
試驗設計有兩個組別以上的話,就會有超過一組的處理比較組。比如說香蕉由綠轉黃的過程就可以分成很多階段,取其中的四個階段採樣,同一轉錄產物在四個不同階段中的表現量,兩兩互比就可以有 C 四取二種比較組合,共計六種可能差異表現的組合,每個差異表現又可以分成上調跟下調,展開來就會有太多種基因表現的 pattern,而且不一定每一種 pattern 都有生物上的意義。所以我們想要了解全部差異表現基因的特徵以及其類別分佈情形的話,最好的方法就是讓基因依據表現量的 pattern 透過非監督式學習的方式來分群。
非監督式學習的概念,可以想像成是戴皮手套的過程。全新的硬梆梆扁平皮手套是模型,人的手是資料,每一次的穿戴過程就是演算法。每一次穿戴,人手就稍稍地改變手套的樣子,直到手套變成合手的形狀不再有大幅改變為止。也可以想像成睡記憶枕的感覺,總之就是完全由資料驅動 (data-driven),沒有人為標記資料或是其他知識參雜擬合過程,硬要繼續用手套比喻的話,就是沒有人去告訴手套原來人手的指節有三節、左手大拇指在四隻手指的右邊等等的規則 (?)。
我猜我越比喻反而越糟糕,等到明天再來實際簡介最直觀好理解的 k-means clustering 的原理~先讓我們實際看看分群會用在什麼地方~
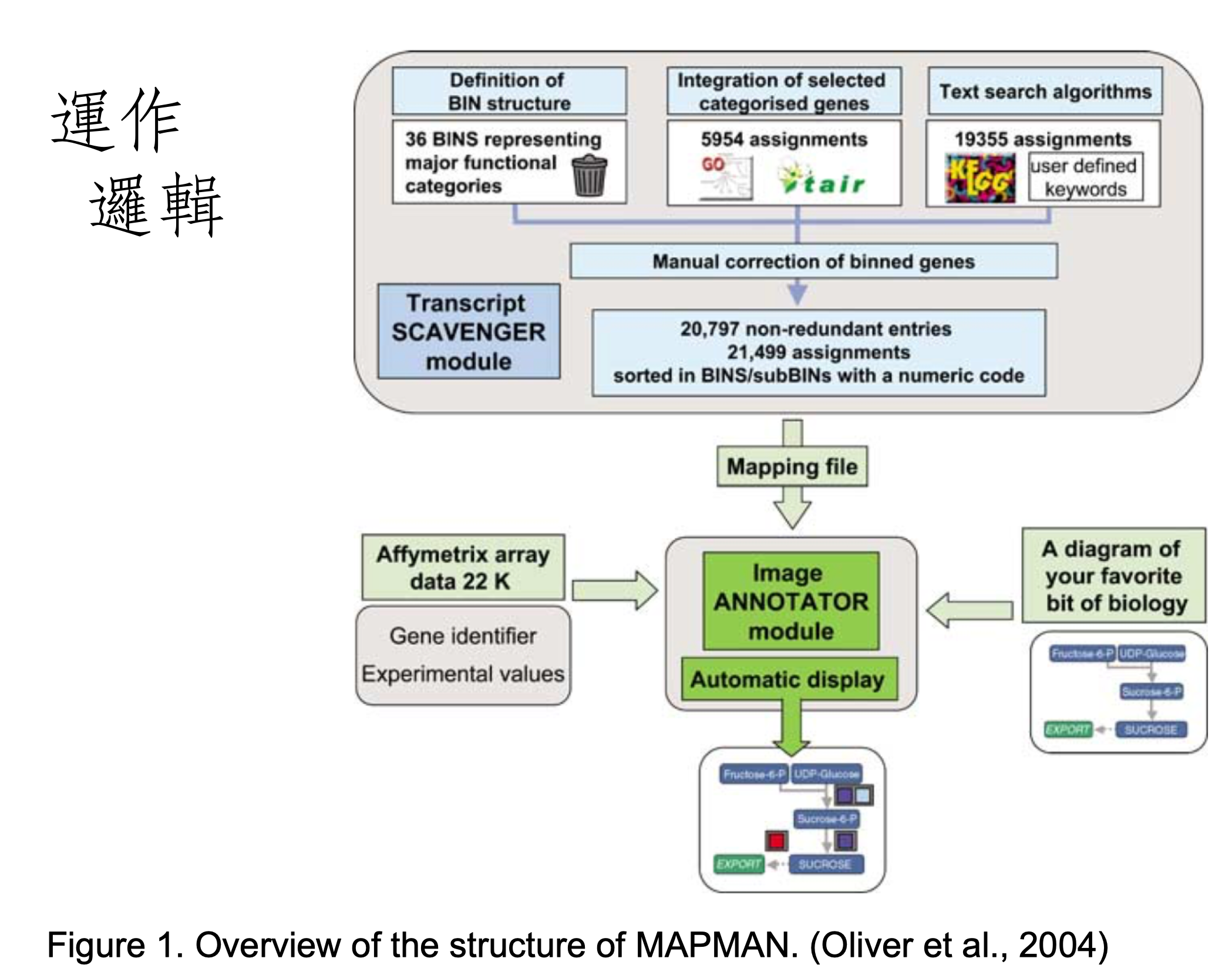
MAPMAN 是一款專為植物研究打造的工具,包含註解系統與套裝分析軟體。

其運作原理在初次發表的文獻中如下圖描述
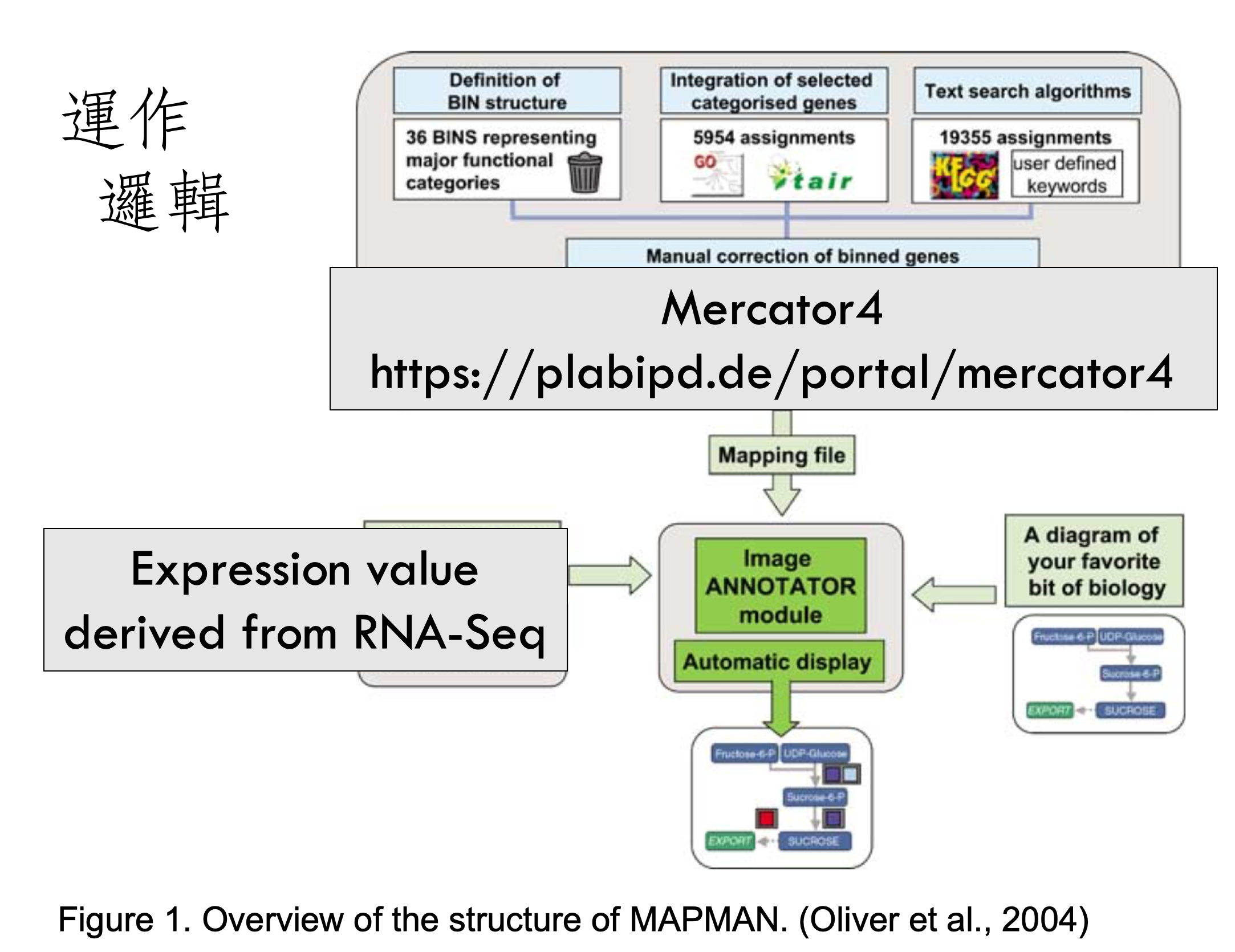
而套用到現代的技術的話就是將上方的框框改為線上註解系統,左側的表現量來源改為轉錄體分析。
