昨天介紹了對模型加入預處理的修改,今天要介紹的就是 training 節點的修改啦,原本的模型中,我們已用了 placeholder_with_default 來只指定預設值,但是如果你先前的模型是直接使用 placeholder 的話,會變成每次推論都要指定布林值,這時就可以用上今天的方法將 training 節點封住。
和昨天預處理不一樣的地方在於,training 節點指向多個 layer,包括 dropout 和 batch normalization 都有,因此,我們必須每個節點跑一輪後,檢查開節點的 input 是否有 training,如果有就改用 false constant 堵住。
跟上次的程式碼差不多,只是這次優化中,我們在 add_preprocessing() 後面多了 remove_training_node() 方法。
# opt start #
preprocess_gd = add_preprocessing('backend/conv_1/Conv2D', 'input_node')
update_graph(preprocess_gd)
no_training_gd = remove_training_node('training')
update_graph(no_training_gd)
# opt end #
而 remove_training_node() 前半段,我們先宣告所需要的新節點跟創建等等用來產生新節點的 list:
def remove_training_node(is_training_node):
false_node = tf.constant(False, dtype=tf.bool, shape=(), name='false_node')
old_gd = tf.get_default_graph().as_graph_def()
old_nodes = old_gd.node # old nodes from graph
nodes_after_modify = []
接著,就是中間處理的部份,我們一樣透過 for 迴圈繞一次所有節點並拷貝資料,然後把 input 砍掉,替換成新的 input,如果 input 中是 training 節點就換成 false_node,反之則保留原本 input,詳細實作如下:
for node in old_nodes:
new_node = node_def_pb2.NodeDef() # 產生新節點
new_node.CopyFrom(node) # 拷貝舊節點資訊到新節點
input_before_removal = node.input # 把舊節點的inputs暫存起來
del new_node.input[:] # 就把該inputs全部去除
for full_input_name in input_before_removal: # 然後再for跑一次剛剛刪除的inputs
if full_input_name == is_training_node: # inputs中若有training_node
new_node.input.append(false_node.op.name) # 改塞false_node給它
else:
new_node.input.append(full_input_name) # 不是的話,維持原先的input
nodes_after_modify.append(new_node) # 將新節點存到list
new_gd = graph_pb2.GraphDef() # 產生新graph def
