=== 書接上回 [Day 21] Edge Impulse + BLE Sense實現喚醒詞辨識(中) ===
通常不滿意模型訓練出來的成果,可透過下列方式來調整。
變更調整後,可以於「Impulse design - NN Classifier」頁面按下【Start Training】,或者在「Retrain model」頁面按下【Train Model】重新訓練模型即可。
模型訓練好了,當然要來驗證一下。在前面章節資料有提到,除了訓練集外,另有保留20%的測試集(4個分類各4筆, 共16筆資料),這些是沒有參與訓練過程的。接著進入「模型測試(Model Testing)」頁面,按下【Classify all】就能自動把測試集全部內容進行推論,最後會得到每一筆資料的辨識結果和總體精確度,四個分類的混淆矩陣及特徵分佈結果圖,如圖Fig. 22-1所示。系統預設是否分類正確的門檻值是0.6,如有需要可自行點擊【Classify all】旁的點符號進入修改。如果不滿意測試精確度,可參考「重新訓練」小節的說明。
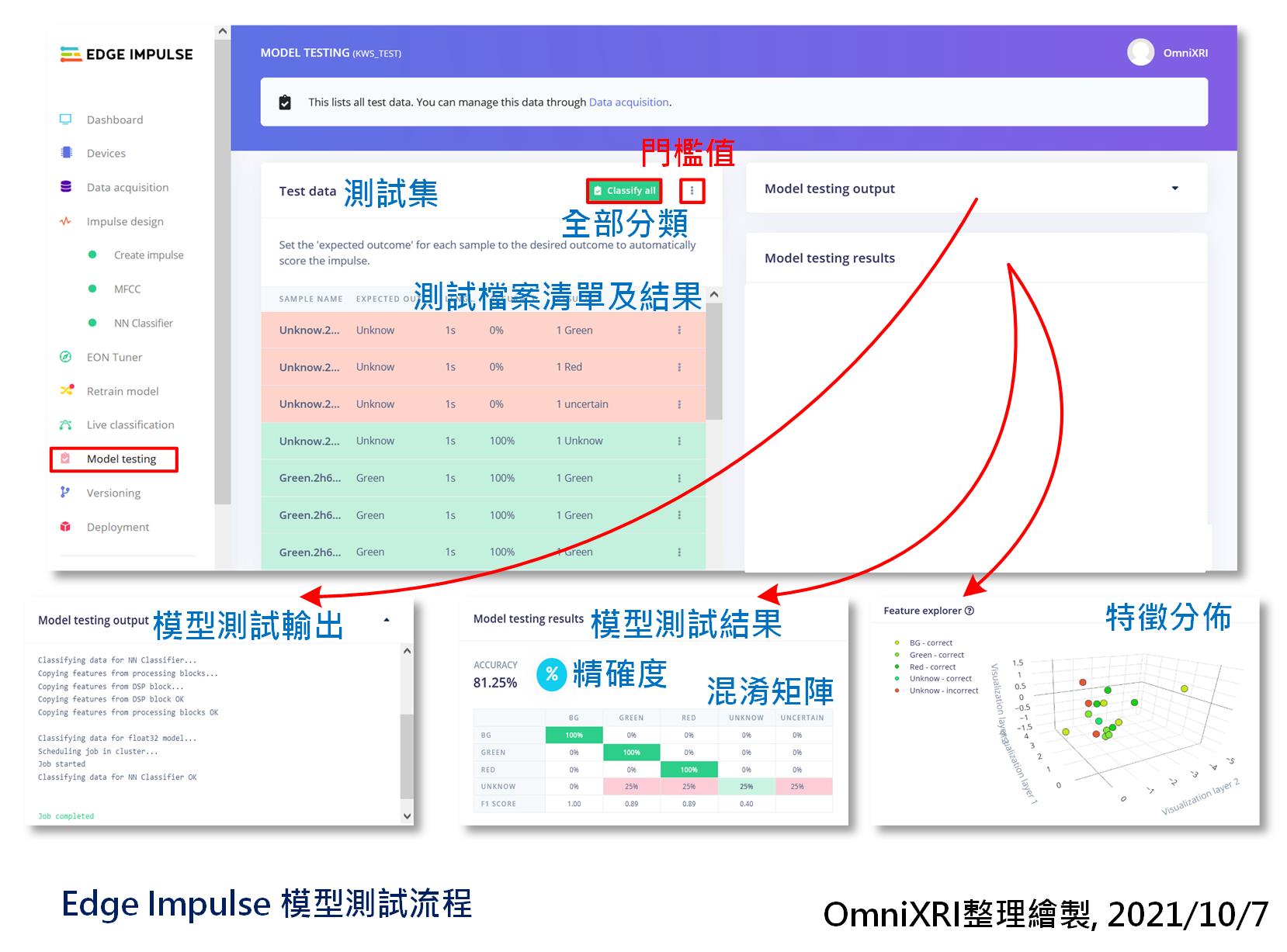
Fig. 22-1 Edge Impulse模型測試流程。(OmniXRI整理繪製, 2021/10/7)
