上一篇我們介紹了『購物籃分析』,可以幫公司建立商品組合,也可以推薦商品給顧客,它單純依據銷售記錄進行分析,但是,如果是線上網購,瀏覽(Page View)也是一個關鍵的購買訊號,還有用戶評價(Rating)也能提供給商品推薦的有力依據,所以,我們就花幾天的時間好好來討論一下來看看『推薦系統』(Recommendation System 或稱 Recommender System) 。
推薦系統的類別主要分為下列三種:
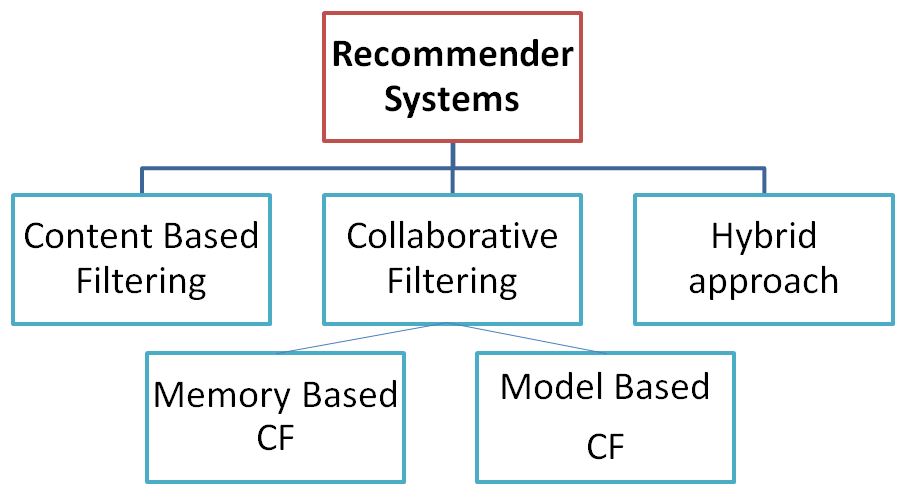
今天我們就先來介紹『以內容為基礎的過濾』(Content Based Filtering)的作法。
Content Based Filtering又分為兩種:
先舉一個簡單的例子說明,如果使用者之前看過幾部電影,發現他比較看漫威電影,那就應該推薦他看『復仇者聯盟』,而不是恐怖片,這是只有一個屬性的狀況,如果,我們有收集很多屬性資料,那該怎麼做呢? 請看下面範例說明。
我們以 Kaggle 的 TMDB 5000 Movie Dataset 為例,說明『以內容為基礎的過濾』(Content Based Filtering)的處理步驟。
資料集內含兩個檔案:電影基本資料(tmdb_5000_movies.csv)及演員/工作人員資料(tmdb_5000_credits.csv),我們要從這兩個檔案內的欄位找出相似的電影推薦給使用者,由於,檔案內多個欄位是Json格式,需要前置處理,將資料整理好。
以下程式來自這裡,筆者加了中文註釋,主要步驟如下: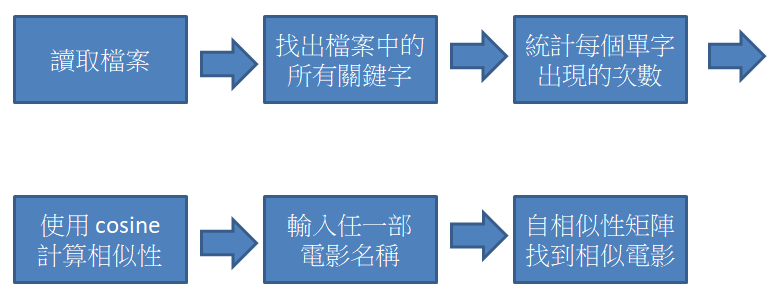
movies = pd.read_csv('./tmdb_5000_movies.csv')
credits = pd.read_csv('./tmdb_5000_credits.csv')
# Join datasets
credits.columns = ['id', 'title', 'cast', 'crew']
alldata = movies.merge(credits, on = 'id')
Json格式欄位處理,找出關鍵字、風格、演員、導演,這部份程式過於瑣碎,請參考 GitHub Repo 上完整的程式。
使用rake.extract_keywords_from_text()找出檔案中的所有關鍵字:去除停用詞(stop words)、標點符號(puntuation characters)後,剩下的單字。
# Initialize empty column
df['plotwords'] = ''
# function to get keywords from a text
def get_keywords(x):
plot = x
# initialize Rake using english stopwords from NLTK, and all punctuation characters
rake = Rake()
# extract keywords from text
rake.extract_keywords_from_text(plot)
# get dictionary with keywords and scores
scores = rake.get_word_degrees()
# return new keywords as list, ignoring scores
return(list(scores.keys()))
# Apply function to generate keywords
df['plotwords'] = df['overview'].apply(get_keywords)
# 將文件中的詞語轉換為詞頻矩陣
cv = CountVectorizer()
# 統計每個單字出現的次數
cv_mx = cv.fit_transform(df_keys['keywords'])
# create cosine similarity matrix
cosine_sim = cosine_similarity(cv_mx, cv_mx)
def recommend_movie(title, n = 10, cosine_sim = cosine_sim):
movies = []
# retrieve matching movie title index
if title not in indices.index:
print("Movie not in database.")
return
else:
idx = indices[title]
# cosine similarity scores of movies in descending order
scores = pd.Series(cosine_sim[idx]).sort_values(ascending = False)
# top n most similar movies indexes
# use 1:n because 0 is the same movie entered
top_n_idx = list(scores.iloc[1:n].index)
return df_keys['title'].iloc[top_n_idx]
# 找出Toy Story這部電影的前5部最相似的電影
recommend_movie('Toy Story', n = 5)
# 找出The Avengers這部電影的前10部最相似的電影
recommend_movie('The Avengers')
以上使用BOW,也可以改用 TF-IDF,有興趣的讀者可以參考這一篇『Building a Content Based Recommender System for Hotels in Seattle』。
本例是針對文字內容找出相似性,這種方法也可以適用於類別欄位或數值欄位,就不需使用BOW,直接作cosine similarity。這種作法單純以商品屬性作比對,並未考慮使用者的評價及交易狀況,推薦的商品可能是滯銷品,會造成使用者體驗欠佳,造成使用者對推薦的內容不信任。
適用時機:沒有使用者回饋的資料,只有商品屬性資料時使用。
缺點:只會推銷屬性相近的商品,不考慮商品暢銷與否,不考慮使用者的偏好。
如果我們有使用者評價資料,那就可以結合商品屬性資料,那就可以作矩陣相乘,產生使用者喜歡的商品屬性,之後,就可以按第一種作法進行相似性計算或進行統計,找出推薦的商品,結果出來後,記得刪除使用者已購買過的商品。
這部份的程式碼可參考 Coursera 『Recommendation Systems with TensorFlow on GCP』線上課程的Lab,礙於版權,不能與大家分享,說聲抱歉。
適用時機:有目前使用者的偏好,可結合商品屬性資料時使用。
缺點:若是新顧客,會造成無法推薦,這就是所謂的『冷啟動』(Cold Start)的問題,遇到這種狀況,可以回歸第一種作法。
下次我們來看看另一種更普遍的推薦方法 -- 協同過濾(Collaborative Filtering),集合眾人的意見,進行推薦。
相關程式碼放在這裡的 Day07 Content Based Filtering 目錄。


 iThome鐵人賽
iThome鐵人賽