
大家午安 ~
昨天我們已經啟用 VPC Flow Log 並且存放到 S3,今天我們會設定 AWS Glue Crawler 自動建立 VPC Log 資料表,以供 Athena 查詢
註:如果想手動建立 VPC Log 資料表,可以參考[1]
那我們就開始吧 GO GO
昨天觀察 VPC Log 的資料,你會發現『每個欄位都是以空格去間隔』,但 Glue Crawler 預設是依據逗號作欄位間隔,故我們需要先增加 Classifiers 來自定義『欲抓取的資料』分隔符號、檔案類型、欄位名稱等設定
Classifier name:自行定義名稱即可
Classifier type:CSV
Column delimiter:Space
Quote symbol:Doublue-quote(“)
Column headings:因我們觀察原始資料是有表格欄位名稱的,故選擇 has headings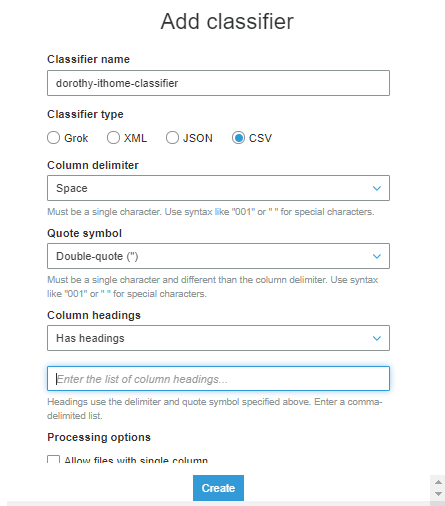

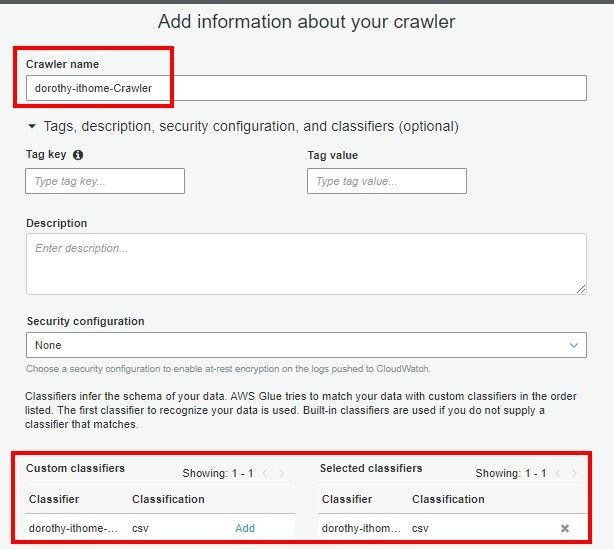
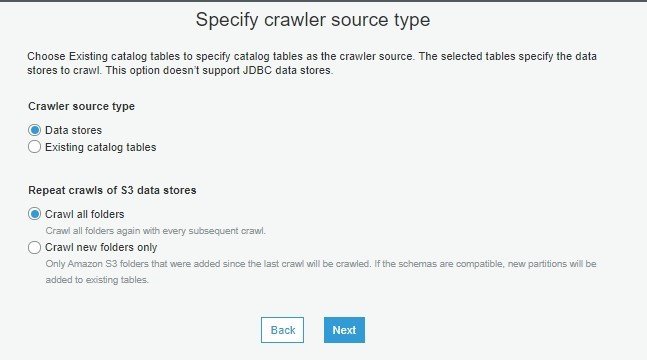
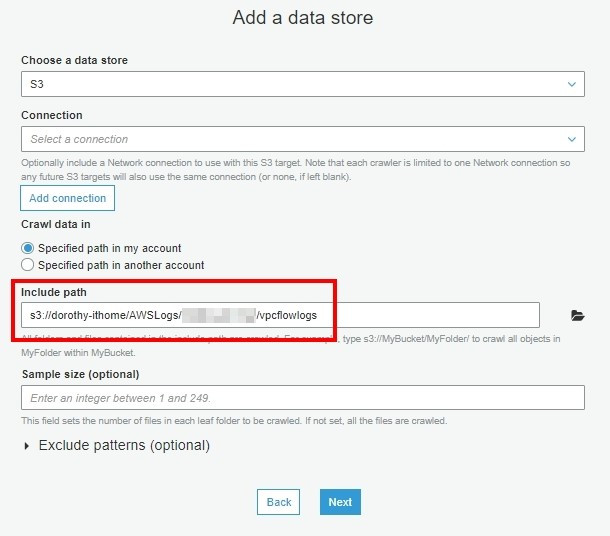
注意:若要使用已存在的 role,那要確認此 role 是否有適當的權限喔~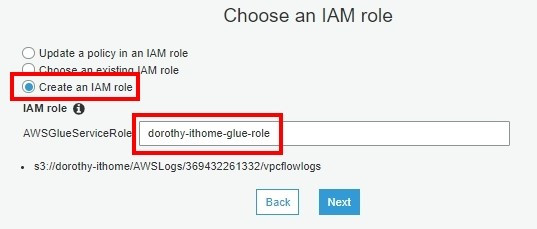
我們這邊選擇手動執行( Run on demand )即可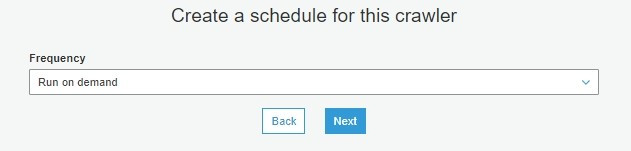
(可以不增加前綴詞,如果有重複名稱,系統會自動加序號,避免資料表名稱重複)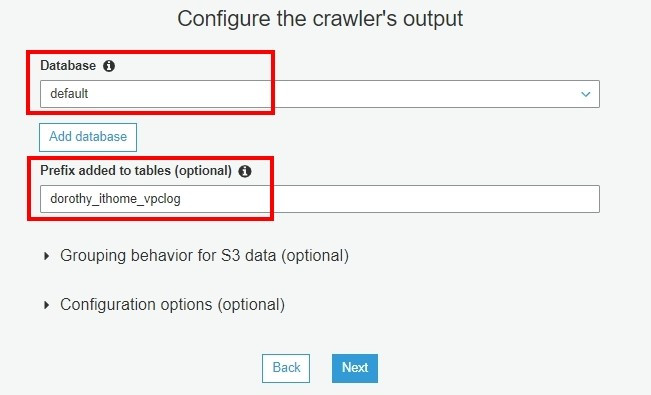
