因前篇談到透過api.kbars抓取1分K的資料內容,但我們在看盤或盤後分析時,可能會用到其它類型的K線,例如:5分K或15分K。本篇會先說明1分K要如儲存並轉換成其它的K線資料。
https://datacarpentry.org/python-ecology-lesson/03-index-slice-subset/
在上一篇,我們說到api.kbars抓的資料最小單位就是一個交易日,若我們要抓這個交易日中的特定時間區間的kbar資料,就只能透過DataFrames做篩選。
首先,透過DataFrame.head()及DataFrame.tail(),可以取得DataFrame最前面或最後面的資料,在呼叫head()或tail()時,可以指定所要回傳的資料筆數;若沒有指定,預設就是回傳5筆資料
df.head() #回傳最前面的資料,沒有指定資料筆數,預設為5筆
df.tail(3) #回傳最後面3筆的資料
也可以透過Slice的方式,取得特定幾筆的資料。這個功能與Python中List的Slice操作方式相同
df[start:stop:step]
# start 開始位置,不指定則以第一個元素開始
# stop 停止位置,不指定則取到最後一個元素
# step 每個元素間的位移量
df[:10] #從index 0的元素開始取,當元素的index為10時則停止
df[:10:2] #從index 0的元素開始取,當元素的index為10時則停止,每個元素位移量為2
df[1:10:2] #從index 1的元素開始取,當元素的index為10時則停止,每個元素位移量為2
df[1:9:2] #從index 1的元素開始取,當元素的index為9時則停止,每個元素位移量為2
除了上述一般Slice的方式,DataFrame更強的地方在於,可以依資料內容指定特殊條件,例如:
df.ts = pd.to_datetime(df.ts)
df[df.ts >= '13:00:00'] #依df.ts欄位,抓'13:00:00'之後的kbar資料
同樣的方式,也可以套用在tick資料上面
df = pd.DataFrame({**ticks})
df.ts = pd.to_datetime(df.ts)
df[df.volume > 100] #抓成交量大於100的tick資料
如果要單純抓某些欄位的資料,可以用下列的方式
df.ts #抓ts欄位中的資料
df['ts'] #與上一行的作用相同
SQLite - 維基百科介紹:https://zh.wikipedia.org/wiki/SQLite
SQLite是一個輕量級的資料庫,在使用時並不像其它資料庫需先安裝DB Server及其它設定,它也可以說是目前最多人使用的資料庫,因為在手機的通訊軟體app,都是用SQLite來儲存訊息紀錄。
目前若要查看sqlite資料庫內容,可用許多軟體。
這裡介紹使用DB Browser for SQLite
DB Browser for SQLite:https://sqlitebrowser.org/
打開上面的網址後,點「Download」
程式有分安裝版及免安裝版,這裡我選擇「DB Browser for SQLite - .zip (no installer) for 64-bit Windows」這個免安裝版本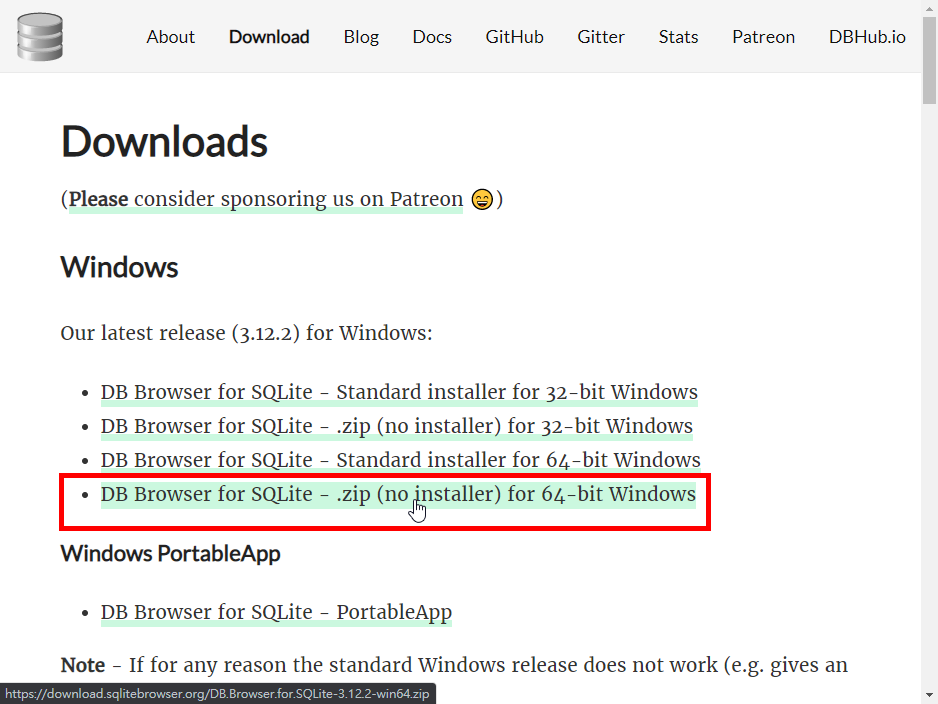
下載完成並解壓縮後,程式的執行檔為「DB Browser for SQLite.exe」這個檔案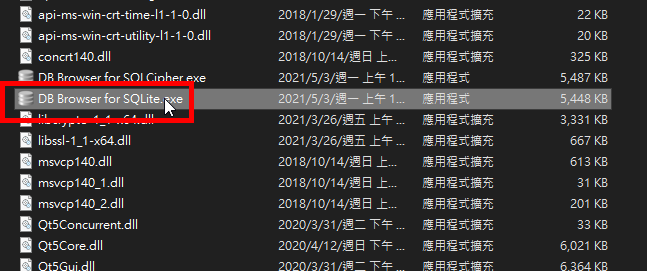
