
在Day14的文章中我們討論到判讀資料的偏態,當資料中離群資料比例很高,或平均值沒有代表性時,便可考慮使用以下面幾種方式去除偏態:
In the Day14 article we talked about skewness. When the ratio of outlier is high or the mean cannot represent the data well, we could use the following methods to reduce skewness.
以Kaggle競賽Titanic: Machine Learning from Disaster作為使用的資料集演示。
We will use the data downloaded from Titanic: Machine Learning from Disaster for the example.
import pandas as pd
import numpy as np
import copy
df = pd.read_csv('data/train.csv') # 讀取檔案 read in the file
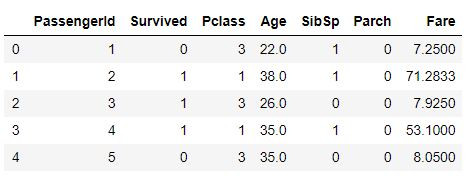
df.head() # 顯示前五筆資料 show the first five rows

# 只取int64, float64兩種數值型欄位存到 num_features中
# save the columns that only contains int64, float64 datatypes into num_features
num_features = []
for dtype, feature in zip(df.dtypes, df.columns):
if dtype == 'float64' or dtype == 'int64':
num_features.append(feature)
print(f'{len(num_features)} Numeric Features : {num_features}\n')
# 去掉文字型欄位,只留數值型欄位 only keep the numeric columns
df = df[num_features]
df = df.fillna(0)
df.head()
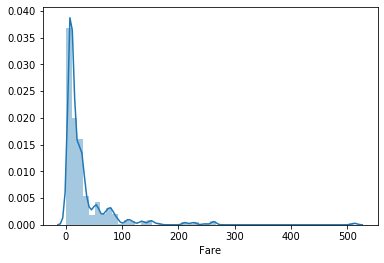
# 顯示Fare的分布圖 plot out the distribution of Fare
import seaborn as sns
import matplotlib.pyplot as plt
sns.distplot(df['Fare'])
plt.show()
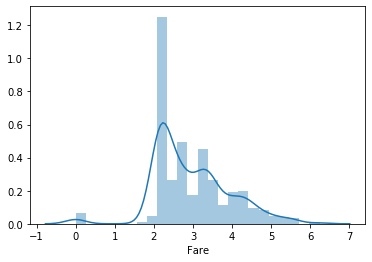
# 將Fare取log1p,看分佈圖 plot out Fare after log1p
df_fixed = copy.deepcopy(df)
df_fixed['Fare'] = np.log1p(df_fixed['Fare'])
sns.distplot(df_fixed['Fare'])
plt.show()
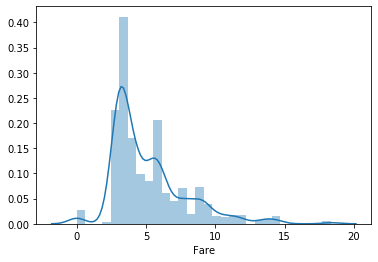
# 取boxcox後看分佈圖 plot out Fare after boxcox
from scipy import stats
df_fixed = copy.deepcopy(df)
df_fixed['Fare'] = df_fixed['Fare'] +1 # 最小值接近-1,先加1做平移 minimum close to -1, add 1 first
df_fixed['Fare'] = stats.boxcox(df_fixed['Fare'], lmbda=0.3)
sns.distplot(df_fixed['Fare'])
plt.show()
本篇程式碼請參考Github。The code is available on Github.
文中若有錯誤還望不吝指正,感激不盡。
Please let me know if there’s any mistake in this article. Thanks for reading.
Reference 參考資料:
[1] 第二屆機器學習百日馬拉松內容
[2] Titanic: Machine Learning from Disaster
