在此之前,我們已經介紹過BERT的核心概念遷移學習Transfer Learning以及它的輸入輸出。那麼接下來的問題就是BERT將詞語轉換為包含了上下文資訊的Embedding之後,怎麼繼續使用它們來完成具體的任務。
理論上BERT系列模型可以做所有的NLP任務,這並非是一句誇張。如果說Google的原始版本BERT仍有一些限制,在部分任務上(例如自然語言生成)表現不佳,但如今BERT家族模型已經大大擴充,許多新的模型例如BART、T5等完全可以用來做生成任務,效果也不亞於GPT-2等。而另一方面,下游任務也仍是一個有待開發的領域,BERT的潛力仍被完全挖掘,所以這邊所提的只會是目前最普遍的一些BERT下游任務,但絕不意味着它的界限。
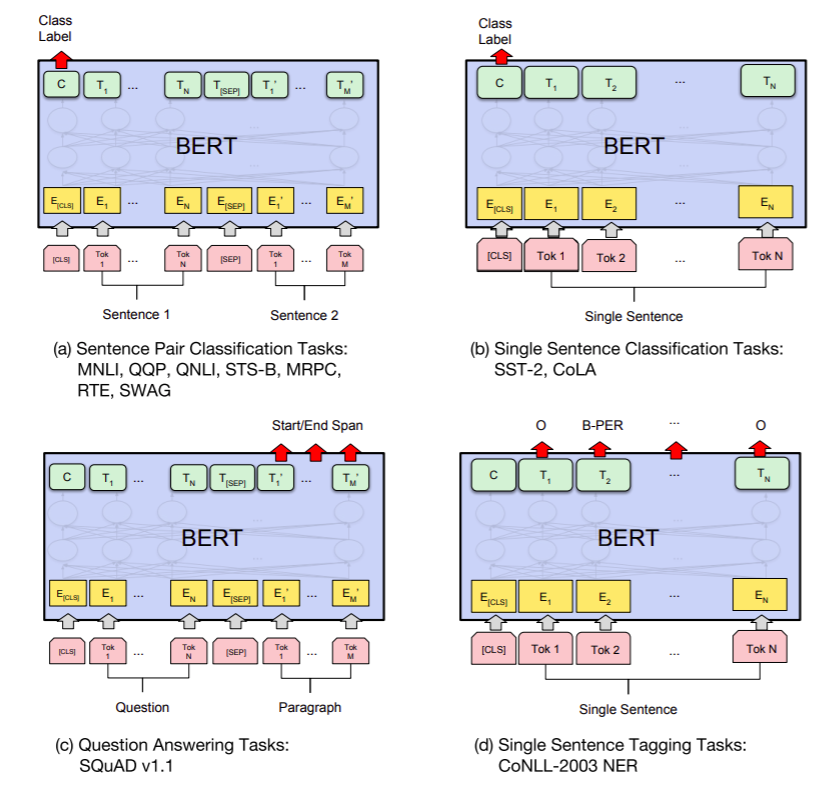
這張圖片來自BERT原paper,作者解釋了BERT在四大下遊任務中應用的方式。主要需要關注的有兩個重點:(1)Token選取,哪個Token的Embedding拿來當作我下游任務的data (2)Output Layer設計,Output Layer即將BERT輸出的Embedding作為輸入,然後直接輸出下游任務可用的數值輸出的模型。
以下,我會分別簡介BERT原文中作者提出的四個任務應用方式:
此類任務的輸入為兩個句子(顧名思義句子對嘛),輸出則是這兩句話的每一個序列的Token Embeddings。而此任務的輸出則是多個標量,也就是此句子對為各類別的可能性。通常會選擇最高的值對應的Class當作答案。在這裡,BERT作者們推薦的做法是將輸出的[CLS]的768維向量Embedding拿去當作這兩個句子的語義表示,然後接上一個簡單的線性層作為Output Layer。原因是,在BERT模型的設計中,[CLS]會有一個全連接層與其他所有token相連,微調後可以當作聚合了整句的資訊。
不過,這樣做是否真的合理呢?我們可以想象到把兩句話的Token Embedding做一個平均應該也可以代表完整的語義,又或者在BERT的輸出之後接一個LSTM或GRU,讓回歸神經網絡替我們完成Embedding的聚合,這應該也是合理的。確實,近期有相關的研究發現[CLS]有不合理的部分,我會在之後文章中介紹。
做法基本跟雙句一樣,取[CLS]過一個線性層即可。
擷取式問答屬於token級別的分類問題。Question和Paragraph被當作兩個單獨序列進行輸入,然後模型輸出的Paragraph部分的Embedding要每個都進行分類,分類也很簡單,判斷每個Token是答案的開始Start Position的機率以及是答案的結尾End Position的機率。所以每個token都會有兩個標量的輸出。而後再進行一些規則方式的後處理即可找出答案範圍,例如最簡單的方式就是取作為Start的機率最高的Token和作為End的紀律最高的Token以及它們中間的所有Token。對於每一個Token進行分類,用簡單的線性層也就足夠了。
NER任務基本跟擷取式問答一致,它的差別主要來自於分類不再只是Start和End,而是分為O、B-PER、I-PER等Class。這種分類標記方法被稱為BIO,是最常用的NER標記方法。O的意思是非命名實體,而B-、I-則指的是某命名實體的開始(Begining)或者中間部分(Intermediate)。每一個不同類別的命名實體都有自己特殊的兩個對應Class。所以命名實體識別任務如果一次識別多個不同類的專有名詞,通常難度就會更高。
以上是BERT原文的四個最常見任務的解決方式,你可能會困惑生成任務去了哪裡?為什麼都只用簡單的線性層?這些設計是固定的嗎?本系列文章只是一點點用最新的研究成果來推翻我們這幾天所說的定式。
今天我們可以先來回答前兩個問題。
為什麼原始BERT沒法做生成任務?
這個問題來自於原始BERT的限制,一方面是預訓練任務,BERT的Pretraining Task都與生成無關,這意味着它沒有相關的任務基礎,如果要強行應用,需要更大的訓練成本,可能也會破壞BERT已經學到的文本表示。BERT類型的模型邏輯一直都是,下游任務與上游任務越相近越好。這意味着模型再次適應的成本小,預訓練的成果也比較能得以被保留。
為什麼都只用簡單的線性層進行分類處理?
BERT的base版本有12層模型疊加,參數量為110M,而large版本的參數量更是三倍。BERT的輸出部分使用簡單線性層是因為BERT模型作為Encoder已經過於龐大和複雜,只用簡單的線性層進行分類就能獲得很好的效果了。而相反,如果後面使用了更複雜的模型例如LSTM,則會因為後接模型完全沒有經過訓練,而導致BERT的良好效果無法得到反饋。甚至,BERT學習到的參數還在反向傳播過程中被破壞了。這就好像你把大學生和小學生都送去寫報告,而大學生負責撰寫報告初稿,小學生則在報告初稿基礎上進行PPT報告,結果很可能兩者都被懲罰,只是因為小學生的報告無法體現大學生的寫作水平。
解決的辦法當然也有,兩個思路,要麼一開始就乾脆凍結BERT模型的參數更新,只讓後接模型進行學習,到一定階段後再引入BERT模型的更新。要麼就是讓兩者取不同的學習率,後接模型的學習率要遠大於BERT模型(至少10倍),每次報告差的時候嚴厲懲罰小學生,讓其改進,而對大學生則只是略微提醒。