一般我們要把資料儲存至資料庫,需要了解基本的SQL語法操作,並透過SQL語法將資料寫入資料庫的Table中。但是透過Pandas,我們可以先不用了解SQL語法,就可將DataFrame的資料儲存至資料庫中。
DataFrame.to_sql,可參考官方的說明文件:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_sql.html
以下範例為將kbars資料,稍做調整後儲存至SQLite中
from dotenv import load_dotenv
import os
import shioaji as sj
import pandas as pd
import sqlite3 #匯入sqlite3模組
load_dotenv('D:\\python\\shioaji\\.env')
api = sj.Shioaji()
api.login(
person_id=os.getenv('YOUR_PERSON_ID'),
passwd=os.getenv('YOUR_PASSWORD')
)
conn = sqlite3.connect('shioaji.db') #建立資料庫連線,若檔案不存在,會自動建立
#抓2330台積電,2021-08-02~2021-09-10間所有ticks
kbars = api.kbars(api.Contracts.Stocks["2330"], start="2021-08-02", end="2021-09-10")
df = pd.DataFrame({**kbars})
df['date'] = pd.to_datetime(df.ts).dt.date #增加date欄位,並將df.ts轉換成日期資料
df['time'] = pd.to_datetime(df.ts).dt.time #增加time欄位,並將df.ts轉換成時間資料
df['code'] = '2330' #增加 code 股票代碼欄位
df.to_sql('stocks_kbars', #所要寫入的Table名稱
conn, #傳入上面所建立的sqlite3.Connection
if_exists='append', #當Table已存在於資料庫中,所要做的動作
index=False #預設為True,設為False表示寫入資料時,不將index欄位寫入
)
if_exists這個參數,預設值為'fail',意思是若Table已存在於資料庫中,就直接跳出錯誤訊息;若設為'append',表示若Table已存在,則保留原本的Table資料,並將新的資料寫入到Table中;若設為'replace',若Table已存在,則在寫入時,會先將原本的Table刪除後重新建立,並將新的資料寫入到Table中。
接著,執行剛才下載的DB Browser for SQLite,並按「打開資料庫」
選擇SQLite所在的資料夾,並選擇資料庫檔案
開啟後,就可以看到Pandas建立的Table
若要查看Table中的資料,請點「Browse Data」
若資料有正常寫入SQLite,可以看到所抓取的kbar資料內容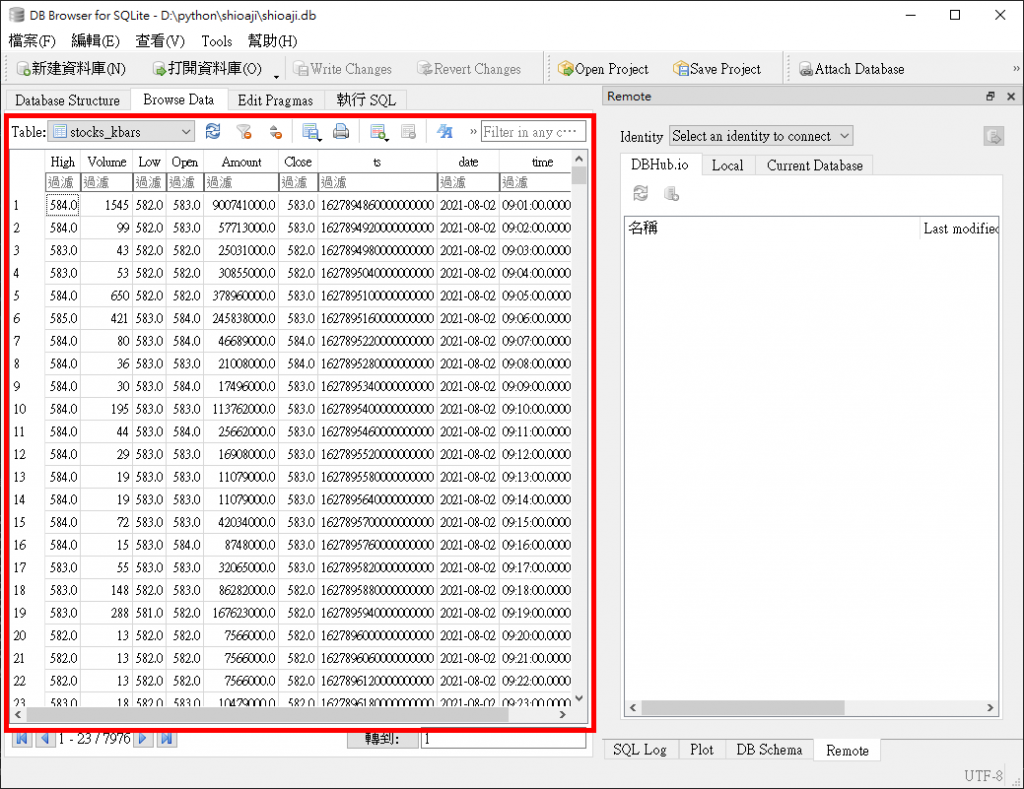
在前面儲存至資料庫時,有提到可以不用先了解SQL語法;但若要直接用Pandas直接將SQLite中的資料讀取出來時,就需要寫到簡單的SQL語法。
import pandas as pd
