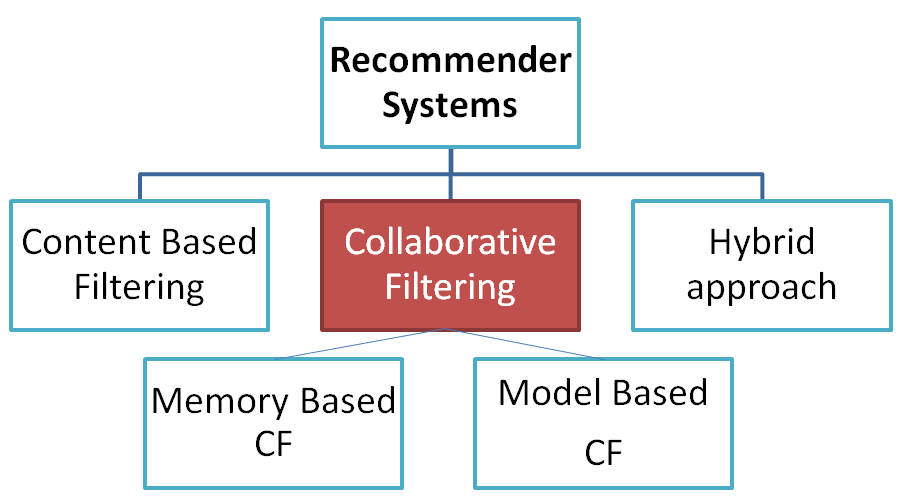
顧名思義,協同過濾(Collaborative Filtering),協同就是集合眾人的意見協同合作,進而篩選或推薦商品,作法與購物籃分析類似,一樣是以銷售記錄進行分析,不同的是,並不進行商品組合分析,而是將銷售記錄轉成『使用者/商品對應的矩陣』(User-Item Matrix),如下圖,記錄哪些使用者買過哪些商品,計算顧客間或商品間的相似度,再推薦相似顧客曾買過的商品,或推薦與目前商品最相似的其他商品,進行 cross selling。
註:以下圖片來源均來自 How to Build a Recommender System。
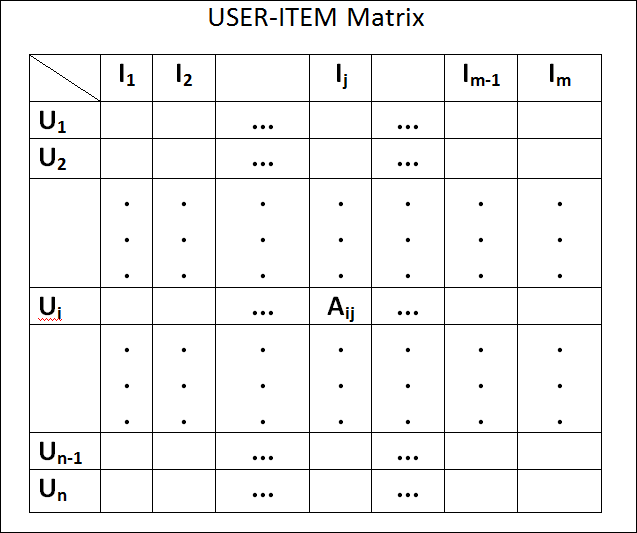
圖. User-Item Matrix
USER-USER 協同過濾:轉換為最相似的顧客族群(USER-USER Similarity Matrix),查看他們經常購買的商品,推薦給目前鎖定的顧客。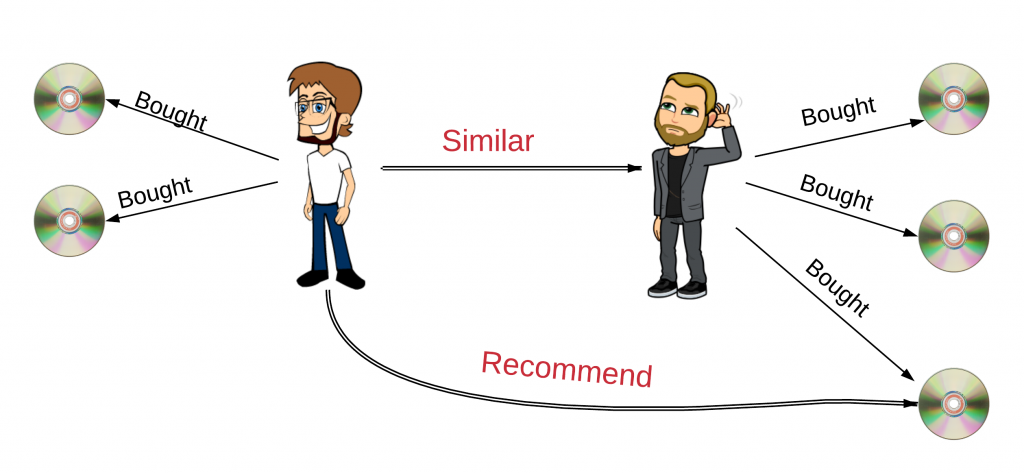