套裝分析的部分主要分成下列五種功能,本次會出現文氏圖和分群分析兩種。

資料匯入階段,如果是模式植物的話,軟體會自動識別 ID,如果是新組裝轉錄體的話就需要使用線上的 Mercator 註解系統。
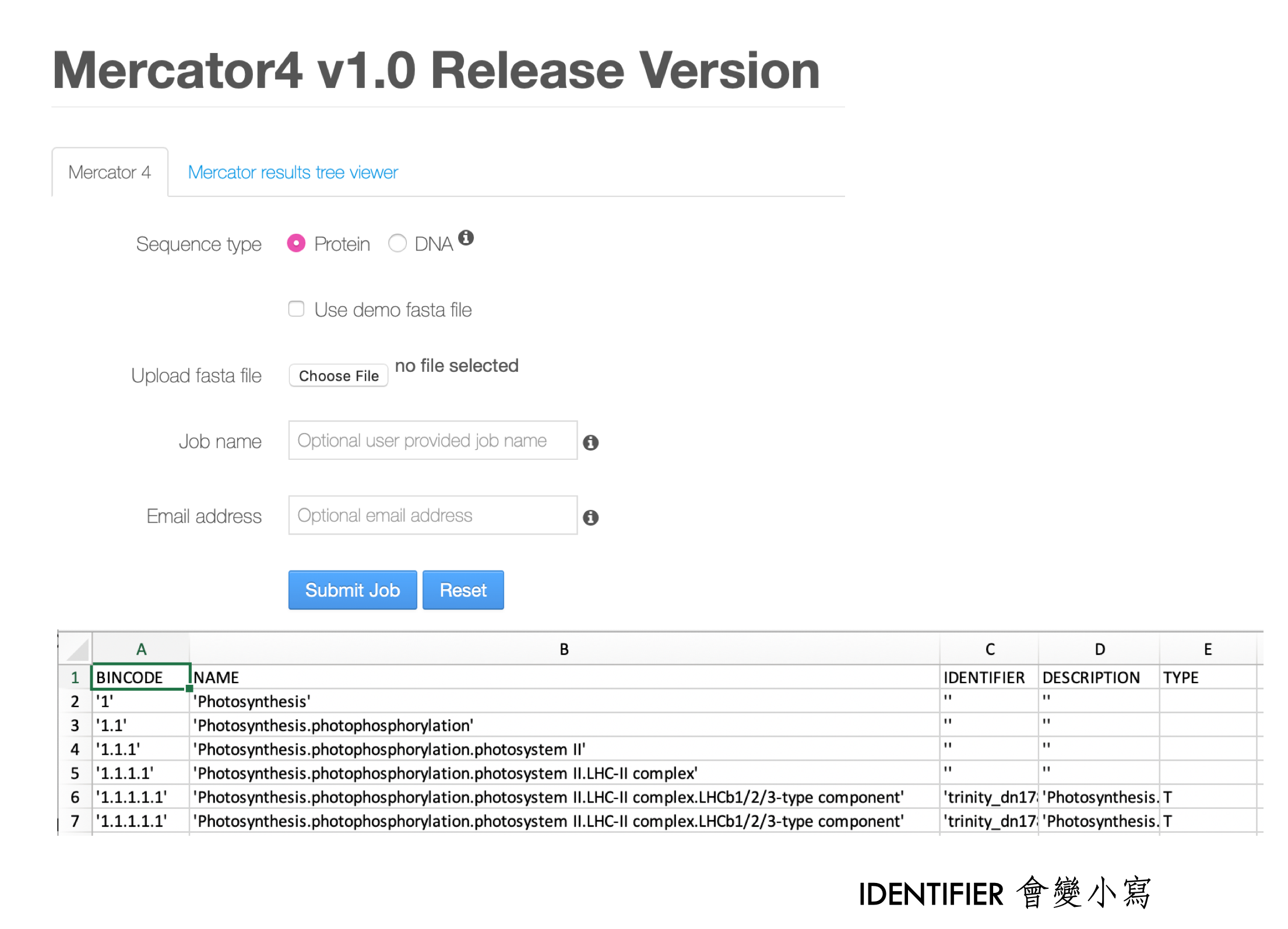
註解完畢要將註解的對照表結果輸入(格式如上圖),而基因表現量的資料則需要依據下列格式匯入。
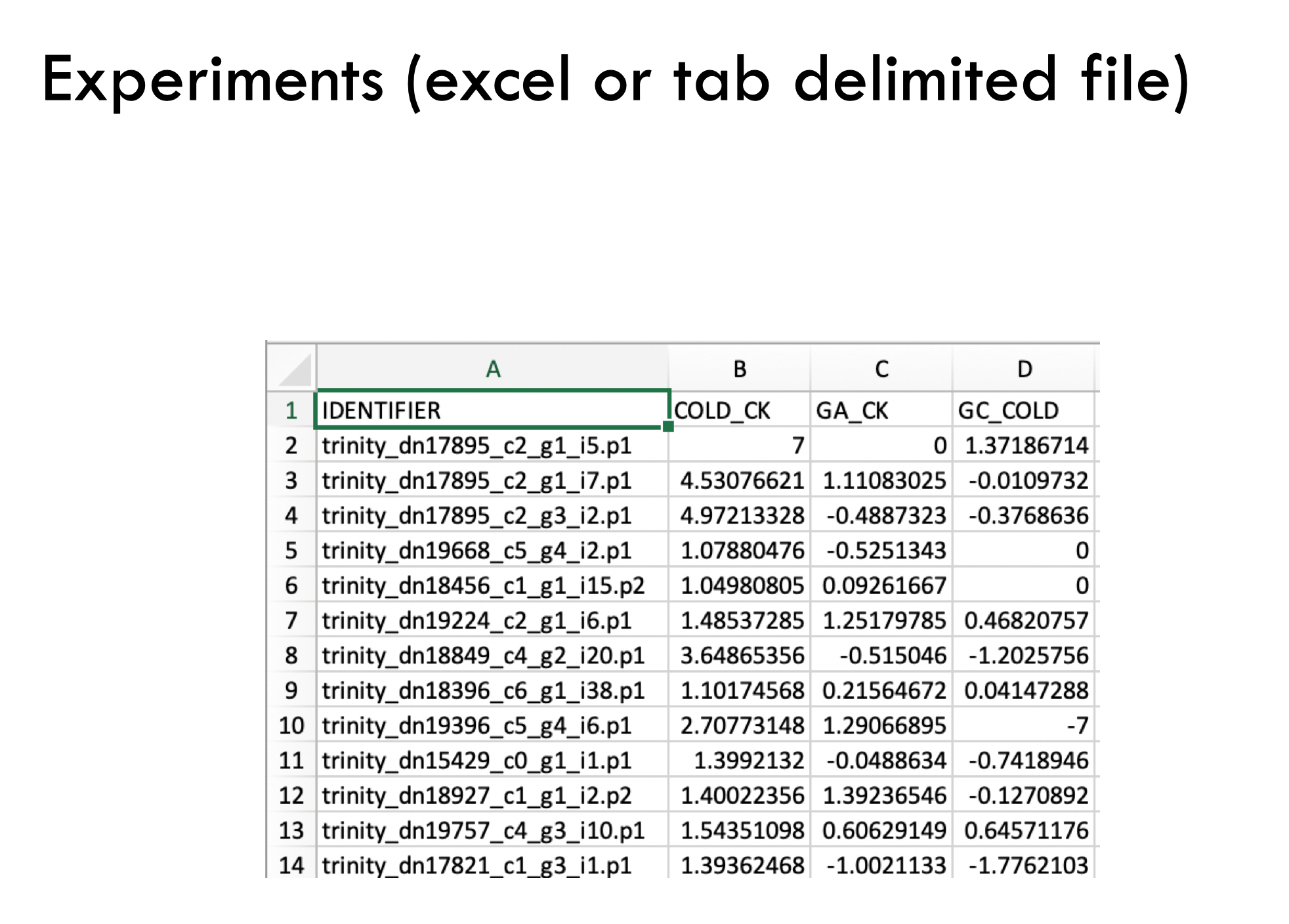
