隨著時代變化,「Data」彷彿變成兵家必爭之地,從零售、傳產、工業、科技等等產業來看,會發現幾乎每個產業都在強調資料的重要性:包括資料分析、資料視覺化、資料探勘等等,從而演進為Machine Learning、AI資料應用等。在這個過程中,資料的量體也從幾十MB,演變成幾千GB、TB、PB,也就是所謂的「大數據」(Big Data)
但過往的解決方案像是單一節點資料運算也逐漸無法負荷大數據的分析了。因此Google提出MapReduce的解決方案,通過分散式節點來加強大數據運算的效能。之後也轉變成Hadoop、Spark這兩項經典的數據分析解決方案,在OLAP的應用上更進了一步
而阿里雲,也提供了雲原生的數據分析工具:MaxCompute,以及數據流自動化、整合工具 Dataworks。接下來筆者介紹完兩款服務後,會進行簡易的實作
屬於資料倉儲 (DataWarehouse)的一種,主要用於大量結構化數據的SQL分析。一般在企業的資料分析師可能要分析大量數據時,還需要同時維護分散式運算系統(自建Hadoop or Apache Spark);但若是使用單一運算系統來操作,又有效能不足的疑慮。因此通過MaxCompute,可以省去上述的困擾,在下方的實作截圖中,可以看到MaxCompute是根據運算量來進行計費;但如果是穩定需要使用運算效能,那也可以選擇包年包月的方式來使用
比較特殊的是,MaxCompute無法單獨使用,必須搭配Dataworks一同使用,是稍微可惜一點的地方,但好處在於可以快速整合其他資料分析工具,直接打造成一套ETL流程
數據工場 (Dataworks)
