
SEO 要做到基本工是很簡單的,就是把 Search Console 上面顯示的錯誤都解決掉,上面說的警告或問題都知道原因且是在已知與合理的狀態,這樣流量就起來了。
雖然 Search Console 除了講問題與警告外,也會講已知道且有效的,但事實上有效的部份是最難除錯的,因為若不是透過 SC 的 API,都只能抓到前 1000 筆資料,而無法知道 1000 筆以外的資訊,不要說更知前做錯的事是那些無法知道,在抓不到全部資料時,也不知道那些是不正確有效的,因為也不可能一個個去 Inspect 檢查。
當然可以隨著一次又一次的除錯或『做對』,每隔一段時間去看這些有效或是錯誤警告資訊的累積,這 1000 筆資料還是可以知道一定的問題點,雖然有時要加過濾條件,但持早會解決的,但前題是要找出所有資訊背後的原因,做對事是不須要修正的,但其他就有很多可能性了。
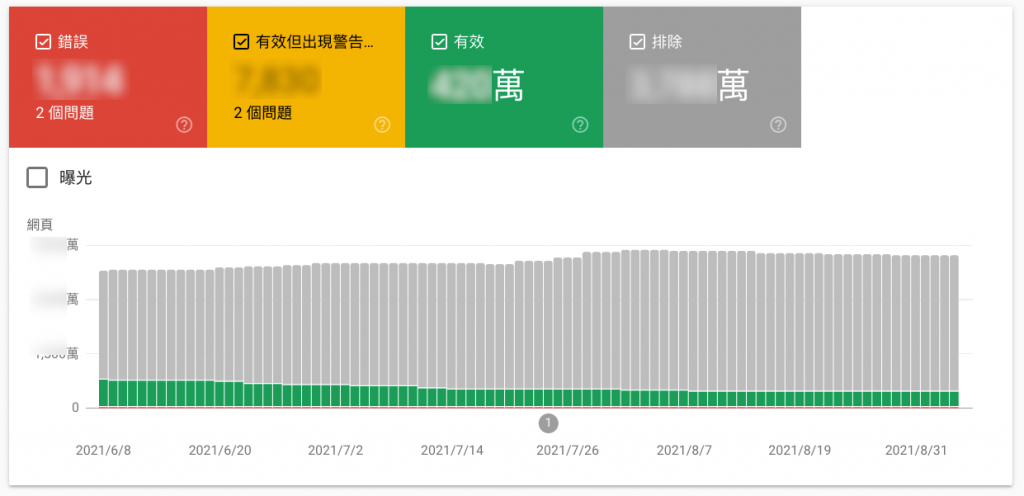
而在涵蓋範圍的項目中有主要的四項,包含前面所說的有效與錯誤,及警告和排除,最重要的是有效是沒有問題的,最該避免的是錯誤,但警告往往也是錯誤的開始,而最麻煩的大概是『排除』這部份。
因為排除這部份就包含幾種狀況:
前四種狀況都是問題不大,若該是這樣而排除就是正常,後三種問題才是有很大的問題,通常是要避免。
在上面七種中,最麻煩的就是『已檢索 目前尚未建立索引』,因為這原因是最不直覺,且可能性也最多,更不要說解決方法,單單原因就有幾個方向:
在這邊會導入兩個重要的指數:
在 SEO 的經驗中,無論是檢索未索引這數值太高本身就不是好事,但有時是無法完全避免,畢竟很多內容好壞的判斷這條線雖然 SEO 是 Google 說了算,但有時要考慮到使用者的動線與經營,還是無法避免。
所以有時是用是其『檢索未索引/有效』這個指標來看,雖然隨著網站越來來越到,檢索未索引無法完全消除,但除有效的指標的目的是發生這問題的占比是須要被控制,在實務上這數值越低,Google 對這網站認為越有價值,隨之流量就進來了。