到此為止也算是完成準備工作了,先讓我們看看文式圖分析的結果

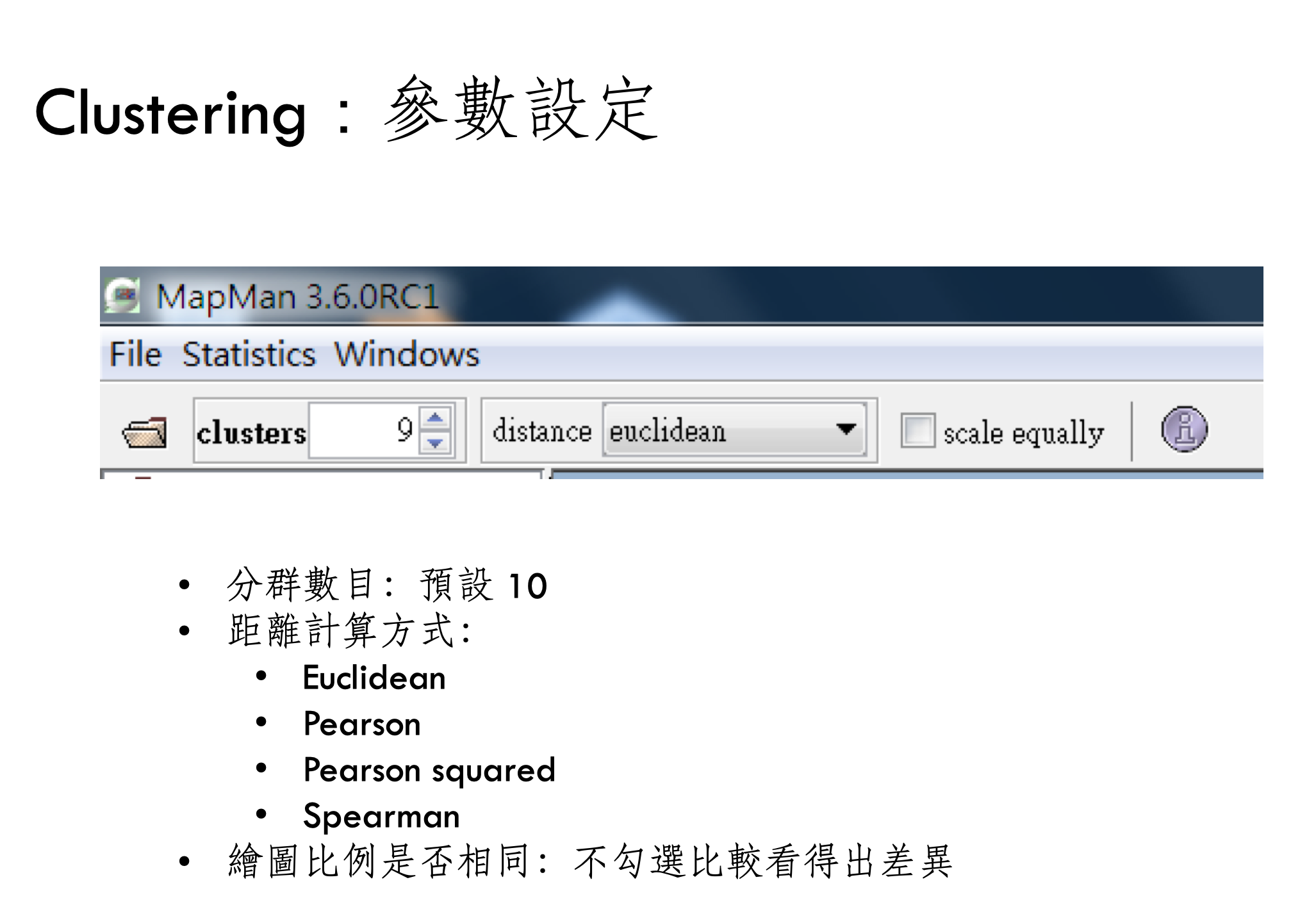
三個處理比較組的話就會有三個圈圈,其中共同出現部分的基因就是都有差異表現的基因,但是卻無法知道這些基因的調節方向是相同還是相反。讓我們移駕到分群分析的部分,首先簡單設定參數,看不懂沒關係我們將在下一回說明
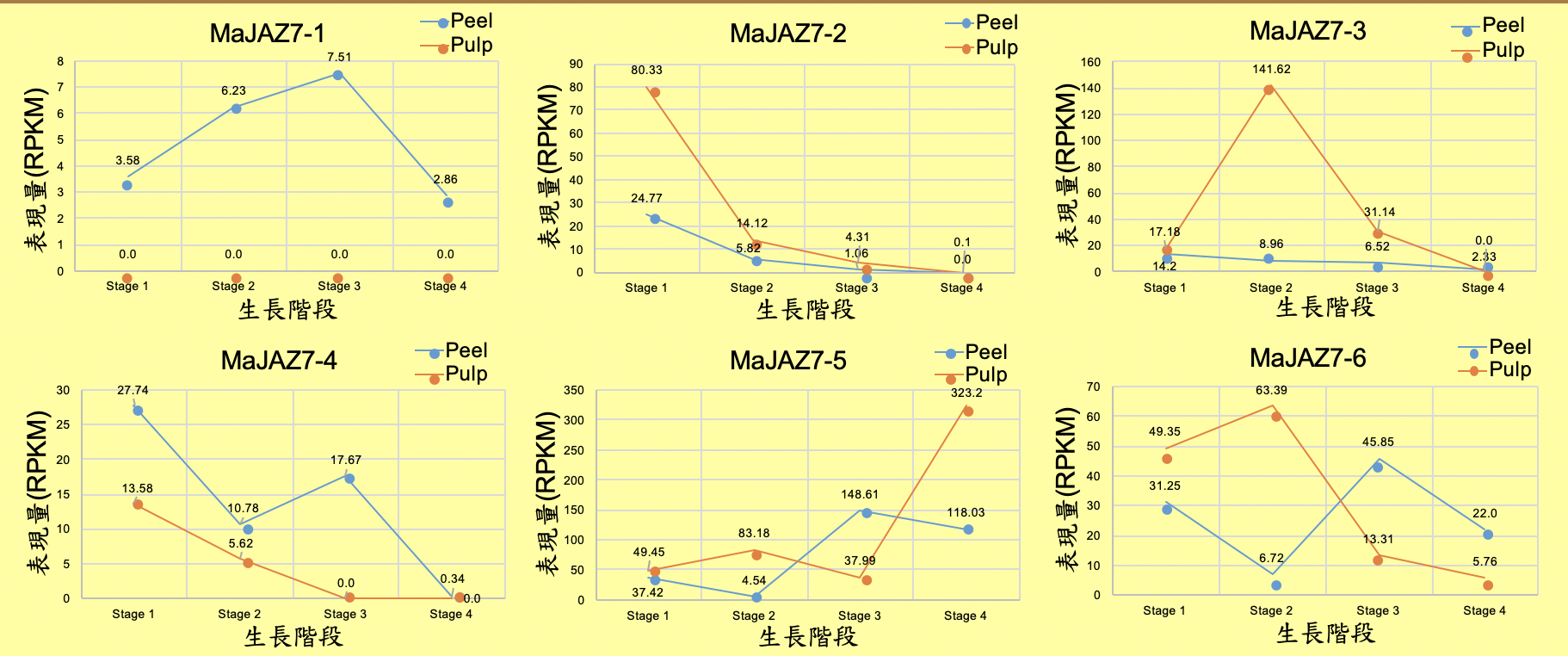
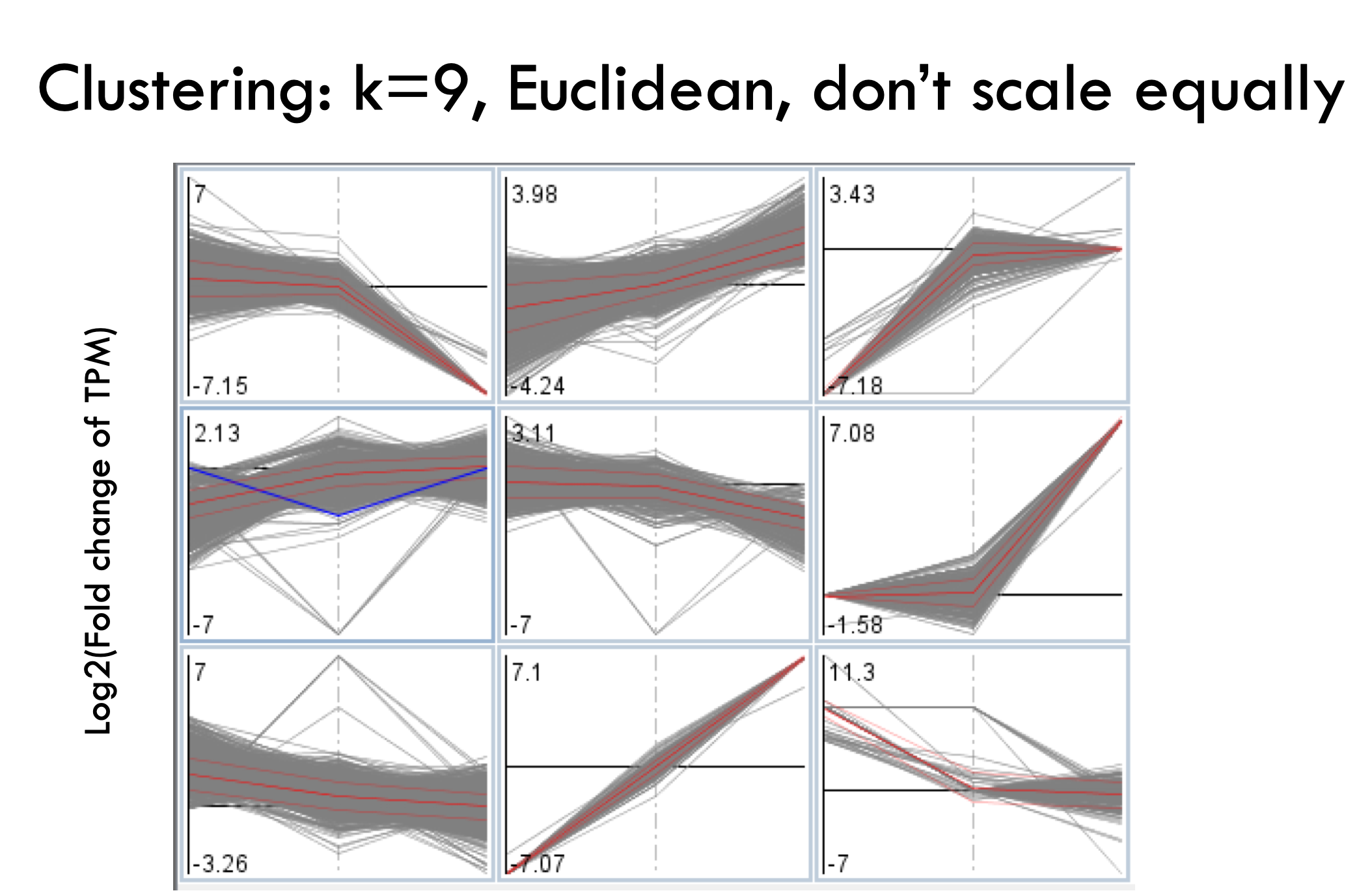
