
除了Day03討論過的獨熱編碼與標籤編碼兩種基礎編碼方式,均值編碼也是另一種類別型特徵常用的編碼方式。一般處理類別型特徵預設採用標籤編碼,除非該特徵重要性高,且可能值較少時,才考慮使用獨熱編碼。而當類別特徵與目標值明顯相關時(如地區與房價),則可考慮使用均值編碼。
We discussed one-hot encoding and label encoding in the Day03 article, other than those two methods, mean encoding is also used sometimes when dealing with categorical features. Normally, we use label encoding as default while dealing with categorical data, and only use one-hot encoding when the feature is important and the data is not too large (otherwise it’s going to be too computationally expensive). And we could consider to use mean encoding when the feature is highly related to target the values (like areas and housing price range).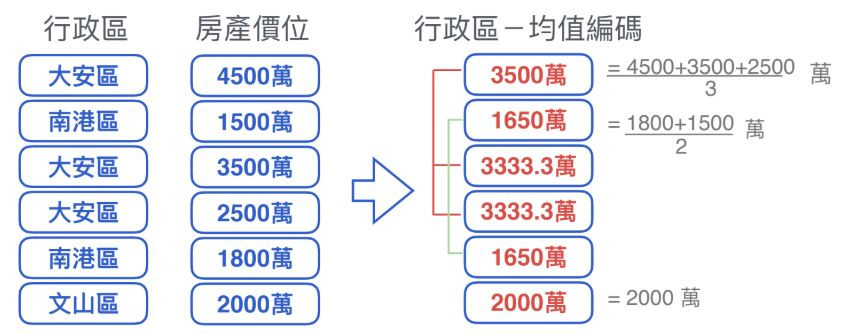
使用目標值欄位的平均值取代原本的類別型特徵。需注意實際上使用時很容易過擬合,即使平滑化後(過擬合指模型適應訓練資料中太特化又隨機的特徵,特別是發生在學習過程太久或範例太少時,造成模型完美貼合訓練資料,但實際應用在未知資料卻表現不佳)。
Using the mean of the target values to replace the original categorical features. One thing need to be careful with this method is really easy to overfit the data even after smoothing (overfitting happens when the model learned with not enough data or for a too long period of time, the model ended up fit perfectly with the training data but fail to perform well on new unknown data).
如果樣本非常少並剛好抽到極端值,平均的結果可能具有很大誤差,因此均值編碼還需要考慮資料紀錄筆數,作為可靠度的參考。
加入可靠程度作為考量,當可靠度低時,傾向相信全部資料的總平均;當可靠度高時,則會傾向相信該類別的平均。
If we only have very a little dataset and we accidently chose an extreme value will end up getting a mean value with deviation. So we add in the counts of the values as reliability when using mean encoding.
When the reliability of the target value is low, we tend to trust the mean of all the data more; while when the reliability is high, we then tend to use the mean of the mean of that category.
本篇程式碼請參考Github。The code is available on Github.
文中若有錯誤還望不吝指正,感激不盡。
Please let me know if there’s any mistake in this article. Thanks for reading.
Reference 參考資料:
[1] 第二屆機器學習百日馬拉松內容
[2] 過適

 iThome鐵人賽
iThome鐵人賽