再來可即時收錄一段聲音來做測試。切換到「即時分類(Live Classification)」頁面,設定取樣時間長度及取樣頻率。通常可設長一點,10到20秒,可一次說出不同分類的單詞內容(含不發聲的背景聲,單詞間要有間歇),方便後面可一次測完不同分類。當按下【Start Sampling】等待數秒就會開始錄製,完成後會自動上傳到雲端同時產出分類結果報告,包括各分類的統計數量、每筆資料每個分類的置信度(機率)。點擊每資料還可觀看對應的原始聲音信號波形,按下三角形播放鍵時還可回聽,方便檢查分類是否正確。最後還會把所有分割出的內容特徵分佈圖展示出來。如圖Fig. 22-2所示。
系統預設取樣移動視窗為500ms,一次擷取1000ms來分類,這裡不像前面資料擷取時有自動分割的功能,而是模仿在MCU上連續不停的取樣分析,所以如果對於移動距離和檢測門檻值不滿意時可自行調整。
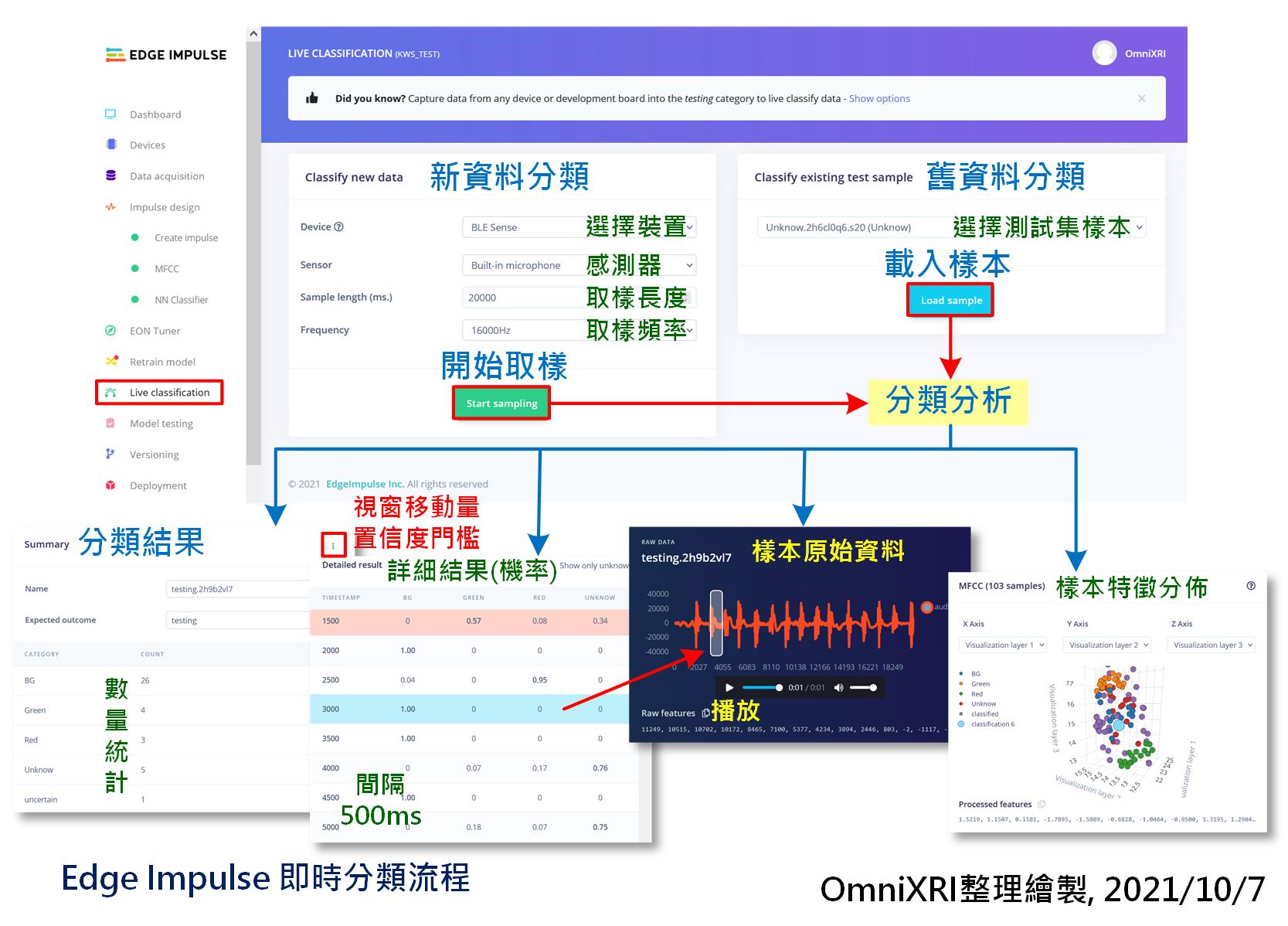
Fig. 22-2 Edge Impulse即時分類流程。(OmniXRI整理繪製, 2021/10/7)
這是Edge Impulse 2021/9 才剛推出的新功能,可暫時忽略跳過這個步驟。EON全名Edge Optimized Neural Tuner。顧名思義這是一項AutoML的工具,可叫系統花點時間幫你找最佳的MCU AI模型。但現想很豐滿,現實很骨感,其表現是否會比有經驗工程師設計的模型來的表現更好,就有待觀察,這裡就暫時略過說明。有興趣的朋友可先參考官方釋出的Youtube說明影片。
如果想要記錄訓練出的基本資料,Edge Impulse也有支援雲端儲存備份的功能,進到「版本管理(Versioning)」頁面,按下左上角【Store your current project version】即可記錄下目前版本的重要資訊,達到MLOps的基本能力,其主要動作如下顯示。
/* Edge Impulse 版本管理主要動作 */
[1/9] Retrieving project and block configuration...
[2/9] Classifying test data...
Generating features for MFCC...
Classifying data for NN Classifier...
Classifying data for float32 model...
[3/9] Creating C++ library...
[4/9] Retrieving 81 data items...
[5/9] Writing data...
[6/9] Waiting for S3 mount to become available...
[7/9] Archiving files...
[8/9] Uploading version...
[9/9] Storing version x...
