k-means clustering 是我覺得最直觀好理解的分群方式。完整分群的過程概念可以分成兩大部分:
一是計算資料點之間的距離。繼續套用前一篇四個階段的香蕉的例子,所謂資料點就是指一個轉錄產物在四個不同階段採樣的基因表現量,可以表現成一個四維的向量比如 (4,7,3,6)。資料點間的距離就是兩個基因所屬的四維向量之間的距離,這個距離有不同的計算方式,最簡單的計算方式就是 Euclidean distance 歐式距離,以兩個點之間的直線距離來表示資料點間的距離。總共有 n 個資料點的話,需要計算出 C n 取二個資料點間的距離。
二是群落的形成。分群的演算法可以分成三大類別:分割型、階層式分群型、以及基於模型的分群方式。k-means 屬於分割型,將 n 個資料點指定到 k 個群落之心,不斷重新調整直到某些標準達標為止,比如屬於同一群的資料點之間的距離跟其他資料點比起來都是最小的。

(截圖來自福音戰士新劇場版:Q)

(截圖來自 REDLINE)
實際上演算法的內容會透過下方詳細的計算過程來完成上述的兩大步驟:
直接看動畫來體會吧~
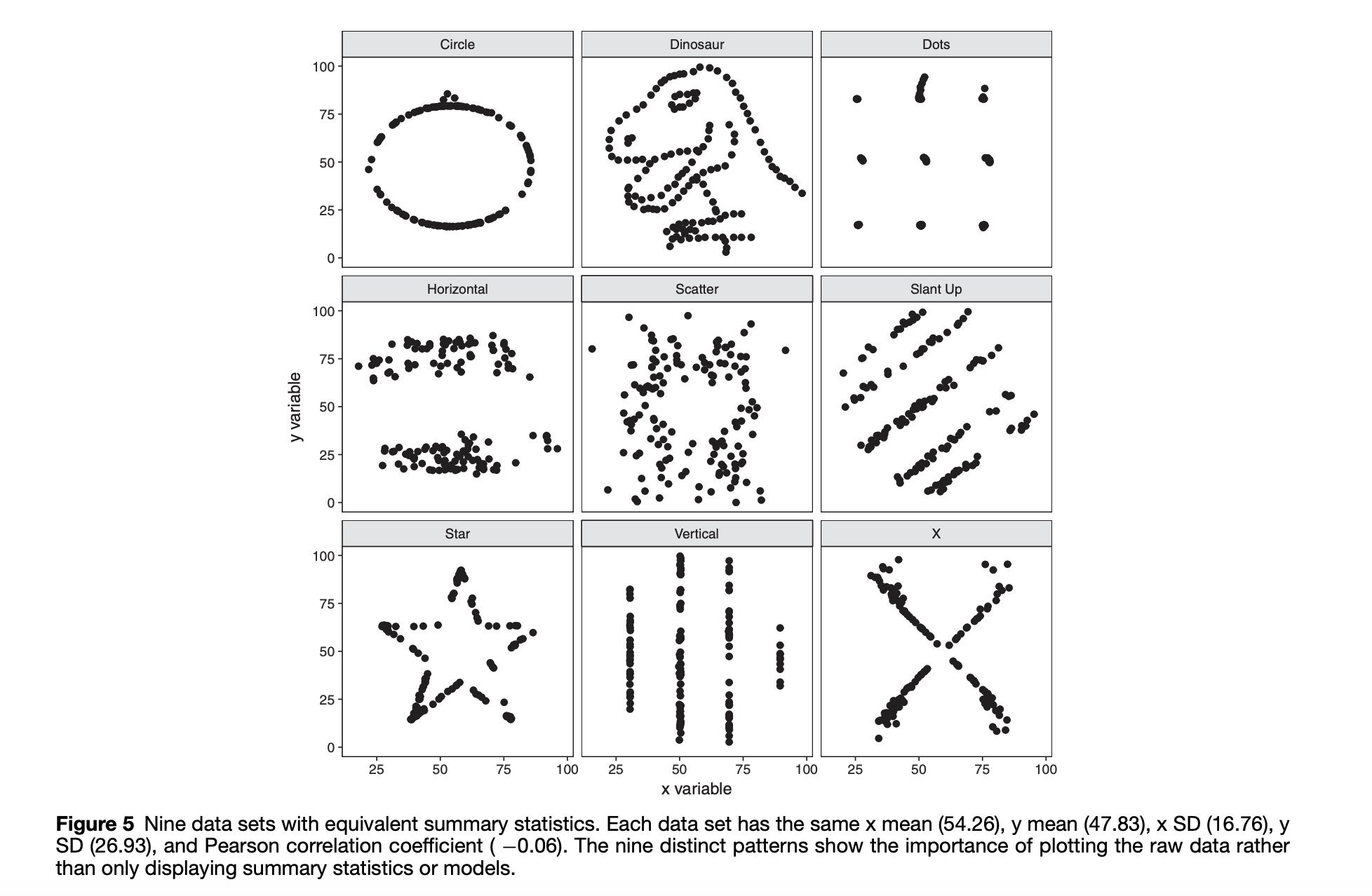
(光是在二維資料上,有著相同平均值與 correlation 的資料點就有很多不同的可能,其中像是圓圈狀的資料就難以用線性的分群方式處理,可能分群方式就會隨著每次的初始群心指定數值不同,而有不同的分群結果)
雖然概念相當直觀的 k-means 是一種最簡單好理解的分群方式,但是資料的型態非常多樣,有時候還是需要試試更多不同的方法來分群才可以分出理想的結果~以上有錯誤或任何想法請留言告訴我~
Can Graphics Tell Lies? A Tutorial on How To Visualize Your Data
關於作者
謝晨 (Chen Hsieh),臺大園藝暨景觀學系研究所碩士。讀碩士前的興趣是懷著寫點程式妄圖解決農業問題的夢想參加比賽,拿了幾個黑客松與 Open Data 創新應用競賽的獎,卻都沒有勇氣將項目經營下去;研究所期間的興趣轉換成讀學術期刊的出刊電子報。靠著這些興趣當選 107 學年的臺大優秀青年,畢業後卻成了無業的實驗室居民。現在在農場旁的研究館辦公室寫點東西,希望可以跟世界分享生物資訊與園藝的樂趣!
感謝選擇匿名的朋友協助校閱初稿與提供意見,也敬請各位讀者不吝指教!


 iThome鐵人賽
iThome鐵人賽