import sqlite3
conn = sqlite3.connect('shioaji.db') #建立資料庫連線
#從stocks_kbars這個Table中,取得所有資料,並轉換為DataFrame
df = pd.read_sql('SELECT * FROM stocks_kbars', conn)
SQLite 對於剛接觸程式的人,是一個很容易上手的資料庫,透過 Pandas 也可以直接對 SQLite 做存取
如果你想要使用其它的資料庫,可參考以下文章,使用Pandas + SQLAlchemy做存取
https://www.sqlshack.com/introduction-to-sqlalchemy-in-pandas-dataframe/
https://hackersandslackers.com/connecting-pandas-to-a-sql-database-with-sqlalchemy/
前一篇的Kbars中提到,api.kbars抓出來的資料是1分K,若需要5分K或10分K,可以透過pandas.DataFrame.resample達到
官方說明文件:https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.resample.html
以下為將1分K資料轉為5分K的範例:
df.index = df.ts #將ts資料,設定為DataFrame的index
kbars_5min_high = df.High.resample('5min').max() #最高。以5分鐘重新取樣一次後,取最大值
kbars_5min_low = df.Low.resample('5min').min() #最低。以5分鐘重新取樣一次後,取最小值
kbars_5min_close = df.Close.resample('5min').last() #收盤。以5分鐘重新取樣一次後,取最後一筆
kbars_5min_open = df.Open.resample('5min').first() #開盤。以5分鐘重新取樣一次後,取第一筆
透過resample重新取樣後,就可以再透過pandas.concat,將上面的資料重新組合成一份5分K的DataFrame資料
官方說明文件:https://pandas.pydata.org/docs/reference/api/pandas.concat.html
df_5min_kbars = pd.concat([kbars_5min_open, kbars_5min_close, kbars_5min_high, kbars_5min_low], axis=1)
接著執行print(df_5min_kbars.head()),可以看到轉換出來的5分K資料內容
Open Close High Low
ts
2021-09-17 09:00:00 600.0 601.0 601.0 600.0
2021-09-17 09:05:00 601.0 600.0 601.0 600.0
2021-09-17 09:10:00 600.0 601.0 602.0 600.0
2021-09-17 09:15:00 601.0 601.0 602.0 601.0
2021-09-17 09:20:00 602.0 600.0 602.0 600.0
同樣的,若要把1分K資料轉換成10分K資料,只要把resample中的參數改為'10min'即可


 iThome鐵人賽
iThome鐵人賽