我想大家對於轉換數值或是改變型態都會有所疑問,首先講一個很簡單的觀念
今天在現實生活中有星期一到星期天,但電腦裡並沒有,難道你希望他周休二日嗎??
所以淺而易見的電腦並不知道有關於字串的訊息,所以你必須去將它轉換成數字格式
另外有些人又會納悶我都已經是數字那為什麼還要轉換成0~1的區間
這個道理很簡單我們都知道電腦做運算就是利用加減乘除的方式
今天希望它算1~100的所有數值相乘然後相加,你覺得先除上100在做運算跟直接做運算哪個比較快?
電腦做運算都是使用0、1來當標準,跟人類一樣當然要用熟悉的語言才會做得快啊
這就是為什麼我們即便是數值了,還要做轉換的原因
這次實驗室要使用TensorFlow內部的transform,來實作出特徵預處理、創造特徵等功能,並且有效率的處理大規模的串流數據,跟昨天一樣先創建bucket、notebooks接著切換至training-data-analyst> courses> machine_learning> deepdive> 04_features>taxifeateng 打開 tftransform.ipynb,開始進行實驗。
首先第一步當然是要安裝相關的套件,接著重新啟動kernel,並且輸入pip freeze跟flow\|beam中做比較,基本上兩邊要一樣,才不會有問題。
接著就設定相關位置與資訊,進行環境的建置。
import os
PROJECT = 'xxx' #改成自己的資訊
BUCKET = 'xxx'
REGION = 'xxx'
import os
os.environ['BUCKET'] = BUCKET
os.environ['PROJECT'] = PROJECT
os.environ['REGION'] = REGION
%%bash
gcloud config set project $PROJECT
gcloud config set compute/region $REGION
下一步驟當然是要抓取資料,這邊是到bigquery進行蒐集,基本上跟之前一樣都是使用出租車的數據集
head()、describe()來查看資料的分布與數量是否正確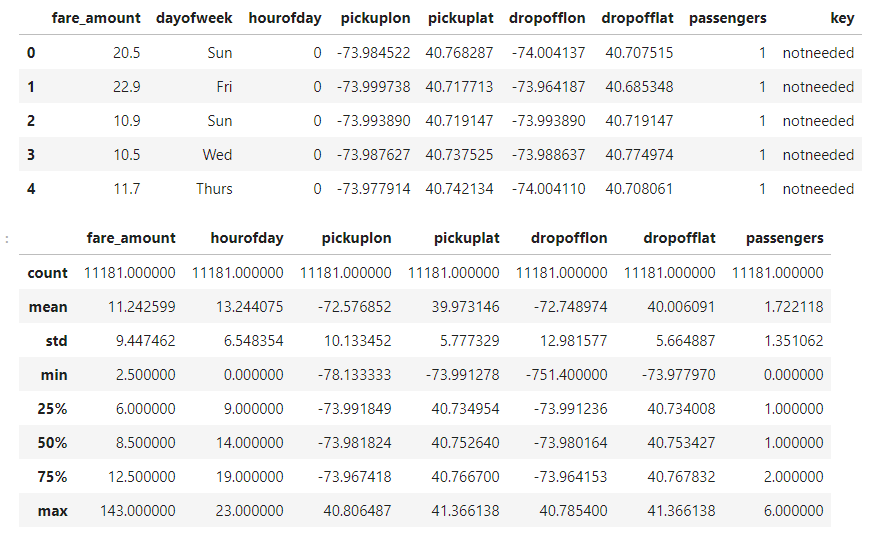
接下來也就是實做tf.transform的功能
tensorflow-transform寫入requirements.txt中確保在dataflow裡都是一樣的版本%%writefile requirements.txt
tensorflow-transform==0.8.0
return (fare_amount >= 2.5 and pickup_longitude > -78 and pickup_longitude < -70 \ and dropoff_longitude > -78 and dropoff_longitude < -70 and pickup_latitude > 37 \ and pickup_latitude < 45 and dropoff_latitude > 37 and dropoff_latitude < 45 \ and passenger_count > 0)
tft套件來進行資料的轉換tft.string_to_int # 字串轉換成數字
tft.scale_to_0_1 # 縮放置0~1
tf.cast # 更該資料型態
raw_data_schema =
{
colname : dataset_schema.ColumnSchema(tf.string, [],dataset_schema.FixedColumnRepresentation())
for colname in 'dayofweek,key'.split(',')
}
raw_data_schema.update({
colname : dataset_schema.ColumnSchema(tf.float32, [], dataset_schema.FixedColumnRepresentation())
for colname in 'float 參數'.split(',')
})
raw_data_schema.update({
colname : dataset_schema.ColumnSchema(tf.int64, [], dataset_schema.FixedColumnRepresentation())
for colname in 'int 參數'.split(',')
})
最後將其檔案進行訓練
最後這邊在訓練的過程中有發生一點問題,所以就沒放上圖片,但基本上概念都跟我們之前講的利用雲端跟本地端的方法預測結果一樣,若有實驗成功的朋友也歡迎跟我分享。
今天是國慶日先祝台灣生日快樂、世界和平

