上一回我們將詞性標籤依序排列建構出片語組塊( phrase chunk ),描繪出相應的分析樹,藉由簡單的文法結構來分析句子。當我們在進行語塊分析時並不會要求建構出完整的分析樹,因此語塊分析屬於淺層句法分析( shallow parsing )的範疇。我們今天將延續對於語塊分析的探討,以及如何利用構造簡短的語塊就能在文本資料中搜尋並提取必要的資訊,實現資訊檢索( information retrieval, IR )。
Not all applications require a complete syntactic analysis, and often a full parse provides more information than needed. One example is Information Retrieval, for which it may be enough to find simple noun phrases and verb phrases. Text chunking usually provides enough syntactic information for several such applications.
文字出處:A Machine Learning Approach for Portuguese Text Chunking (2011)
不同的分塊方式會得到不同的分析樹
圖片出處:New open access resource will support text mining and natural language processing
一般而言,體現任何文法結構的語塊都可以被形式上表示為:
chunk = "grammar_name: {<.*>+}"
前面的 grammar_name 表示語塊的名稱,我們可自行命名,例如 NP ( noun phrase :名詞片語)、 RC ( relative clause :關係子句)等等;後面{ }中表示代表詞性標籤序列的正則表達式,例如<VB>表示一般原形動詞( verb, base form )、<CC>則表示對等連接詞( coordinating conjunction )。
之前我們透過了蒐集欲比對的詞性標籤,按順序進行排列,以建構符合某一文法的片語分塊。這次我們不妨逆向思考,考慮濾除不想要的詞性來構造語塊。以名詞片語為例,具有名詞功能的詞組應當是不包含任何動詞以及介係詞(如 in 、 with 、 among 等)且不等於從屬連接詞(如 before 、 when 、 where )的。因此考慮所有不等於 <VB.?> 且不等於 <IN> 的詞性標籤,就構成了名詞片語的分塊:
# alternative of a noun phrase chunk
np_chunk = """NP: {<.*>+} # any part of speech
}<VB.?|IN>+{ # any verb, preposition or subordinating conjunction """
{ }裡擺放的是欲蒐集的詞性標籤,} {中則擺放不想蒐集的詞性標籤,這個技巧是為語塊濾除( chunk filtering ),正是集合的差集運算。
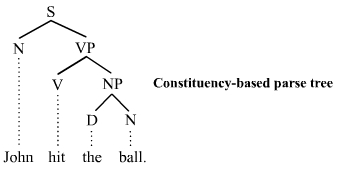
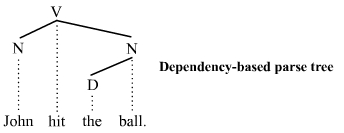
自然語言處理中有大致可分為兩類分析手法:
基於成分句法分析的分析樹
基於依存句法分析的分析樹
介紹完了文法解析之後,我們接下來瀏覽一篇新聞報導,藉由一系列前處理、詞性標籤以及語塊分析的技巧,找出文本中的關鍵資訊。
我們預先寫好兩個模組:tokenise_words.py 以及 chunk_counters.py
以下為 tokenise_words 模組:將清理過的字串進行斷句與斷詞
# filename: tokenise_words.py
from nltk.tokenize import PunktSentenceTokenizer, word_tokenize
def word_sentence_tokenise(text):
"""
text: clean text
-----------------------------
Step 1: sentence segmenation
Step 2: tokenisation
"""
sentence_tokeniser = PunktSentenceTokenizer(text)
# sentence tokenise text
sentence_tokenised = sentence_tokeniser.tokenize(text)
# create a list to hold word tokenised sentences
word_tokenised = list()
# for-loop through each tokenized sentence in sentence_tokenized
for tokenized_sentence in sentence_tokenised:
# word tokenize each sentence and append to word_tokenized
word_tokenised.append(word_tokenize(tokenized_sentence))
return word_tokenised
接下來是計算 chunk_counters 模組:
# filename: chunk_counters.py
from collections import Counter
def np_chunk_counter(chunked_sentences, rmvStopWords = True):
"""
Pulls chunks out of chunked sentence and finds the most common chunks
"""
chunks = list()
# extract NP chunks
for chunked_sentence in chunked_sentences:
for subtree in chunked_sentence.subtrees(filter = lambda t: t.label() == "NP"):
chunks.append(tuple(subtree))
chunk_counter = Counter()
for chunk in chunks:
# increase counter of specific chunk by 1
chunk_counter[chunk] += 1
print("chunk_counter:", chunk_counter)
# return 30 most frequent chunks
return chunk_counter.most_common(30)
def vp_chunk_counter(chunked_sentences, rmvStopWords = True):
"""
Pulls chunks out of chunked sentence and finds the most common chunks
"""
chunks = list()
# extract VP chunks
for chunked_sentence in chunked_sentences:
for subtree in chunked_sentence.subtrees(filter = lambda t: t.label() == "VP"):
chunks.append(tuple(subtree))
chunk_counter = Counter()
for chunk in chunks:
# increase counter of specific chunk by 1
chunk_counter[chunk] += 1
# remove stop words from statistical result
print("chunk_counter:", chunk_counter)
# return 30 most frequent chunks
return chunk_counter.most_common(30)
回到主函式 main.py ,引入 NLTK 模組以及我們剛剛定義好的函式:
# filename: main.py
from nltk import pos_tag, RegexpParser
from tokenise_words import word_sentence_tokenise
from chunk_counters import np_chunk_counter, vp_chunk_counter
我們引用了今日的BBC新聞 Facebook under fire over secret teen research 做為欲檢索的資料,以下引入之並進行前處理(小寫轉換 → 斷句 → 斷詞):
with open("data/bbc_news.txt", encoding = "utf-8") as f:
text = f.read().lower()
word_tokenised_text = word_sentence_tokenise(text)
下一步,標註詞性:
pos_tagged_text = list()
for word_tokenised_sent in tokenised_text:
pos_tagged_text.append(pos_tag(word_tokenised_sent))
定義名詞片語分塊和動詞片語分塊並且建構語法剖析器( parser ):
# define chunk grammars
np_chunk_grammar = "NP: {<DT>?<JJ>*<NN>}"
vp_chunk_grammar = "VP: {<DT>?<JJ>*<NN><VB.?><RB.?>?}"
# creates chunk parsers
np_chunk_parser = RegexpParser(np_chunk_grammar)
vp_chunk_parser = RegexpParser(vp_chunk_grammar)
緊接著,開始分析每一個已經進行斷詞的句子( chunking ):
np_chunked_text = list()
vp_chunked_text = list()
for pos_tagged_sentence in pos_tagged_text:
np_chunked_text.append(np_chunk_parser.parse(pos_tagged_sentence))
vp_chunked_text.append(vp_chunk_parser.parse(pos_tagged_sentence))
最後,利用稍早定義在模組 chunk_counters 的函式 np_chunk_counter 取出最常出現的名詞片語:
# List the most common 30 NP chunks
most_common_np_chunks = np_chunk_counter(np_chunked_text, rmvStopWords = rmvStopWords)
print(most_common_np_chunks)
顯示出現頻率最高的名詞片語排名: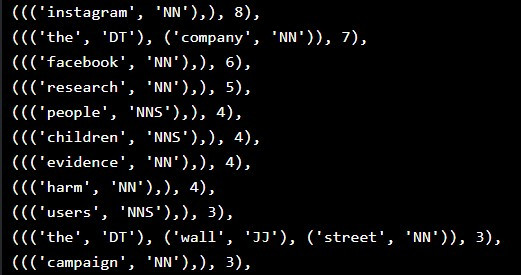
以及最常出現的動詞片語:
# List the most common 30 VP chunks
most_common_vp_chunks = vp_chunk_counter(vp_chunked_text, rmvStopWords = rmvStopWords)
print(most_common_vp_chunks)
顯示出現頻率最高的名詞片語排名:
由名詞和動詞片語分析的結果,我們可以推估這篇文章主要傳達的資訊為:「 研究指出 Facebook 、 Instagram 等社群平台對青少年造成不良的影響。」
有了語塊分析的技巧,我們可以在未真正閱讀文本之前即先檢索關鍵資訊,這樣能夠幫助我們篩選目標,例如在圖書館查詢書籍等等。此時此刻,我們已經踏入自然語言處理的大門,自然語言處理基礎也告一段落。從明天開始,我將會介紹自然語言的量化手法以及常見的模型。おやすみなさい!



 iThome鐵人賽
iThome鐵人賽