插播一下林軒田老師對正規化(Regularization)的想法,就是 overfitting 發生時,有可能是因為訓練的假設模型本身就過於複雜,能不能讓複雜的假設模型退回至簡單的假設模型呢?這個退回去的方法就是正規化。
換言之, Regularization 正規化就是保留所有的特徵值,降低參數數字,減弱較不重要的特徵值。
回到 coursera 的教材, mean encoding 跟 label encoding 比較
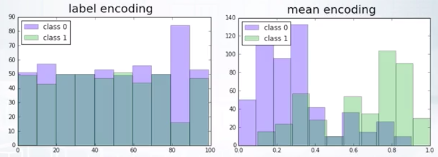
截圖自Coursera

截圖自 Coursera
以 α 超参数控制正規化數量, α 為 0時無正規化, 當 α 趨近無窮大, 就變成 globalmean. 因此 α 可視為可信任的類别大小, 在逞罰類別的做法都可視為 smoothing.
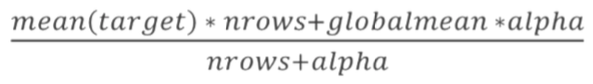
截圖自 Coursera
通常搭配 LOO (Leave-one-out) 一起, 有 4 特點
cumsum = df_tr.groupby(col)['target'].cumsum() - df_tr['target']
cumcnt = df_tr.groupby(col).cumcount()
train_new[col + '_mean_target'] = cusum/cumcnt