結果馬上就出來啦,可以看到分群的結果每一個組別都不同,而且物以類聚
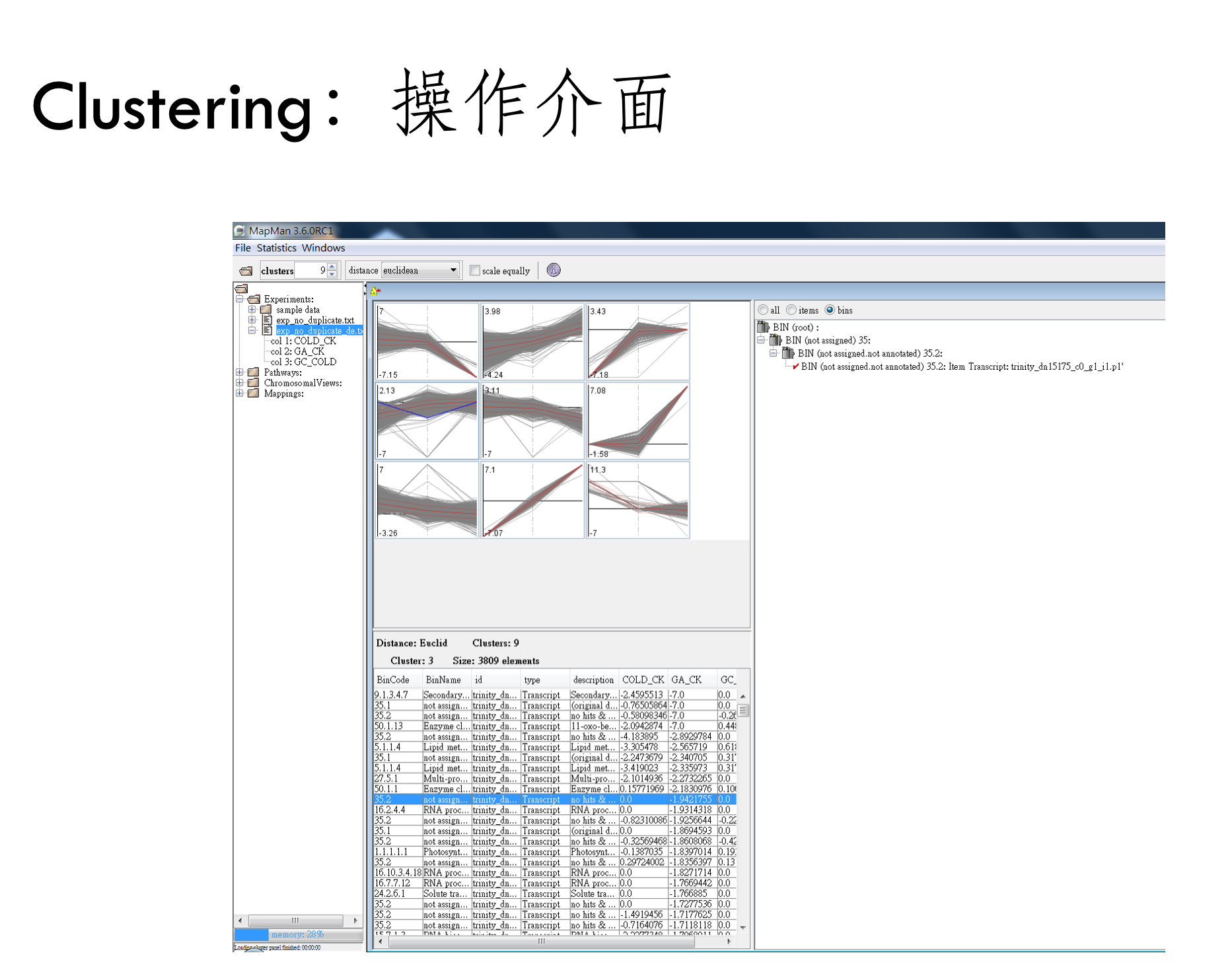
放大來看的樣子,總共三組數據,三個數據分別在左中右,預設以折線圖呈現
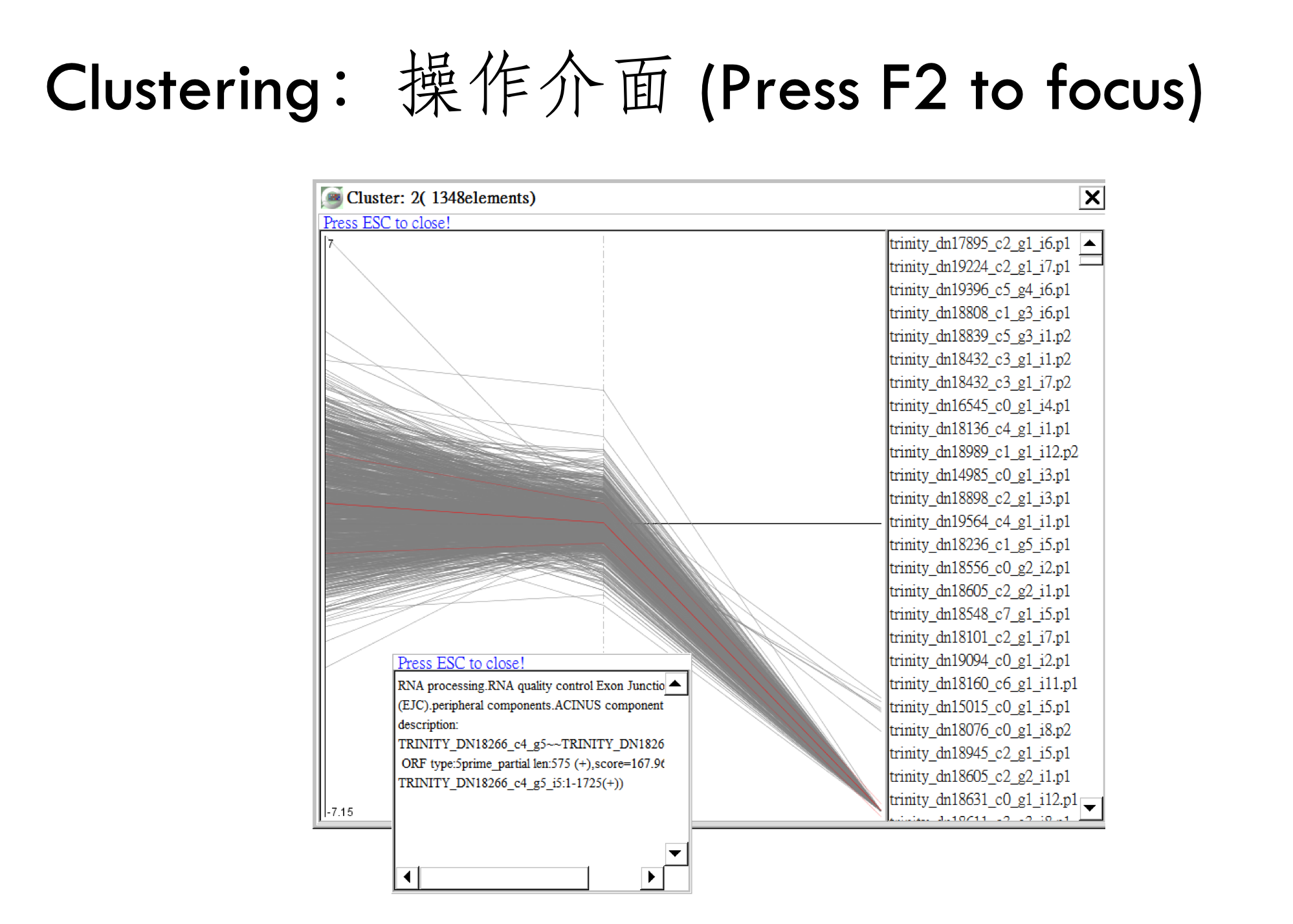
每個小圖也都可以鎖定來了解具體是哪個基因的表現量
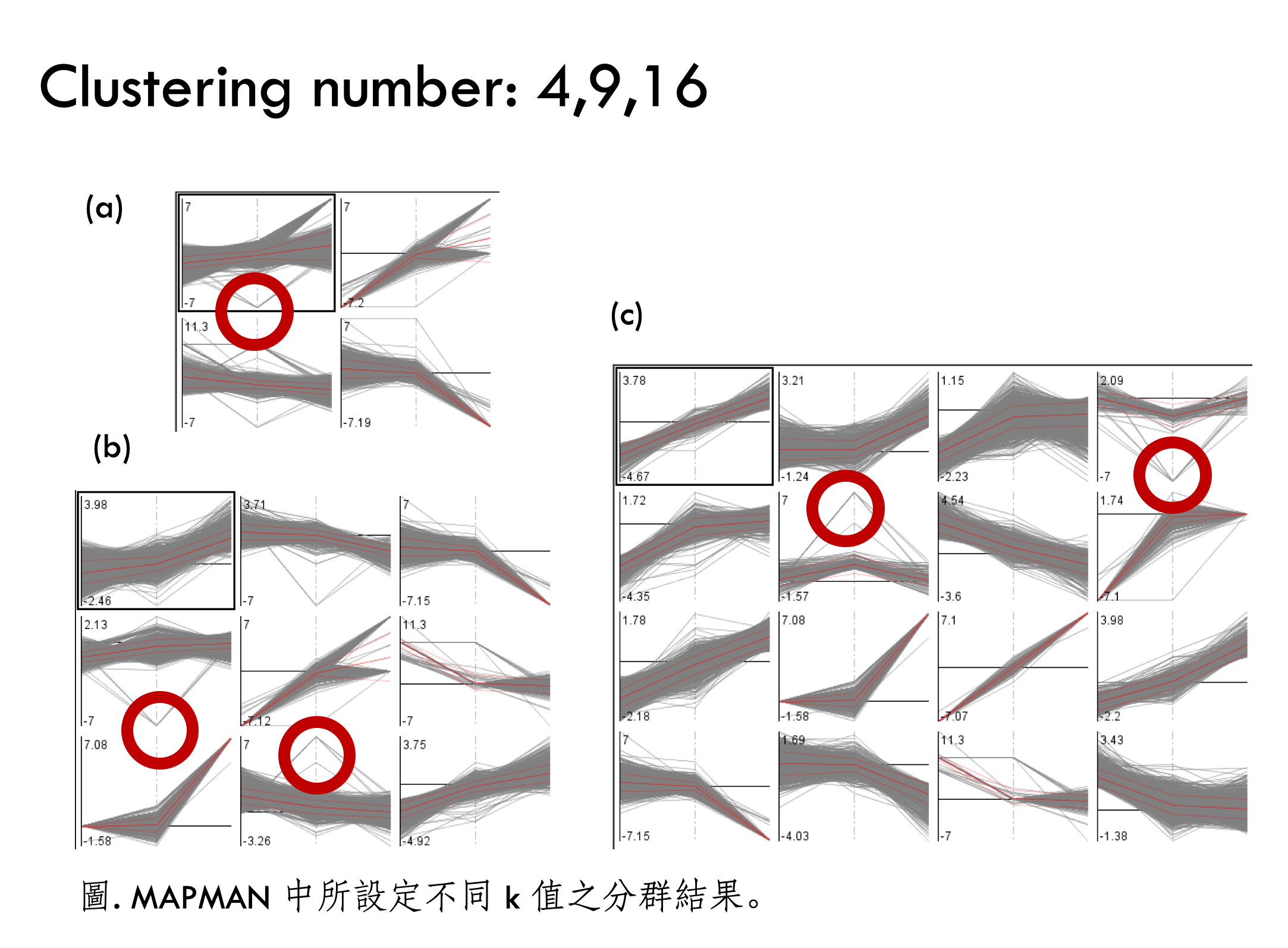