好不容易訓練、測試、調整好的模型,最後還是得佈署到開發板上,讓MCU直接運行才算是真的tinyML, Edge AI,相關流程如圖Fig. 22-3所示。目前Edge Impulse提供兩種方式佈署,如下所示。
Edge Impulse雲端這邊,同時只能二選一輸出,當選擇好了,頁面下方會出現RAM, Flash使用量、推論時間(Latency)、模型精確度及混淆矩陣。另外還可依使用資源及推論效果來選已量化成8位元整數(INT8),或者未量化前的32位元浮點數(Float32)的模型輸出。最後按下【Build】就會開始建置,前者只是轉出源碼,所以速度較快,而後者要完整編譯,所以要等比較久一點。當完成後,兩者都會產生一個ZIP格式壓縮檔。
另外最近Edge Impulse剛推出EON編譯器(和前面提到的EON Tuner工作內容不同),可再對模型進行深度優化,號稱最高可達50%的簡化,但從圖表上的數字來看,這個模型太小,所以降幅也不大。可自行選是否要開啟這項功能,沒有強制性。或者輸出兩種,再自行比對其表現性。
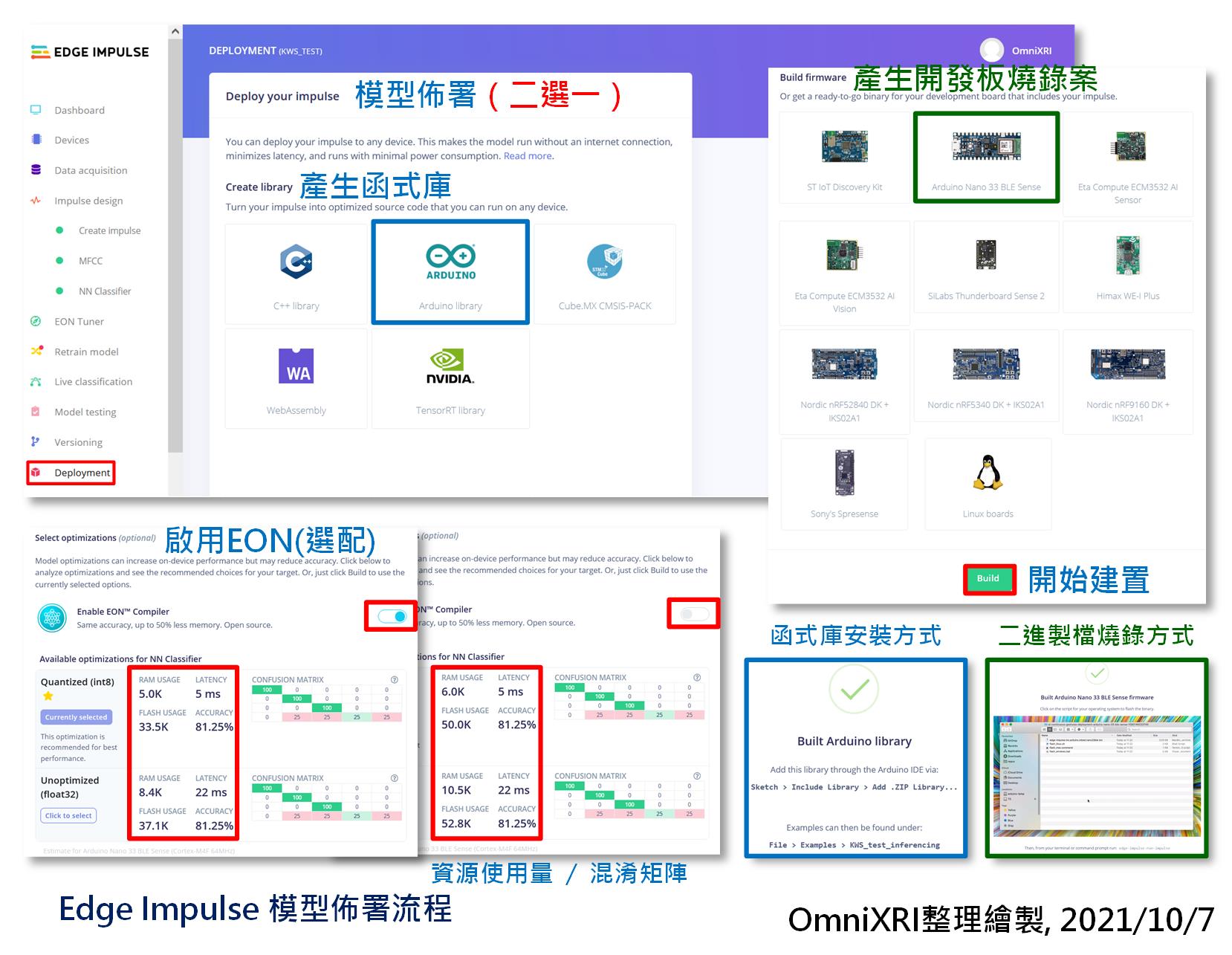
Fig. 22-3 Edge Impulse 模型佈署流程。(OmniXRI整理繪製, 2021/10/7)
接著說明如何將程式燒錄到開發板上,同樣地也有兩種模式,可以自行選擇。
直接燒錄:
以「Arduino Nano 33 BLE Sense」為例,解壓縮kws_test-nano-33-ble-sense-v4.zip(kws_test為專案名稱,會依實際專案名稱而不同)後會得到二進制檔(MCU韌體)firmware.ino.bin和燒錄程序檔flash_windows.bat(windows用),執行後者就能把程式燒進開發板中。