屬於數據分析的PaaS服務,主要提供了一站式資料治理平台,包含了:Data Integration、Data Studio、Data Map、Data Quality、Data Service
Data Integration 資料整合:
主要是作為offline的離線同步工具,針對結構化以及半結構化的資料進行同步,但需要注意,此工具不包含像是Pub/Sub的資料流發布與訂閱的功能
Data Studio 資料開發:
此功能協助開發者通過視覺化的方式來佈建資料流的邏輯,並且可以用業務本身以及任務的視角來重新組織程式碼的撰寫。在進行資料開發的時候,其邏輯為業務流程 > 解決方案,通過部署單一或者多個業務流程來搭建屬於自己的資料解決方案
Data Map 資料地圖:
資料地圖可以讓使用者在Metadata(中繼資料)的基礎上提供企業數據目錄管理的功能,包含了全域數據檢索、中繼資料查詢、數據預覽。最主要是讓使用者可以更快的查詢數據、並且根據中繼資料提供的資訊,來達成更深的數據理解,並更好的使用這些數據
Data Quality 資料品質:
資料品質的服務可以讓使用者針對多個不同結構的資料源進行數據品質檢測,並且設定不同的告警標準。品質檢測以數據集 (DataSet)為單位,並根據自定義的標準來進行偵測。當發現數據有問題時,也會第一時間中止Data Work Flow,避免錯誤數據進一步汙染其餘正常數據,同時也會向使用者發出告警
Data Service 資料服務:
Data Service是針對企業API所開發的服務,主要可用於搭建統一的數據服務平台,同步管理對內對外的API服務。同時也可以透過此服務將資料表生成API,並快速部署到API Gateway (阿里雲API服務)。最大的特點是,使用者只需要管理好API本身的設計邏輯即可,不必擔心底層的環境
