
在介紹 batch normalization 在 tensorflow 的樣子之前,先簡單跟大家介紹一下 batch normalization 數學原理,希望以下理論的部分對大家來說都是複習。
在 batch normalization 的結構中,有幾個特別重要的參數。
(mu, sigma) 分別代表這次 batch data 的平均和標準差。
(gamma, beta) 代表要被 gradient 訓練的權重值
(running_mean, running_var) 訓練時,由觀察 batch data 得到的平均和標準差。
以上參數在訓練和推斷時會有不同用途。
訓練時:
輸入資料會先減去 mu 再除上 sigma ,normalize 到一個範圍 (-1~1 附近)
x = (x - mu) / sigma
接著再乘上 gamma 並加上 beta 後輸出。
out = gamma * x + beta
此時會把 mu 和 sigma 的值更新到 running_mean 和 running_var。
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
照上述公式可以知道 batch size 越大,得到的 running_mean 和 running_var 越有說服力。
推斷時:
因為進來的資料不是以 batch 為單位,一次可能只推斷一筆資料,所以你沒有辦法用 mu 和 sigma 來執行 normalization,這時就會拿上述訓練時算出來的 running_mean 和 running_var 來用,就是說running_mean 和 running_var 是根據訓練時的經驗法則得出的結果。
x = (x - running_mean) / running_var
normalization 完後再一樣乘上 gamma 並加上 beta 後輸出。
out = gamma * x + beta
以上就是 batch normalization 的整個工作流程,所以啦!為什麼 batch normalization 的效果好不好和你的 batch size 有關,因為size越大,你算到的 mu 和 sigma 越有參考價值。也因此,假設!你哪天看到某人的程式碼使用 stochastic gradient descent,只單拿一筆資料訓練,網路裡還大量使用了 batch normalization,那就代表這個網路架構的 batch normalization 全部都是白工...XD
好的,回來我們的 tensorflow 實作篇,我們來剖析 batch normalization。
graph = tf.get_default_graph()
graph_def = graph.as_graph_def()
with gfile.FastGFile(MODEL_PB, 'rb') as f:
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
