前面我們介紹了影像辨識的資料前處理方法,今天就要開始教大家架設一個神經網路,並將資料丟入來看看實際的效果,還不了解神經網路的運作概念可以先參考DAY19喔~
一般的神經網路架構可以分為輸入層、隱藏層、輸出層,輸入層將圖片像素陣列讀取進來,經過隱藏層來做捲積運算、池化...等特徵提取以及權重計算,最後由輸出層彙整預測結果並輸出,幾乎所有的神經網路都是基於這個架構來組成的,見下圖: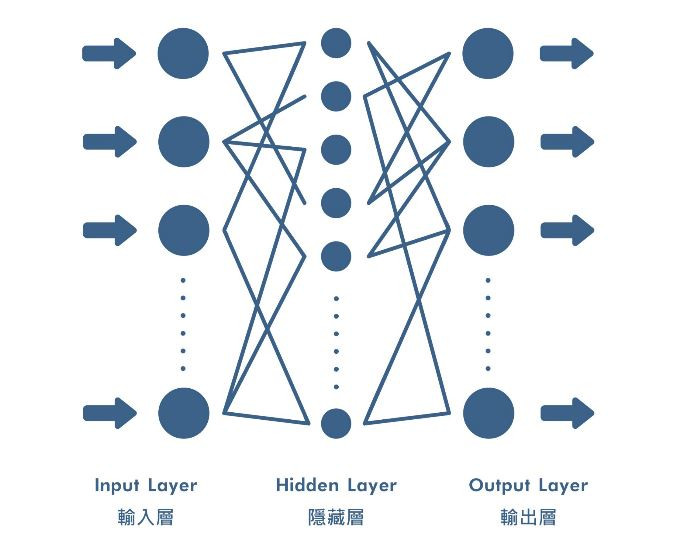
當然,輸入層及輸出層比較簡單、變化相對來說也比較小,因此模型存在最多的差異就是在隱藏層,發展至今,市面上已經有無數個深度學習模型被提出來,全世界的學者、研究專家都在往更高準確率、更快的速度、更小的模型邁進,而具體來說沒有哪個模型是絕對最強的,在使用前要考慮很多面向,例如資料適合哪種架構的模型,或是用途等問題。
支援訓練類神經網路的API有Tensorflow、Pytorch...等,使用者會依照自己Coding的習慣或是一些API提供的好用功能來選擇,今天我們使用的是Tensorflow的API:Keras來做示範,近幾年大家也越來越愛使用Pytorch,Google上也開始比較找的到資源去學習,這邊也推薦大家嘗試不同的工具喔!
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import categorical_crossentropy
model = Sequential([
Dense(units=16, input_shape=(1,), activation='relu'),
Dense(units=32, activation='relu'),
Dense(units=2, activation='softmax')
])
等等?一個模型這樣就架設好了?是的,架設一個神經網路模型就是如此簡單,使用這些強大的API就能輕鬆做到,當然這僅僅是一個最基礎的架構,目的是先了解其運作的架構。
稍微解釋一下上面的模型架構,我們一開始建立的Sequential大家可以想像成一個容器,模型就是一層一層的堆在這個容器裡;而Dense代表的是全連接層(Fully Conected Layer),因為層層的連接在一起而被稱為Dense Layer;input_shape則是輸入層的維度,根據資料調整;最後是激活函數(Activation),可以把它想像成是對信息的加工,將輸入後的數值信息加工後再輸出到下一層去計算。
model.summary()
#param代表總參數量

為了讓我們的模型可以進入訓練階段,我們還需要幫它"裝備"一下,加強它的戰鬥力。
model.compile(
optimizer=Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
參數說明:
optimizer:一種優化器,主要幫助是模型梯度下降時能找到最優解。
learning_rate:學習率,模型收斂的速度
loss:損失函數,模型的損失值越小越好
metrics:評估指標,使用Accuracy來評估
模型架設完畢後我們就可以拿資料來訓練看看,這裡我自己隨機生成數據來做訓練。
這邊我們自己創造一個情境,假設進行一項疫苗的臨床實驗,30歲以下的年輕人打疫苗後有5%的人會出現不適狀況(Label_1)、95%的人不會(Label_0);而30歲以上的人有95%的人打完後會出現不適狀況(Label_1)、5%的人會(Label_0)。
import numpy as np
from random import randint
train_samples = []
train_labels = []
for i in range(50):
# 5%的年輕人會有不適症狀
random_young = randint(1,30)
train_samples.append(random_young)
train_labels.append(1)
# 5%的年長者不會有不適症狀
random_old = randint(31,100)
train_samples.append(random_old)
train_labels.append(0)
for i in range(1000):
# 95%的年輕人不會有不適症狀
random_young = randint(1,30)
train_samples.append(random_young)
train_labels.append(0)
# 95%的年長者會有不適症狀
random_old = randint(31,100)
train_samples.append(random_old)
train_labels.append(1)
from sklearn.utils import shuffle
train_samples = np.array(train_samples)
train_labels = np.array(train_labels)
train_samples, train_labels = shuffle(train_samples, train_labels)
這樣一來我們就創造出2100筆資料,其中包含各個年齡以及其對應的Label。
model.fit(train_samples,train_labels,batch_size=10, epochs=5, verbose=2)
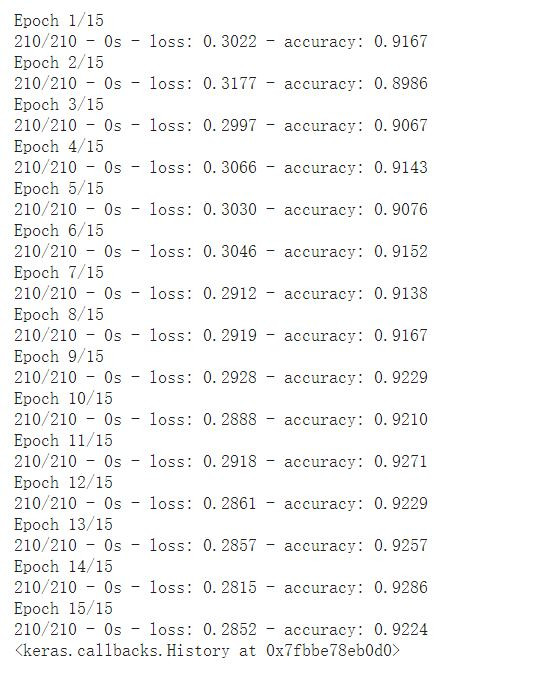
大功告成啦!這樣我們就訓練好一個預測疫苗反應的模型了,可以看到準確率來到0.92,以一個非常簡單的架構所建立的模型來說已經算是不錯了,自己動手試試看吧!
今天我們介紹了一個基本的神經網路中該有的架構,當然有一些超參數或是函數的應用我們都只是簡單帶過而已,目的是為了讓大家先熟悉神經網路的架構,並實際架設了一個簡單的模型和數據來訓練,之後的章節會再慢慢帶大家深入了解其他概念,再會啦!


 iThome鐵人賽
iThome鐵人賽