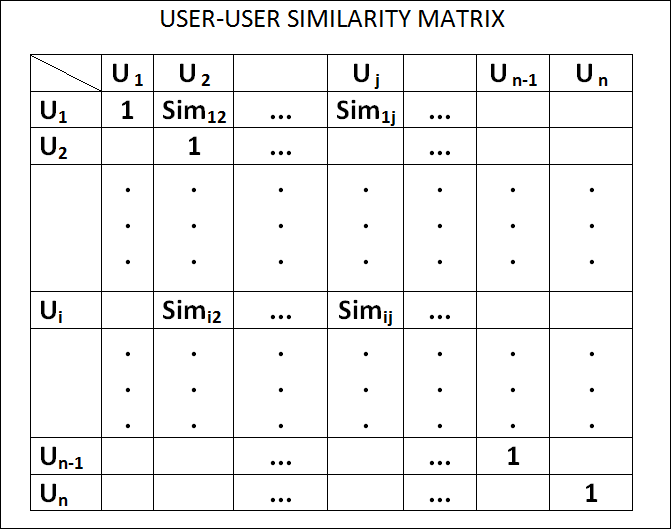
圖. USER-USER Similarity Matrix
ITEM-ITEM 協同過濾:找出與目前瀏覽的商品最相似的商品族群(ITEM-ITEM Similarity Matrix),推薦給顧客。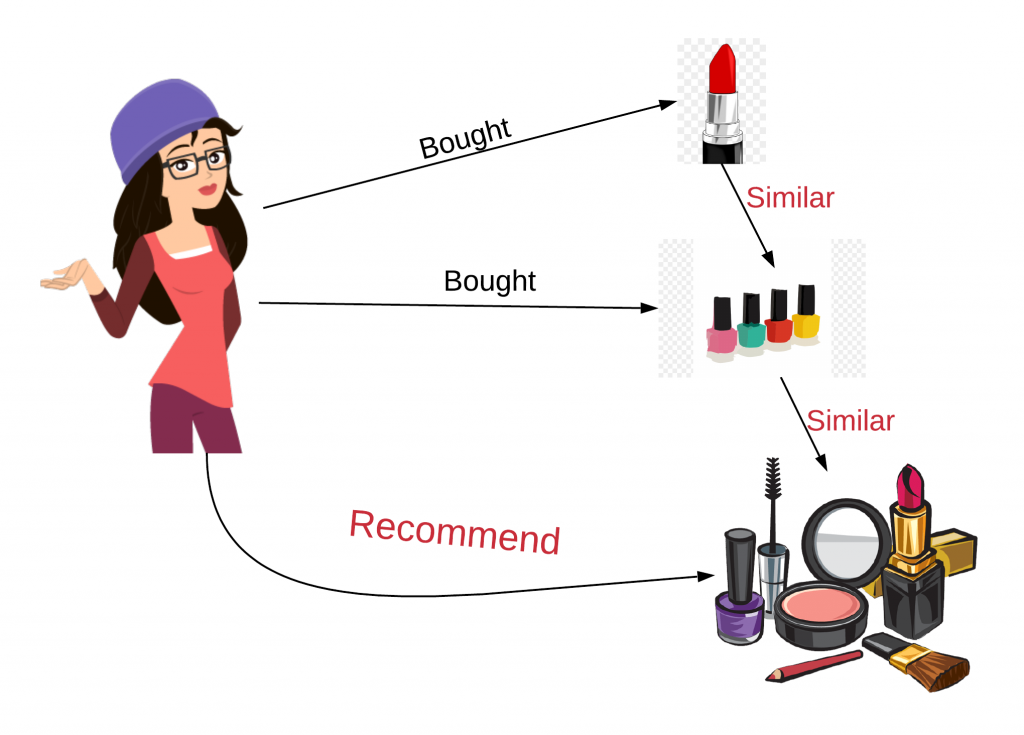
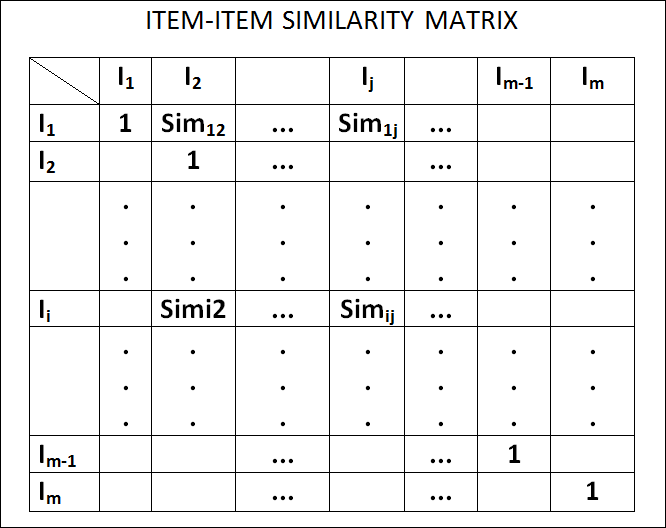
圖. ITEM-ITEM Similarity Matrix
如何從User-Item Matrix轉換為 USER-USER Similarity Matrix 或 ITEM-ITEM Similarity Matrix,請看以下說明。
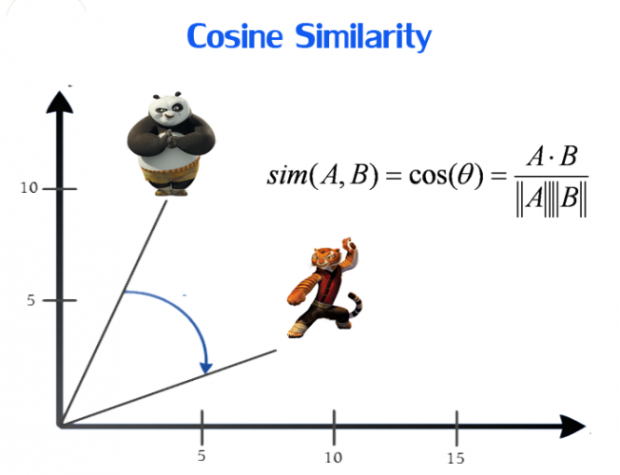
計算相似性(Similarity)有三種統計量:
先看一個簡單的例子,假設有5部電影、3個觀眾評論,要猜第3個觀眾是否喜歡第5部電影:
