前一天提到說 CTC 提出了一個新的概念: 空白(blank),但在最開始的 CTC 設計中是沒有使用空白的,只有移除連續的相同字母,但是這樣會產生兩個問題:
在解碼部份,理想上是以最大機率的序列 作為輸入資料 x 的預測結果
CTC 在實作上有兩個解碼方法:最佳路徑解碼(Best path decoding)和前綴搜尋解
碼(Prefix path decoding)。最佳路徑解碼的作法是選取機率最大的路徑所對應到的序列
作為預測結果,如下:
而機率最大的路徑可以透過串聯每一個時間點最大機率的輸出標註來得到,但是在
某些情況下這樣的作法不一定會得到最佳解,如下圖 1,若是選擇機率最大的路徑
會得到空白,但是輸出是 'A' 的所有可能路徑的總和卻比'空白'的機率來的高。前
綴搜尋解碼是透過沿著有效路徑計算累積機率最大的作為預測結果,如下圖 2,圖
中的 X 和 Y 表示擴展節點,e 表示停止在其父節點。擴展節點上方的數字表示路徑從
頭到這點的機率。e 結點上方的數字表示停在其父節點的機率。我們將根(Root)視為
第0層,第一層的 Y 不往下擴展是因為同層的 X 和 X 下層的 Y 的機率都比他高。從Alex
Graves 的實驗得知,前綴搜尋解碼在預測上會比使用最佳路徑解碼還準確,但是所花費的時間以及計算量也比最佳路徑解碼還多。
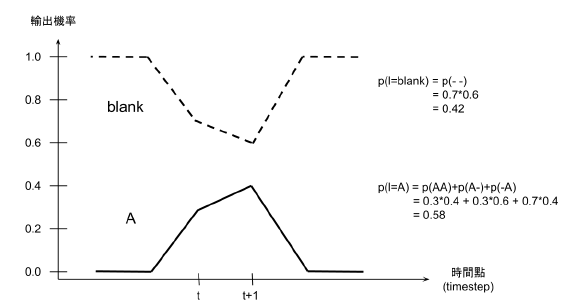
圖1: 使用最佳路徑解碼的問題。若是選擇機率最大的路徑會得到'空白' (圖的右上算
式),但是輸出是'A'的所有可能路徑的機率總和卻比輸出'空白'的機率高(圖的右下算
式)
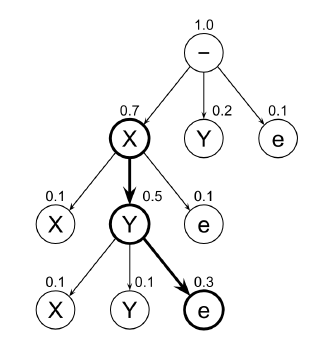
圖2: 前綴搜尋解碼。X和Y表示擴展節點,e表示停止在其父節點。擴展節點上方的數字表示路徑從頭到這點的機率。e結點上方的數字表示停在其父節點的機率
在花了幾天的時間說明介紹 end-to-end 相關的模型架構方法之後我們即將要進入實作的部分 ! 首先登場的會是語音特徵擷取與正規化的部分,那我們明天見 !