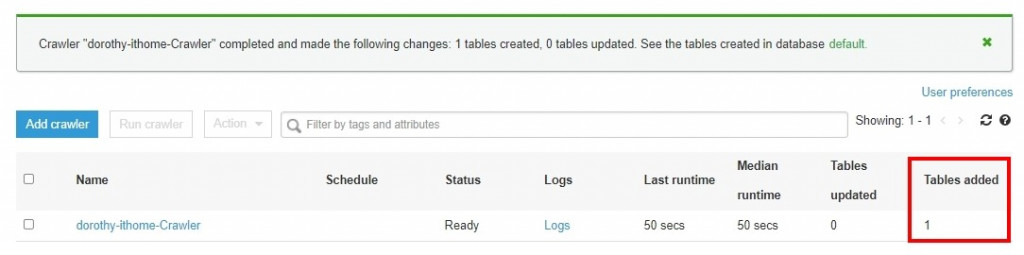
接著我們至左側選單的 Tables,可以看到資料表的欄位以及對應格式,其中有看到幾個欄位名稱為 partition_x,這是什麼呢?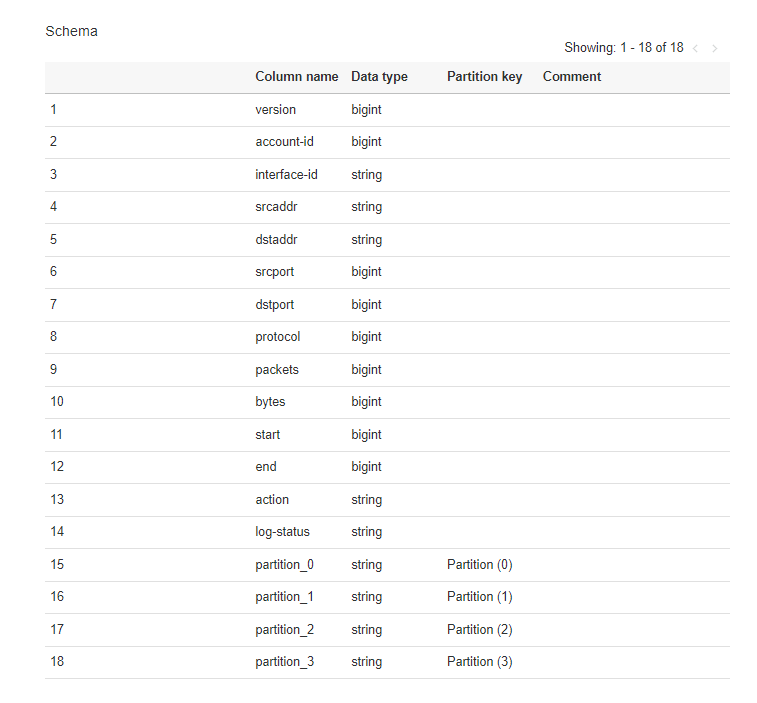
我們點擊 View partitions 可以看到目前 partition 的結構,發現 Glue 自動幫我們將每一層資料夾切分成 partition
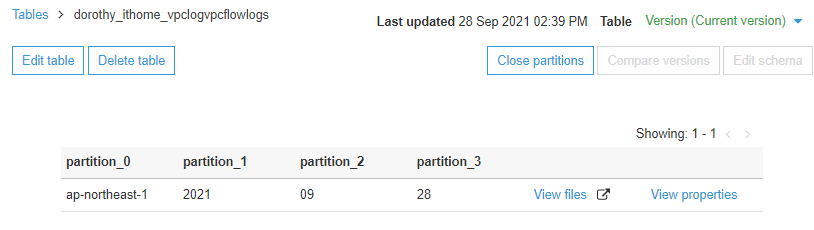
適當的 partition 有助於大量資料查詢,舉例來說:
假設今天我只要搜尋 09 月的資料,如果沒有 partition 的情形下要撈出 09 月資料,Athena 會搜尋指定路徑下每個資料夾,但如果有 partition 並且於 SQL 語法增加 where 篩選,這樣 Athena 僅會搜尋指定的 partition 下資料,有 Partition 可以大大加快查詢速度且費用也會大大減少
除了建立良好的 Partition 外,將資料轉換成 Parquet 這種儲存格式,也是加快查詢速度很好的方式喔! 先前我們有教學用 Lambda 將 json 轉換成 parquet,我們也可以透過 AWS Glue job 來完成這個轉換並且依據個人需求切出你需要的 Partition 結構~
明天我們就會來實作 – 如何用 AWS Glue job 進行 Parquet 格式轉換
明天見囉 : D ~
如果有任何指點與建議,也歡迎留言交流,一起漫步在 Data on AWS 中。
[1] 手動為 VPC 日誌建立資料表
https://docs.aws.amazon.com/zh_tw/athena/latest/ug/vpc-flow-logs.html

 iThome鐵人賽
iThome鐵人賽