以下圖片來自:Recommendation Systems by Akanksha

解法很簡單:
以上只有喜歡/不喜歡兩種,若觀眾評論改為分數,要如何計算? 例如觀眾評分如下: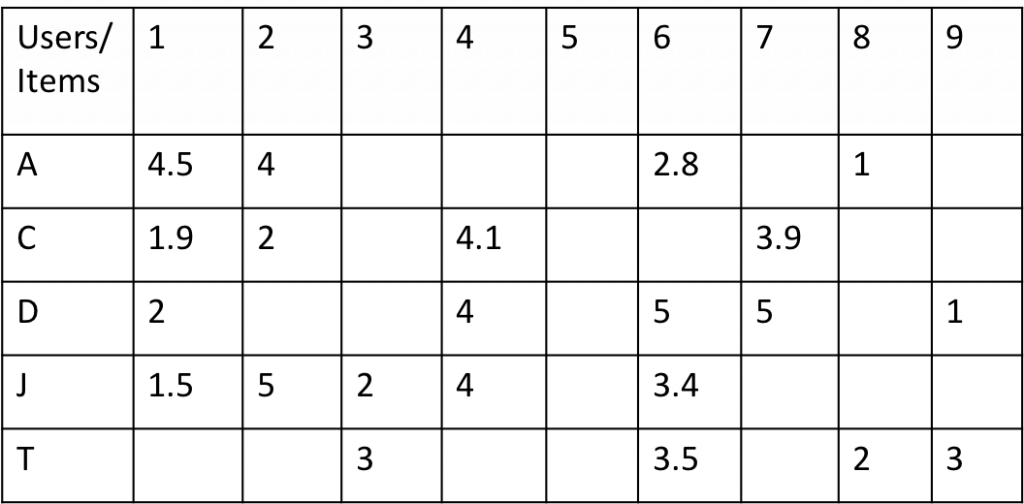
兩兩使用者計算其反歐基里德距離(inverse Euclidean distance),例如 C 與 D 的Cosine值計算如下: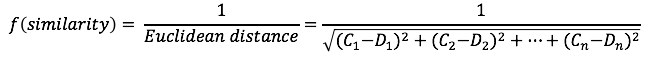
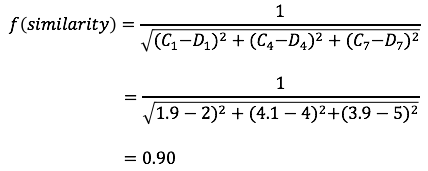
全部算完後,如下表: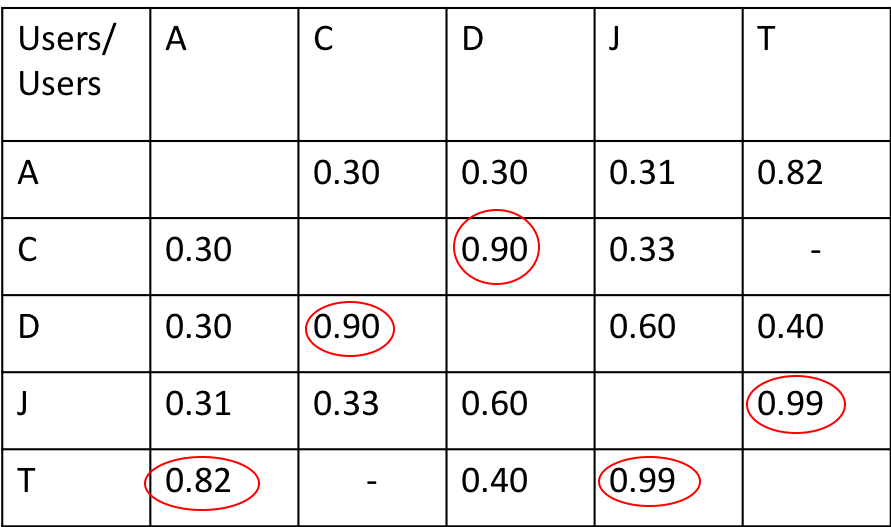
結論如下:
ITEM-ITEM Similarity Matrix 產生的方式以列(Item)作比較,算法完全一樣。
