為什麼說KNN是懶惰學習的分類算法?。之所以稱“懶惰”並不是由於此類算法看起來很簡單,而是在訓練模型過程中這類算法並不去學習一個判別式函數(損失函數)而是要記住整個訓練集,這樣解釋可能沒有很懂,那就看看下面那張圖吧
對於預測新的數據,在範圍內與旁邊的鄰居進行比較,並以這幾個鄰居(訓練樣本)中出現最多的分類標籤作為最終新樣本數據的預測標籤。就好像國小國中常常會搞小團體,某天新來的同學突然被要求選邊站,不想以後在班上被欺負,當然選擇人多的那一邊嘛!!
或是更簡單一點,用一句話就可以形容KNN的原理,其概念與「近朱者赤,近墨者黑」相同,就是周圍的資料決定其分類。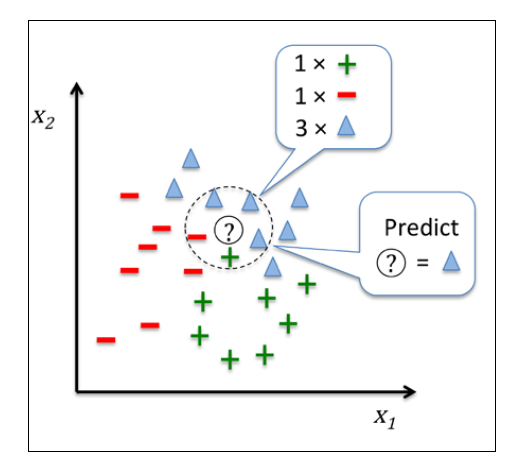
步驟
如何選定k值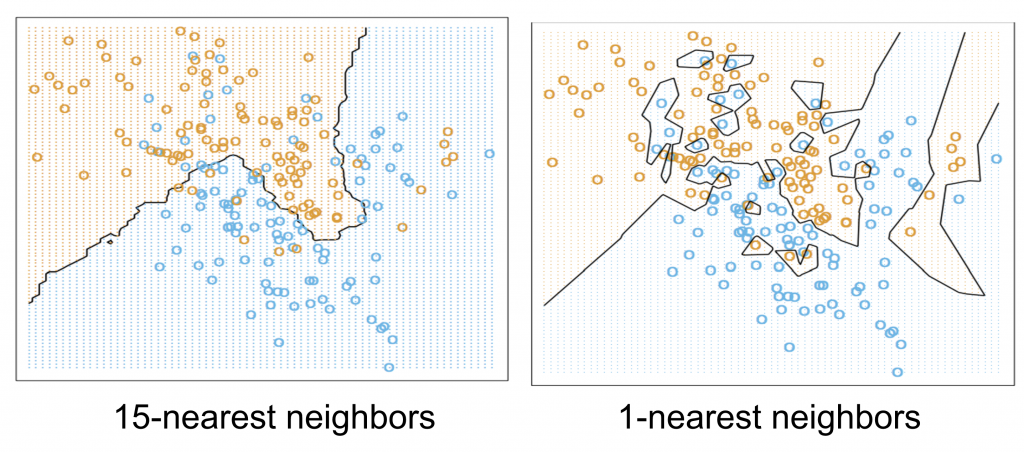
參考文獻
[Machine Learning] kNN分類演算法
沒有想像中簡單的簡單分類器 Knn


 iThome鐵人賽
iThome鐵人賽