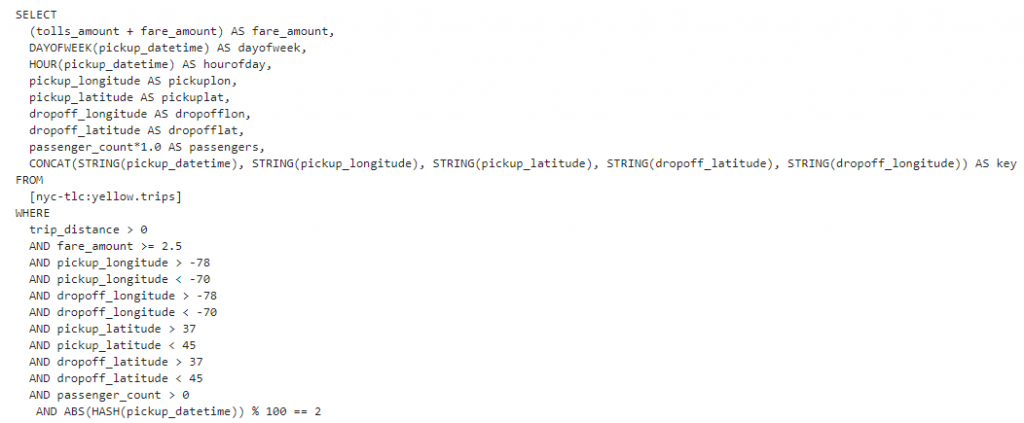
從bigquery抓取資料後,在本地端創造pipeline進行預處理的dataflow job批次取的資料,同時定義所要的csv格式,最後儲存到bucket中,我們在bucket中就可以看到相關資訊了。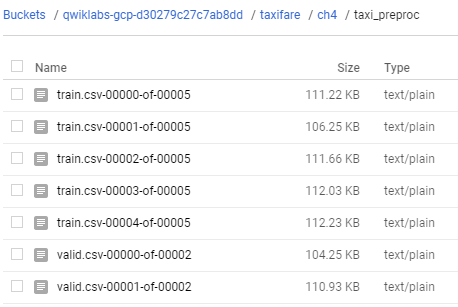

有另外一種方式可以利用Cloud Dataflow來進行抓取,用這個方式的好處是可以視覺化的呈現結果在GCP上,對於我們如果要看相關的資訊可以從這個地方更完整來獲得。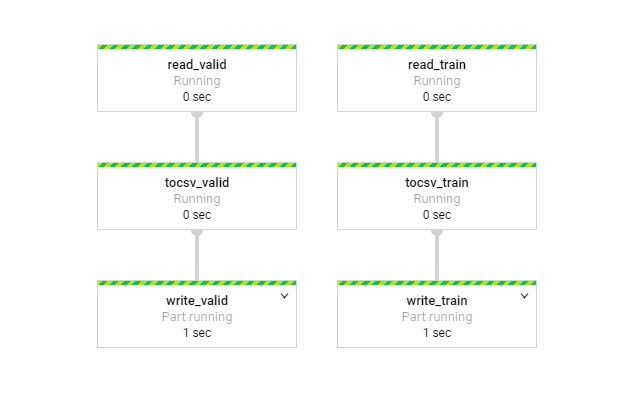
接著我們要將這些資料拿到tensorflow來做運用
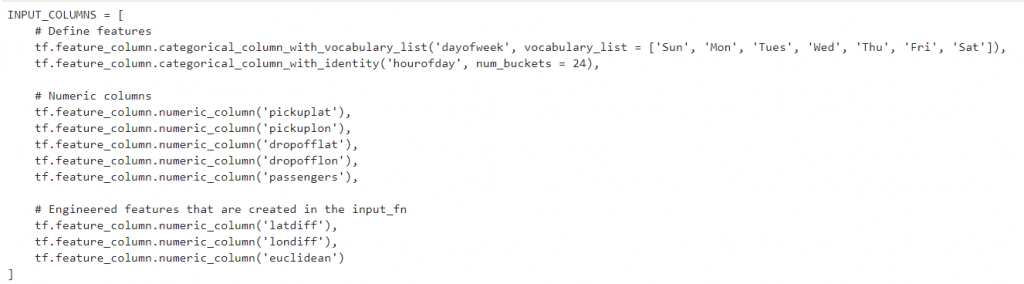


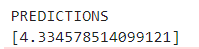
{"dayofweek": "Sun", "hourofday": 17, "pickuplon": -73.885262, "pickuplat": 40.773008, "dropofflon": -73.987232, "dropofflat": 40.732403, "passengers": 2}
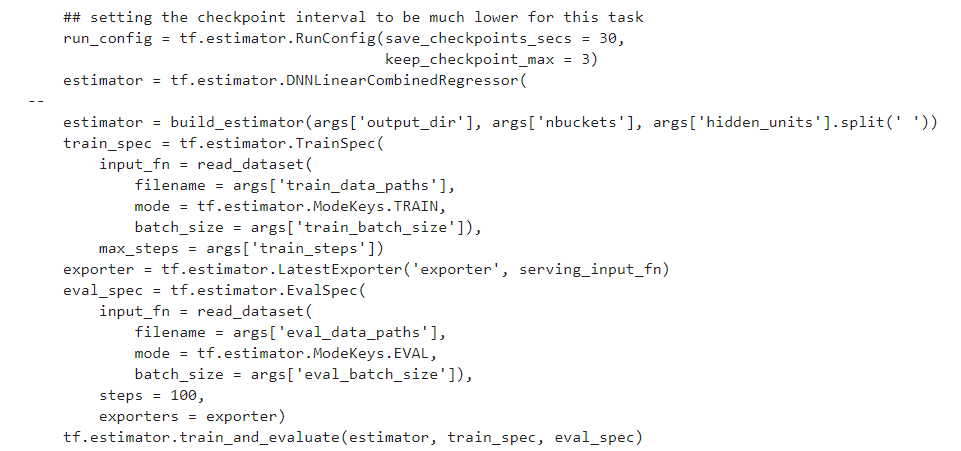
以上的所有步驟都能夠放置於GCP進行運算,不過路徑要改成bucket位置,步驟跟上面的方法一模一樣這邊就不在贅述
#gcloud ai-platform versions delete ${MODEL_VERSION} --model ${MODEL_NAME}
#gcloud ai-platform delete ${MODEL_NAME}
gcloud ai-platform models create ${MODEL_NAME} --regions $REGION
gcloud ai-platform versions create ${MODEL_VERSION} --model ${MODEL_NAME} --origin ${MODEL_LOCATION} --runtime-version $TFVERSION
--train_steps = num_rows * num_epochs / train_batch_size
--train_batch_size=512 --nbuckets=16 --hidden_units="64 64 64 8"