如果更改分群的數值的話,就可以看到不同的分群效果,但是可見紅圈之處都是有點離群的資料點
總地來說 MAPMAN 是針對植物研究很好用的軟體,但是這邊簡單整理用在分群的優缺點:
•優點:
•不用寫程式就可以進行非監督式學習的資料分群
•自動計算分群結果平均值
•使用介面方便資料探索
•缺點:
•分群結果不盡理想
•無法客製化顏色與縱軸先後
•即使參數相同,每次計算結果會略有不同
下一回我們將會實際簡介背後的原理,如果有更多想知道的事情請留言告訴我~
關於作者
謝晨 (Chen Hsieh),臺大園藝暨景觀學系研究所碩士。讀碩士前的興趣是懷著寫點程式妄圖解決農業問題的夢想參加比賽,拿了幾個黑客松與 Open Data 創新應用競賽的獎,卻都沒有勇氣將項目經營下去;研究所期間的興趣轉換成讀學術期刊的出刊電子報。靠著這些興趣當選 107 學年的臺大優秀青年,畢業後卻成了無業的實驗室居民。現在在農場旁的研究館辦公室寫點東西,希望可以跟世界分享生物資訊與園藝的樂趣!
感謝選擇匿名的朋友協助校閱初稿與提供意見,也敬請各位讀者不吝指教!


 iThome鐵人賽
iThome鐵人賽