BERT的研究與應用可以分為不同的層次。你可以鑽研BERT的模型技術細節,瞭解它為什麼這麼有效,甚至可以發現其中有問題的設計來加以改進,例如RoBERTa就是FB的工程師在BERT之上的改進成果。你也可以去探討BERT不同層的嵌入之間的差別,來探討模型如何「學習」到語言文本的知識。
但這些關於BERT的研究都在基礎層面,並無法很有效地應用於我們的平常使用中。因為我們和FB、Google的工程師之間有一個巨大差別:缺乏硬體資源,沒法重新預訓練一個完整的BERT模型。所以,當我們在比賽、作業、研究等情境中使用BERT這類預訓練模型時,更關注的是如何在既有的預訓練模型基礎上更好地應用它們,讓它們與Data結合發揮最大效果。
那麼,認識的第一步就是先瞭解BERT的輸入與輸出,這時,不妨先將BERT當作一個魔法黑盒子。其中的內部運作我會在接下來幾天說明。
詞嵌入(Word Embedding)已經在NLP領域中被討論許久了,而這也是理解BERT的一個很好的切入點。
文字是符號,文本是符號的排列,語義就是被編碼進這些符號與符號的排列中。我們認識符號,也能認識符號在不同排列之中的不同意義,是因為我們的大腦對於語言符號會形成一定的「理解」,將其轉化為我們腦中可以讓神經元計算、溝通的存在形式。但是計算機沒有這樣的轉化系統,計算機只能理解數字,無法辨識符號。
所以詞嵌入做的事情就是將文字符號轉化為高維度的向量。之所以高維度,是因為語義很複雜,需要較高維度才能充分表現其義。如果你學過特徵抽取,那麼也可以用類似的方式來理解,詞嵌入就是對文本序列中的每一個詞進行特徵抽取。抽取出來的一串特徵值組成了向量。
在BERT模型發明之前,詞嵌入主要由Word2Vec來完成。但Word2Vec的缺點是無法分辨脈絡(Context),也就是說,在Word2Vec所轉換的詞嵌入結果中,一個詞在任何語句中的表示向量都是一樣的。例如:
大自然真美好,我想生活在綠色環境中。
順其自然吧,沒什麼好難過的。
礦泉水是最自然的飲用品。
三句話中的「自然」的語義都不一樣,第一個「自然」指的是自然環境(而且還特指綠色環境),第二個「自然」是指不干預、自由發展,第三個「自然」則是指非人工加工。詞本身沒有變化,變的是在詞語上下的文本脈絡。而BERT正可以彌補這個缺失,讓詞語根據上下文轉換成符合脈絡的嵌入。因此,BERT的輸入必定是一個完整的文本序列。而輸出則是序列中每個詞語對應的多維向量。以下來詳細討論。
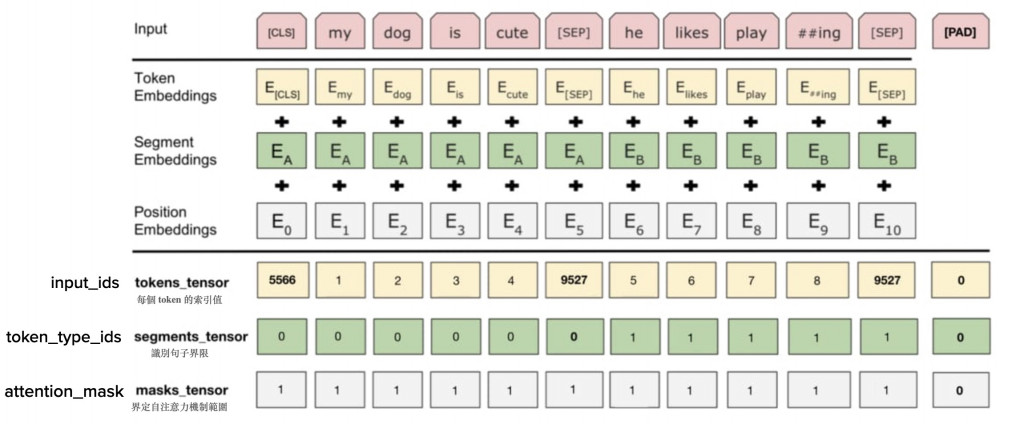
上圖是BERT的輸入的說明,兩道分隔線將圖片分成三個部分,最上層是作為文本序列的輸入(預處理後的原始資料),第二層是實際BERT模型需要的三個輸入,第三層則是在Pytorch、Transformers模組中的三個輸入。我們實際用Python進行模型微調的時候只要輸入最下方第三層的三個輸入即可。
讓我們從上往下進行講解:
可以注意到,文本原文應為「my dog is cute」和「he likes playing」兩個句子,但在這邊預處理後多了許多被[]包裹著的token。它們別代表的意思是:
除了上述三個之外,BERT還有以下兩個特殊token:
BERT模型尚無法讀取預處理後的文本,它仍然需要被更進一步轉換成BERT所需的格式,也就是三個不同類型的嵌入。你可能會問,詞嵌入不是我們的輸出嗎?怎麼在輸入階段就需要嵌入?別慌,在BERT預訓練階段,這些嵌入是隨機初始化並隨著模型的訓練而得到改善的,在微調階段,這些嵌入已經被包含在了模型內部的,你不需要實際輸入它們。所以你也可以將他們看作模型本身的一部分,知道它們是高維向量即可。
以下我簡單做一個說明:
這部分才是我們微調下游任務時實際所需的三個輸入。Transformers是目前使用預訓練語言模型最流行的一個框架,也是一個python模組,它依賴pytorch。你可以在這裡進行更多瞭解,本系列之後的文章也會介紹。
因為上面已經提到,Token Embeddings、Segment Embeddings、Position Embeddings是已經包含在BERT模型中的嵌入,在實際應用過程中,我們只要能撈取到對應的Embeddings即可,那麼怎麼撈取呢?這些嵌入是以字典的形式進行儲存,例如對於Token Embeddings,每一個不同的詞(Token)對應固定ID的嵌入。所以我們只要把詞語轉換為對應的數字id即可。而BERT模型在釋出時也會提供相應的字典,讓你可以進行自動對應。
這部分的三個輸入(下方括號內為此輸入在Transformers中的變量名稱)分別有:
你可能會好奇,為什麼沒有Position Embeddings的對應輸入呢?很簡單,因為序列的index本身就包含在輸入資料內,模型可以替你進行處理。所以雖然Position Embeddings很重要,但是不用自己輸入一個[0,1,2,3,4⋯⋯]的序列。而這部分多的masks_tensor則是為了符合實際訓練的需要,為了進行Batch運算,同一批次輸入的序列長度必須一致,所以需要佔位符號,但運算過程中又要排除佔位符。、
以上就是BERT模型輸入部分的介紹。其實在Transformers中,這個過程可以被簡化為如下兩行,但瞭解其背後原理仍是必要的。
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
inputs = tokenizer("my dog is cute","he likes playing")


 iThome鐵人賽
iThome鐵人賽