昨天我們使用了 Python 自然語言處理套件 spaCy 預訓練好的 word embedding model 將英文單詞轉換成為高維度的向量。今天就讓我們接著談我們如何衡量單詞在意義上的遠近吧!
我們將單詞表示成高維度的向量,根據 word embedding 的特性:兩兩愈是意義相近的單詞,它們的向量距離就愈接近。因此我們可以純然地從向量之間的距離大小,反推單詞的語意親疏程度。以下分別介紹用來測量向量距離常見的三種方式:
歐氏距離( Euclidean Distance ):
在中學時期我們學習過測量向量距離的方式-兩向量箭頭端點相連直線段的長度,這也是歐氏空間( Euclidean space )中最常被使用來距離測定的方式。在n維空間上的歐氏距離定義如下: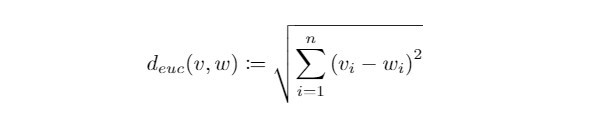
曼哈頓距離( Manhattan Distance ):
有別於我們最習慣的直線距離,曼哈頓距離考慮兩點之間方格線長度的總和,因此又被稱為方格線距離,在n維空間上的曼哈頓距離定義如下: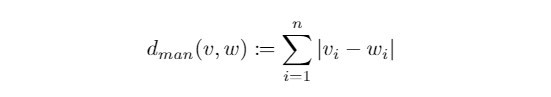
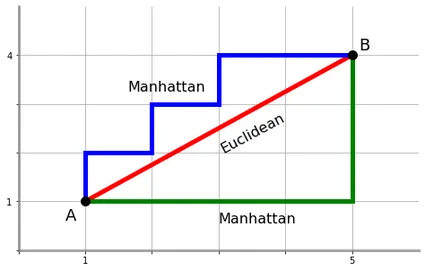
歐氏距離 v.s. 曼哈頓距離
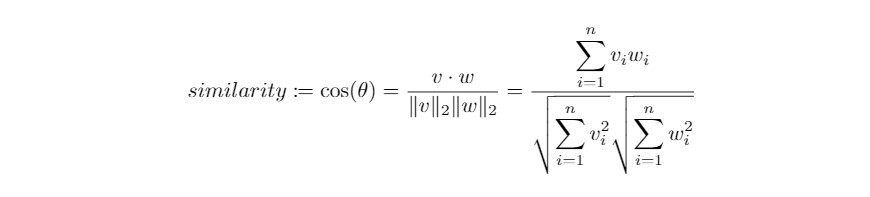

word embedding 向量將語意資訊隱藏在各個維度的數值裡。向量的方向有意義,而長度並不重要,因此用 cosine distance 來衡量 word embeddings 的距離再適合不過了!因著 cosine distance 可以衡量語意的相似程度,又被稱為 cosine similarity 。在自然語言處理的實務上,使用cosine distance 來衡量距離有以下好處:
夾角大小和語意相似度的關係
圖片來源:www.bbsmax.com
在向量長度不重要的情境中,cosine similarity 可用來衡量向量之間的距離:
Cosine similarity is generally used as a metric for measuring distance when the magnitude of the vectors does not matter. This happens for example when working with text data represented by word counts. We could assume that when a word (e.g. science) occurs more frequent in document 1 than it does in document 2, that document 1 is more related to the topic of science. However, it could also be the case that we are working with documents of uneven lengths (Wikipedia articles for example). Then, science probably occurred more in document 1 just because it was way longer than document 2. Cosine similarity corrects for this.文字來源:cmry.github.io
我們使用 spaCy 套件中預先訓練好的英文 word embedding model 。我們依舊使用最輕量的模型 en_core_web_sm ,若要向量化更廣泛的單詞,可以考慮下載其他模型: en_core_web_md、en_core_web_lg、en_core_web_trf 。
我們先將以下三個單詞 like、love、hate 表示成向量,並且比較兩兩之間的相似程度:
import spacy
# import cosine distance metric
from scipy.spatial.distance import cosine
nlp = spacy.load("en_core_web_sm")
# vectorise words "like", "love", "hate"
word_1 = nlp("like").vector
word_2 = nlp("love").vector
word_3 = nlp("hate").vector
# compare semantic similarities
dist_1_2 = cosine(word_1, word_2)
dist_2_3 = cosine(word_2, word_3)
dist_3_1 = cosine(word_3, word_1)
print("similarity between 'like' and 'love': ", dist_1_2)
print("similarity between 'love'and 'hate': ", dist_2_3)
print("similarity between 'hate' and 'like': ", dist_3_1)
檢視一下兩兩單詞之間的 cosine similarity:
我們發現 like 與 love 非常相似,反之 love 與 hate 幾乎無相關,這與我們的認知一致。
至於 like 與 hate 的相似度高達81%,說明它們經常出現在相同上下文當中。而這與模型訓練的文件選擇有關,下一集我們就來訓練自己的 word embedding model!
今天的介紹就到這裡,為期四天的中秋連假終於結束,明天又是上班日了!不知各位會不會有收假症候群呢?廢話不多說,期待與各位在下一篇文章相見,晚安!



 iThome鐵人賽
iThome鐵人賽