如果你用Google以「BERT」作為關鍵字搜尋圖片,那麼你會發現一個奇特的現象:一隻黃色的玩偶與奇怪的網狀結構模型混雜在一起。那隻黃色玩偶是「芝麻街」電視節目的角色,它的名字正是BERT,而奇怪網狀結構的模型示意圖則是2018年Google所發佈的改變自然語言處理領域的預訓練語言模型(Pretrained Language Model)——BERT,全名為Bidirectional Encoder Representations from Transformers。兩者的同名不是巧合,而是Google工程師們起名時的創意(或者說惡搞)。許多後續跟BERT或預訓練語言模型有關的新模型也會用芝麻街角色的名字來命名(始作俑者其實是發布早於BERT的ELMo,可惜後者被BERT搶盡風頭)。

為什麼要研究或使用BERT?因為BERT以其出色的表現已經快要成為NLP的代名詞了。幾乎所有的比賽、大部分的研究論文都有使用到BERT相關模型(指包含BERT衍生模型或根據BERT思想所開發的新模型)。2018年10月12日,Google團隊的Thang Luong說:「一個NLP的新世代開啟了」。他們做到了。當年BERT橫掃所有的NLP評估基準(Benchmark),而後直至現在,雖然原始版本的BERT已不再是榜首,但盤據排行榜前三名的仍必定是根據BERT思想所開發的新模型或者乾脆就是在BERT之上修改出的衍生版本。
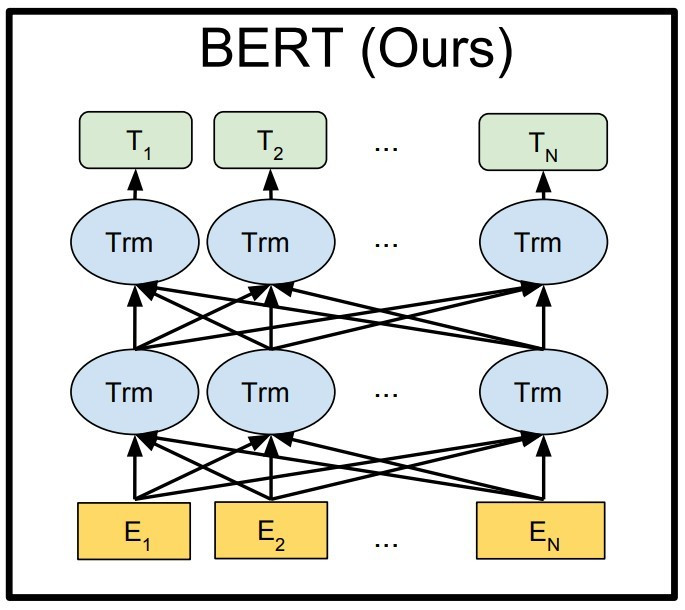
以下,讓我們先來從Transfer Learning(遷移學習)這個概念來初步認識BERT:
遷移學習的概念,簡單說就是將已經在一個特定資料集上訓練好的模型拿來用於另一個資料集的訓練。它所應用的情境通常是,自己所要做的任務僅有少量標註資料,不足以訓練一個好模型,但是公開領域中已經有了許多跟自己的任務相似或資料相似的大型標註資料集。那麼將已經在大型資料集上訓練好的模型拿來在自己的任務上繼續訓練,往往會獲得比較好的結果。這是因為模型已經透過大型資料集的學習有了一定的對於任務的理解、對於資料特徵提取的掌握。
而自然語言處理剛好就是一個非常缺乏標註資料,但同時「公開」資料相當豐富的領域(儘管絕大多數公開資料都沒有標註)。遷移學習在此有用武之地。
古人說「熟讀唐詩三百首,不會作詩也會吟」,又說過「書讀百遍,其義自現」。雖然這種講法可能被批評為讀死書,但其實有其道理所在。這個道理就是:語言文字作為一種符號的序列排列,已經存在的各種排列方式(語句)本身就蘊含了特定的規律。例如,最普遍的一個規律就是,兩個詞語如果在序列中鄰近出現的頻率高,那麼它們的語義可能就越相近。想一想,「狗」可能最經常與「犬」一起出現,也可能與「貓」在一篇文章中同時出現,但很少會與「鯨魚」、「螞蟻」或非生物詞彙一起出現。
如果能夠從世界上從古至今已經積累的各種語句中學習到一部分規律,再將此規律應用於自然語言處理任務中,豈不是可以大幅提高模型效果?這種想法被稱為預訓練,屬於Transfer Learning,也是BERT這類模型的核心思想。
所以BERT的訓練一般來說分兩步(但後續的介紹中你會看到三步以上的做法,不必驚訝):
預訓練Pretraining:也就是「熟讀唐詩三百首」、「書讀百遍」的部分。BERT透過一些已經定好的任務進行預訓練,這類任務的要求是不需要進行人工標註,只要利用序列本身已有的資訊即可。原始BERT的預訓練任務有兩個:其一是「克漏字」,隨機將語句中的少數詞語遮住,然後訓練BERT模型猜出被遮住的詞語是什麼;其二是「下一句預測」,將上下相連的兩個句子中的第二句(下一句)以固定比率替換成其他句子,訓練模型判斷這個句子是否是第一句的下一句。
微調Fine-tune:已經預訓練好的模型最擅長的就是預訓練任務,但是實際應用場景中,我們並不需要克漏字和下一句預測。我們需要的是文本的分類、命名實體識別、問答、摘要等等。要讓已經預訓練好的模型學會實際任務的處理方式,也同時調整它已經學到的文本的表示來適應該任務的文本語義,我們必須做fine-tune。這個步驟是在BERT模型的輸出部分設計一個自己的小模型(通常簡單的線性層即可),讓整個模型的輸出可以符合任務需要。
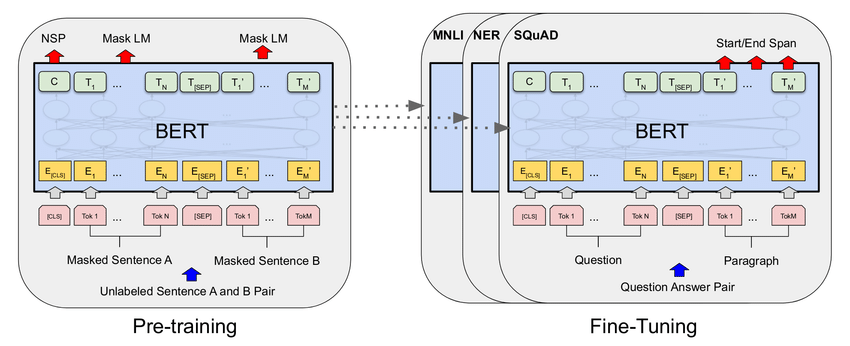
以下是BERT原論文中對於這兩個步驟的示意圖,左邊展示了預訓練過程中的「下一句預測」任務,而右邊則是讓BERT在NER、MNLI、QA等任務中進行微調。
本系列文章將遠遠不止於BERT模型的介紹,坊間已經有太多此類內容了。我將一方面聚焦於BERT系列模型的最新發展,包括新模型的介紹、訓練技巧、提升BERT模型效果的方式。雖然BERT效果好,得到廣泛使用,但從BERT被發明到現在也已過去了三年時間。三年時間,研究者們做了哪些改善?如何讓BERT引領的思潮繼續發揮更大更強的作用?另一方面,也將介紹BERT用於下游任務的實際作法。而如果你想要學習的是BERT模型的具體內部結構、技術細節,那這不是本系列的重點。