一般網購的顧客、會員或潛在客戶(Leads)很多,如果使用 USER-USER 協同過濾,USER-USER Similarity Matrix 就會非常大,計算非常耗時,這時就可以採用 ITEM-ITEM 協同過濾計算比較快。反之,如果是屬於內容為主的網站,例如新聞、部落格,則因商品是新聞或業配文,文章推陳出新,亦即商品很多,就適合使用 USER-USER 協同過濾法。此外,USER-USER 協同過濾法是推薦最多使用者購買的商品,所以,常會推薦熱銷品,相對的,ITEM-ITEM 協同過濾就比較容易推薦到長尾(long tail)的商品(銷量不大,但一直持續有人購買),這對公司整體營收會有較良性的助益。
基本上,協同過濾還有一個缺點,稱為『冷啟動』(Cold Start)的問題,網站開始的初期,缺乏相關的歷史資料,或者新商品剛推出時,尚無購買或評論記錄,這時就沒辦法計算了。
網站講求即時反應,推薦商品給顧客的速度要快,同時,提供的資訊必須要新,所以,系統重新計算Similarity Matrix 的頻率也是一個重要的考量,必須要速度與新鮮度平衡兼顧。
講了那麼多,下次就來實作協同過濾法看看。


 iThome鐵人賽
iThome鐵人賽