執行後可以看到下圖。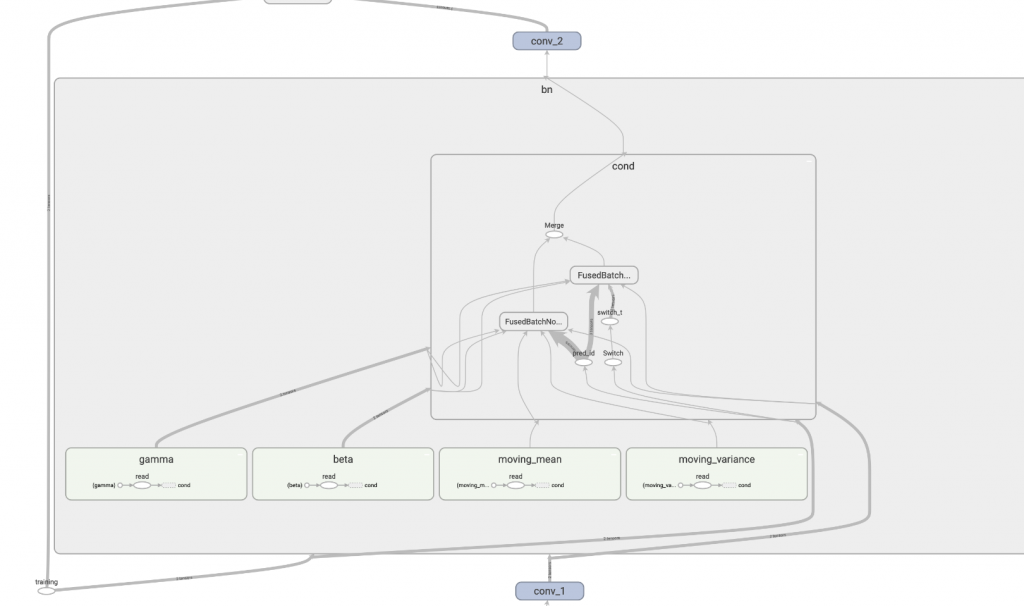
我們看到 tensorflow 產生了兩個 FusedBatchNorm,我們再將其打開它可以看到:
FusedBatchNorm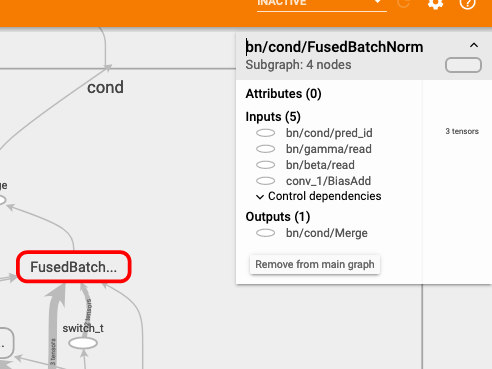
FusedBatchNorm_1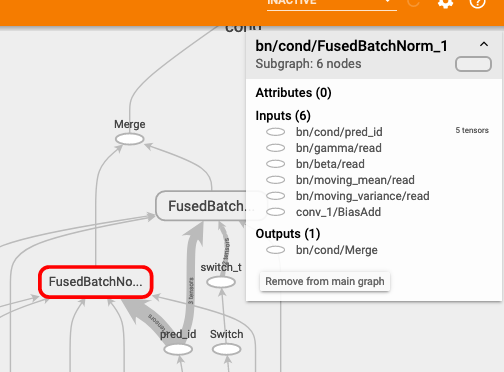
知道在 training 和 inference 時,他們各別會使用哪個模塊了嗎?
.
.
.
.
.
.
.
.
答案:
training 使用 FusedBatchNorm,inference 使用 FusedBatchNorm_1。
原因:
從右上方看到 FusedBatchNorm_1 的輸入中有 running_mean 和 running_var,這兩個變數是推斷時會用到的參數。而 FusedBatchNorm 的輸入不需要這兩者。
所以啦!這兩個 FusedBatchNorm 之前才有 tf.switch 這個控制閥,依據是哪個模式將資料推送到哪個 FusedBatchNorm,這就是 batch normalization 底層實際在做的事情,酷吧!
接下來為了應證,我寫了一段程式碼來看實際結果。
input_node = graph.get_tensor_by_name(
"input_node:0")
training_node = graph.get_tensor_by_name(
"training:0")
debug_node = graph.get_tensor_by_name(
"bn/cond/Merge:0")
with tf.Session() as sess:
image = cv2.imread('../05/ithome.jpg')
image = np.expand_dims(image, 0)
# 訓練
result = sess.run(debug_node, feed_dict={input_node: image, training_node: True})
print(f'training true:\n{result[0, 22:28, 22:28, 0]}')
# 推斷
result = sess.run(debug_node, feed_dict={input_node: image, training_node: False})
print(f'training false:\n{result[0, 22:28, 22:28, 0]}')
輸出得到: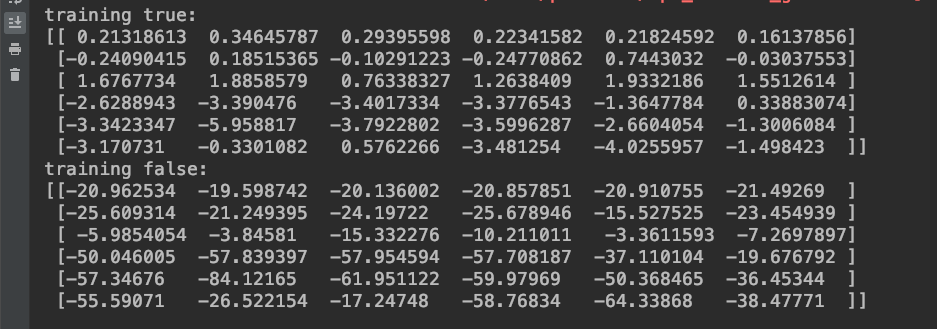
可以看到訓練模式下,經過 batch normalization 的值有很明顯被 normalization 過,而推斷模式下,因為 running_mean 和 running_var 因為還沒被學習更新,所以都是預設值(mean=0, var=1),所以數字才會那麼巨大沒 normalization!
今天的介紹到這邊,希望您有收穫!