使用Arduino IDE編譯上傳:
開啟Arduino IDE前,記得把「edge-impulse-daemon」的命令列視窗關閉,以免佔住序列埠的使用權,導致後面編譯好的程式無法上傳。接著開啟Arduino IDE,點選[主選單]-[草稿碼]-[匯入程式庫]-[加入ZIP程式庫...],選擇剛才Edge Impulse產出的ei-kws_test-arduino-1.0.3.zip(kws_test為專案名稱,會依實際專案名稱而不同)。接著點選[主選單]-[檔案]-[範例]-[KWS_test_inferencing]下的[nano_ble33_sense_microphone_continuous]產生可執行麥克風連續收音的範例程式。按左上角快捷鍵箭頭符號按鍵,進行MCU程式編譯及上傳。
完成上傳後,點選[主選單]-[工具]-[序列埠監控視窗]開啟監控視窗(預設鮑率115,200bps),就能看到辨識結果的字串不斷的更新。此時對著開發板的麥克風說「紅」、「綠」或其它中文單詞及不說話(背景音)來測試輸出的字串及對應的置信度(機率)是否正確。完整的程序如圖Fig. 22-4所示。
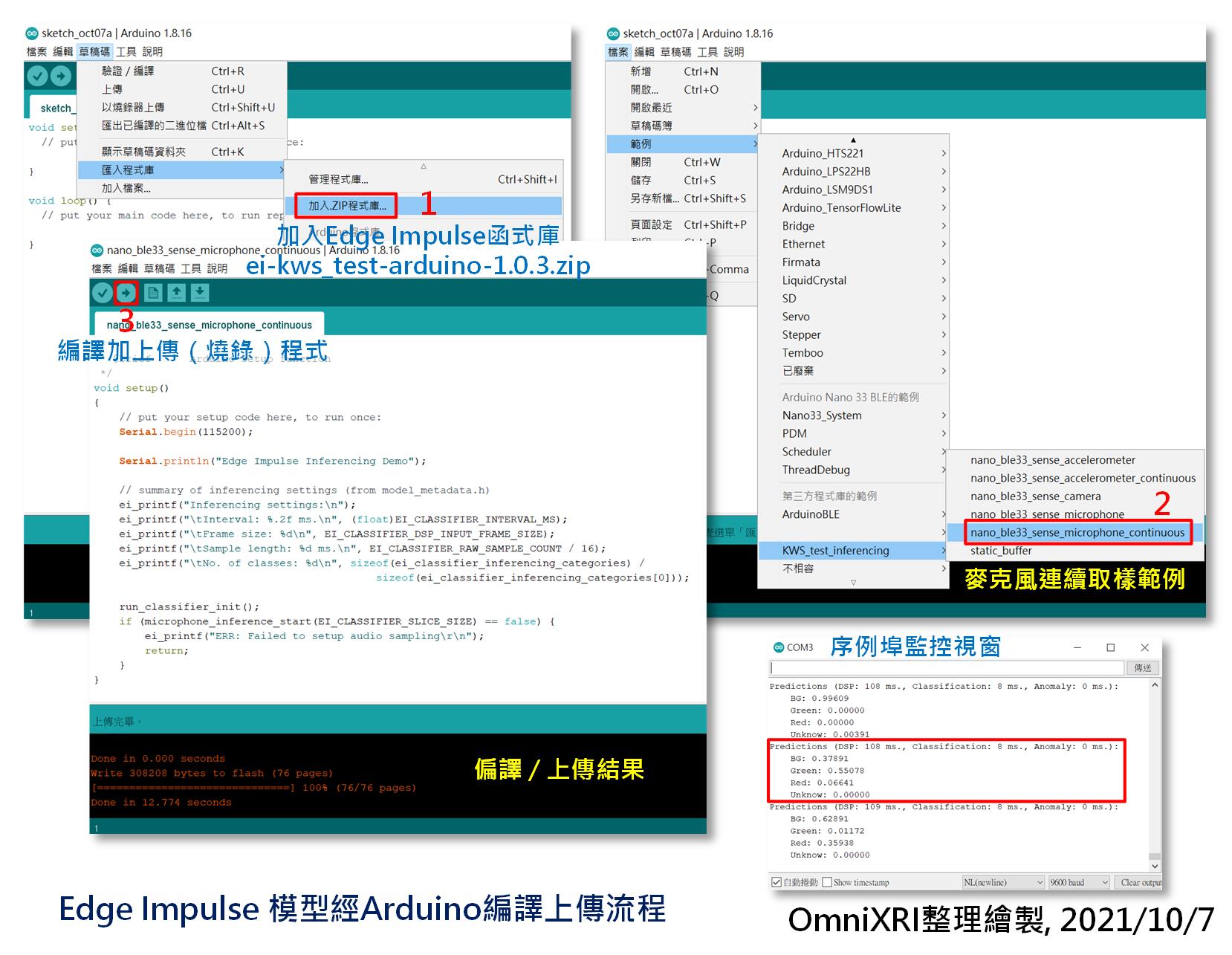
Fig. 22-4 Edge Impulse 模型經Arduino編譯上傳流程。(OmniXRI整理繪製, 2021/10/7)