new_gd.node.extend(nodes_after_modify) # 在新graph def中生成那些新節點後return
return new_gd
執行 session 時,feed_dict 的 training 節點就可以不必再指定啦!
with tf.Session() as sess:
input_node = tf.get_default_graph().get_tensor_by_name(
"new_input_node:0")
output_node = tf.get_default_graph().get_tensor_by_name(
"final_dense/MatMul:0")
image = cv2.imread('../05/ithome.jpg')
image = cv2.resize(image, (128, 128))
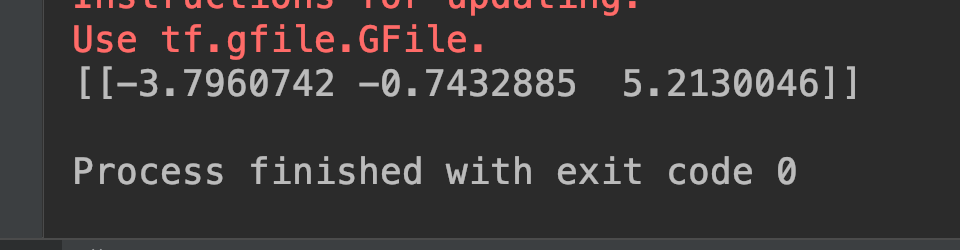
output = sess.run(output_node, feed_dict={input_node: np.expand_dims(image, 0)})
print(output)
我們來看看 graph 的變化,這是執行前: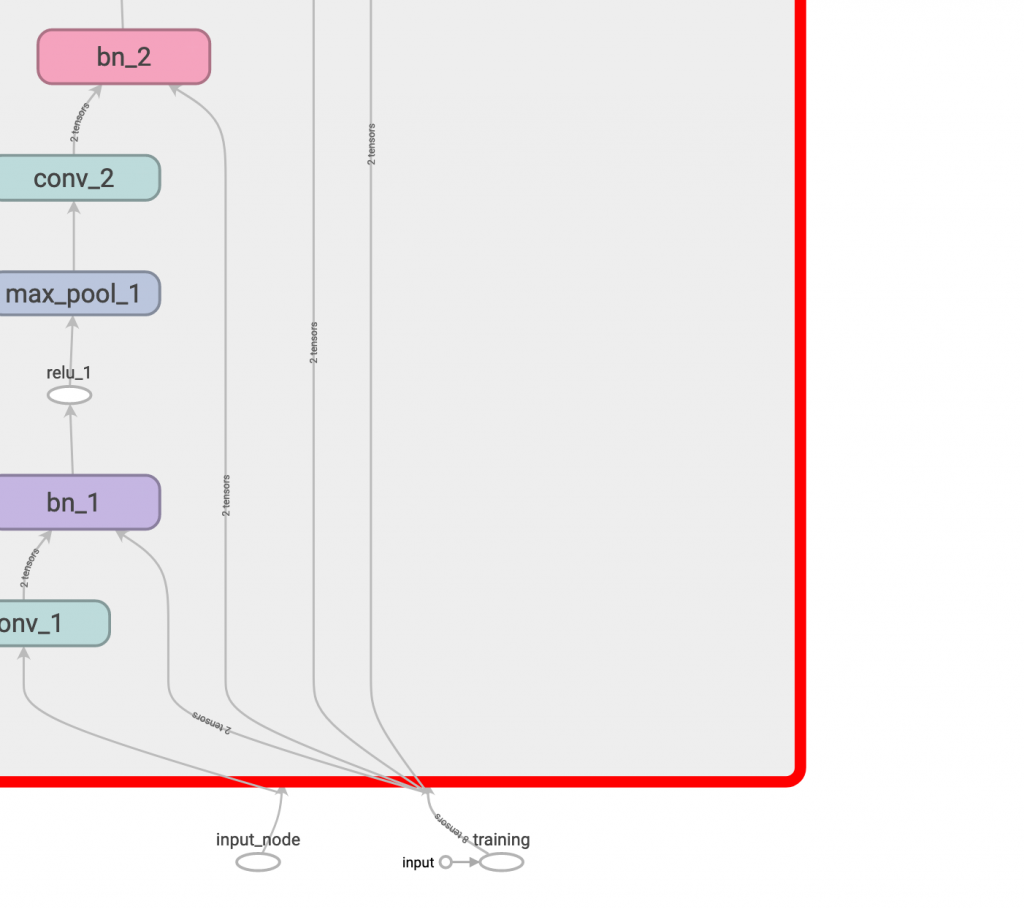
這是執行後的 bn: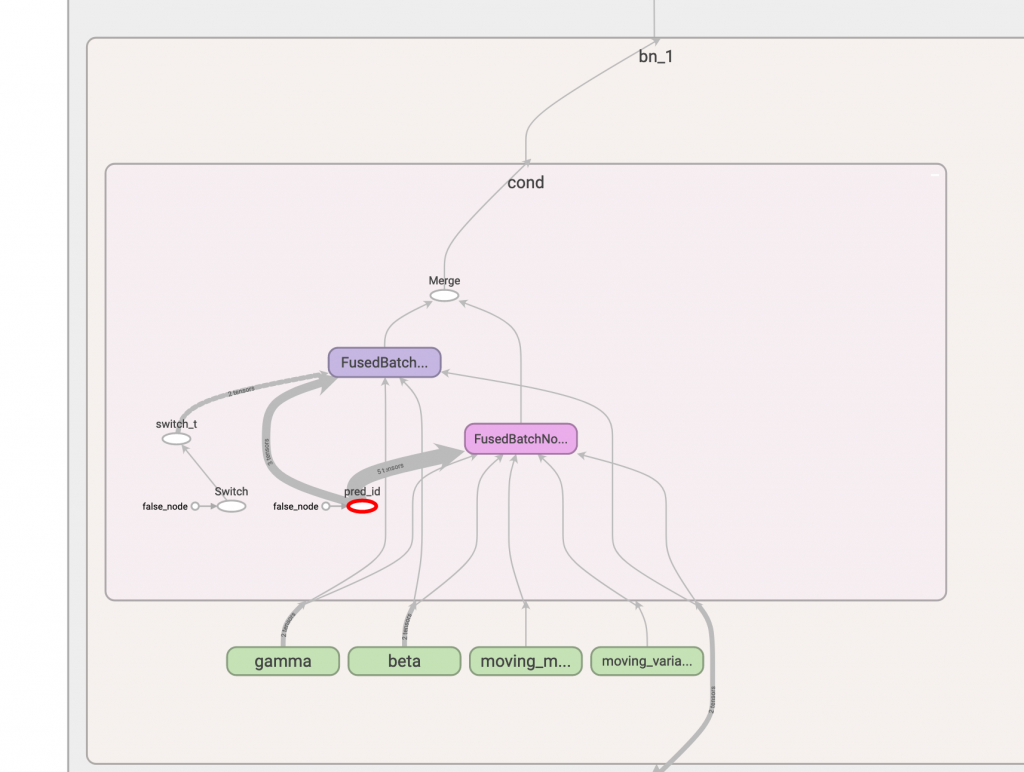
和執行後的 dropout: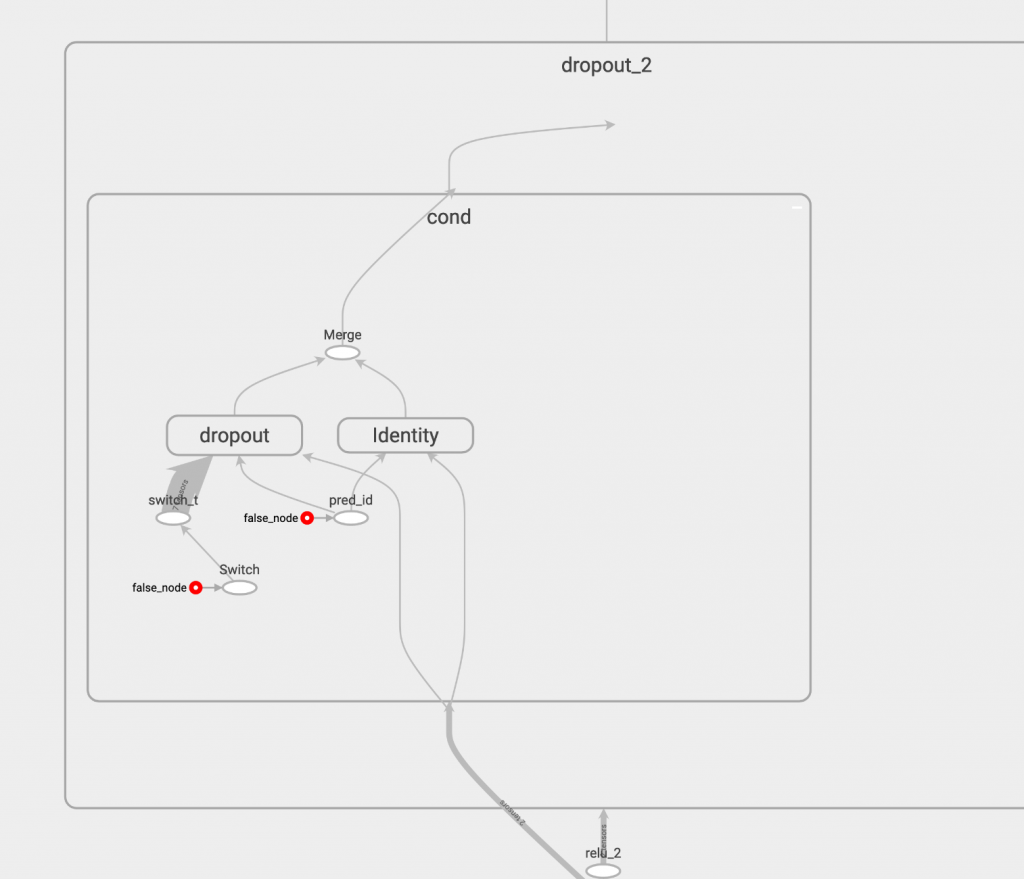
整個模型來看,training 節點不見了。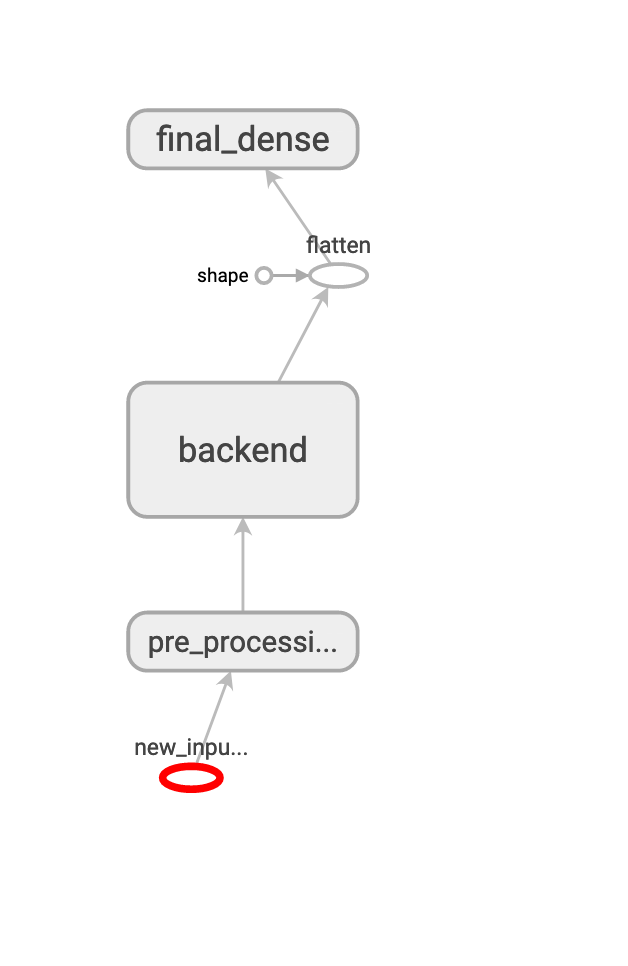
輸出的話,也可以看到數字沒改變,模型的邏輯還是一樣的!