經過連續三天的介紹,恭禧大家終於完成第一個tinyML專案,自定義中文單詞(喚醒詞)辨識。有沒有感覺透過這樣一站式開發工具比起[Day 16]、[Day 17]介紹的方法節省了不少力氣,尤其是開發環境建置和資料集建置。後續還有更多案例分享,敬請期待。
參考連結
Edge Impulse Tutorials - Responding to your voice 說明文件
AI Tech Talk from Edge Impulse: EON Tuner: AutoML for real-world embedded devices
Edge Impulse Tutorials - Running your impulse locally
我們只split了training set跟test set,那train好modle之後,它顯示的validation set是哪來的呢?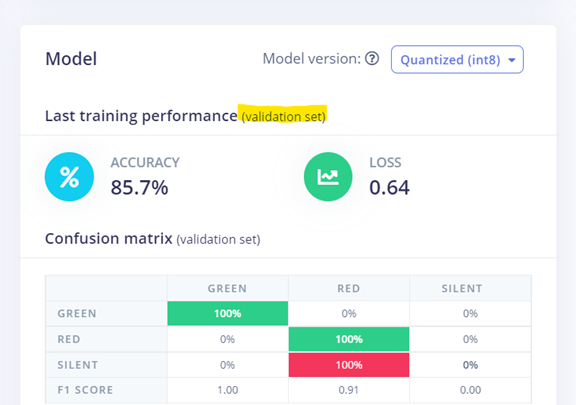
因為截圖時沒有特別秀出,你可注意一下在NN Classifier頁面按下【Start tringing】後,的右上角的Training Output視覺窗中有顯示一段話。
Job started
Splitting data into training and validation sets...
Splitting data into training and validation sets OKTraining model...
Training on 51 inputs, validating on 13 inputs
意思即系統會自動把Training Set再分離成80%訓練和20%驗證,這裡原始訓練集共有64筆,所以被分割成51筆訓練和13筆驗證。