DataWorks 流程示意圖:
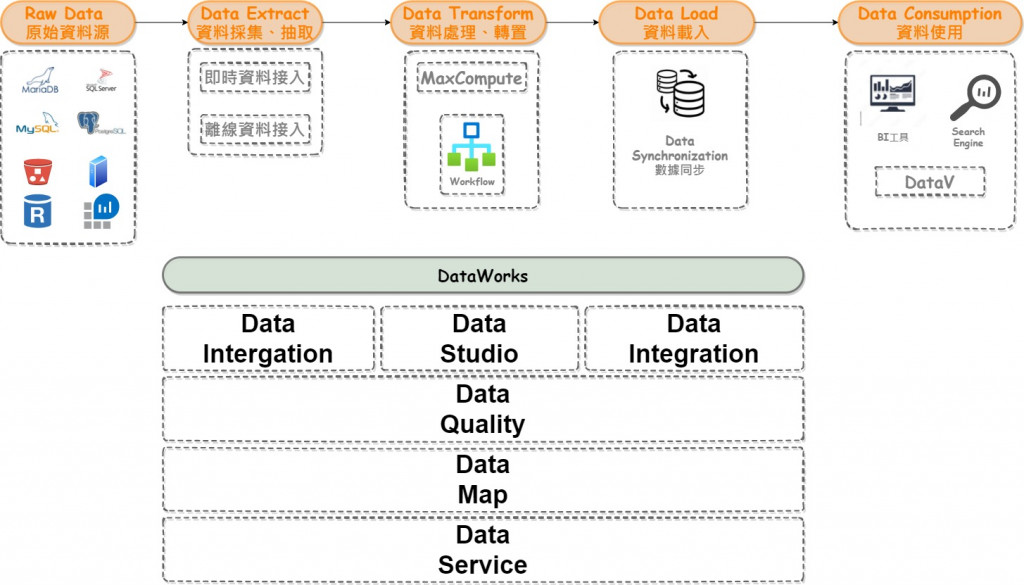
根據上述示意圖,DataWorks其實就是所謂的ETL的流程圖,把Dataworks當成是一個工具箱,裡面有諸多工具可以協助使用者打造自己的一套ETL流程,也就是在「Data Studio 資料開發」中的業務流程 > 解決方案,組合自己的資料清理跟整理流程
實作示意圖:
本次實作僅會帶到如何開立Dataworks的基本單位:工作站,並且在這個工作站內,會在Datasudio中建立表,並從本地端上傳一份csv,並運用Maxcompute進行SQL搜尋
在導覽列中找到Dataworks,並且選擇地區進行開通,注意,MaxCompute和Dataworks因為是綁在一起的,所以稍晚進行MaxCompute開通也要選擇一樣的地區,此處選擇新加坡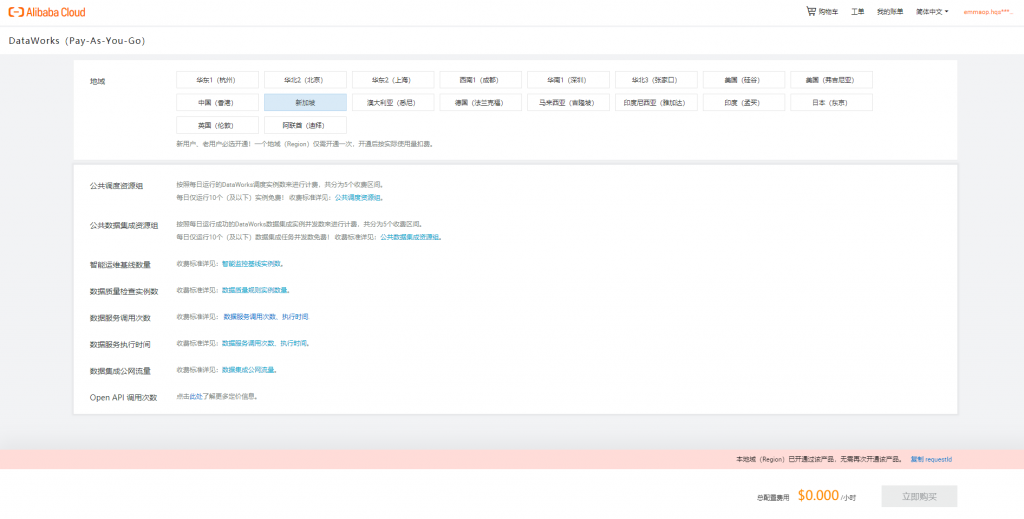
此處建立工作空間名稱完成即可,選擇簡單模式測試使用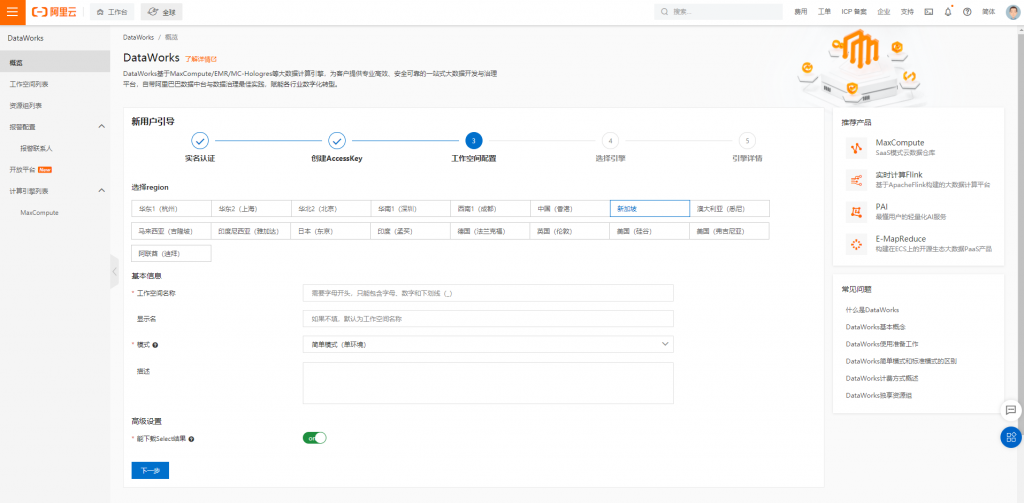
接下來選擇引擎,此處直接點選MaxCompute並使用按量付費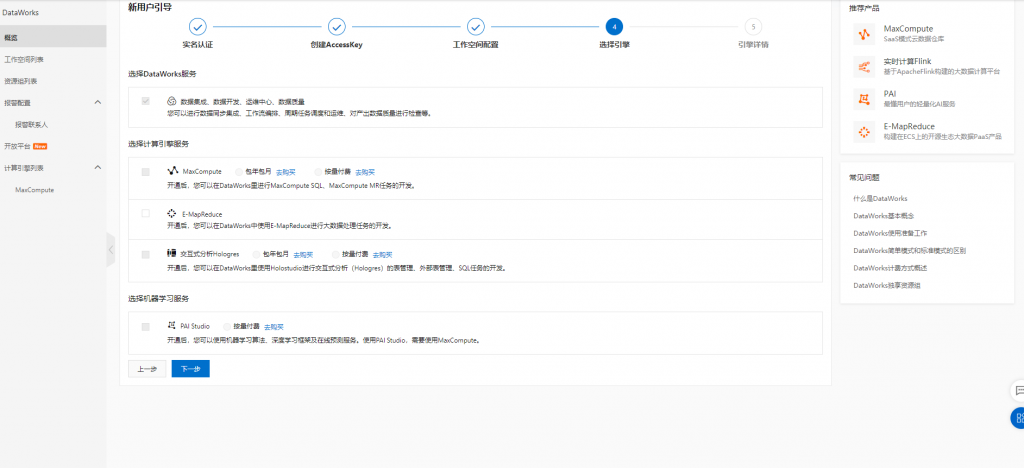
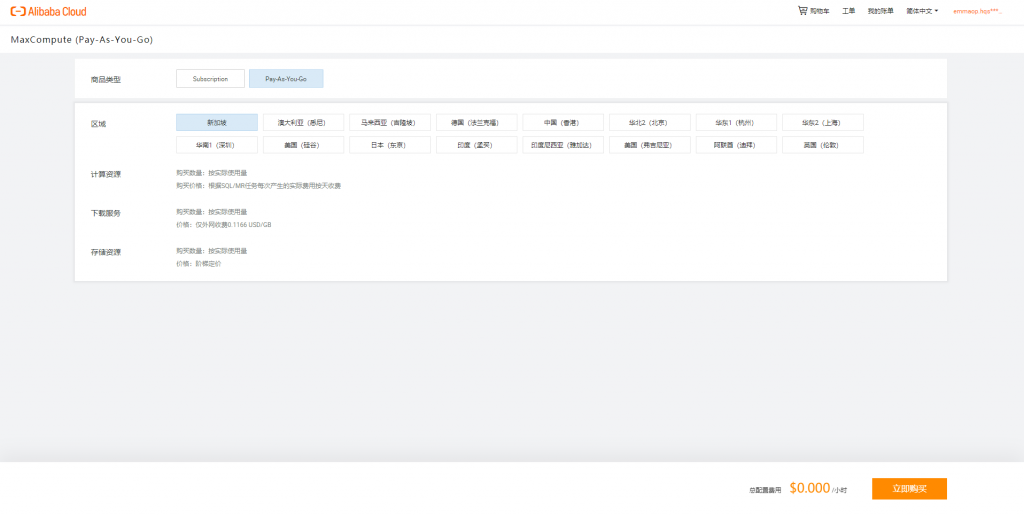
完成之後,回到Dataworks,並查看是否開通引擎成功,有標誌就代表開通成功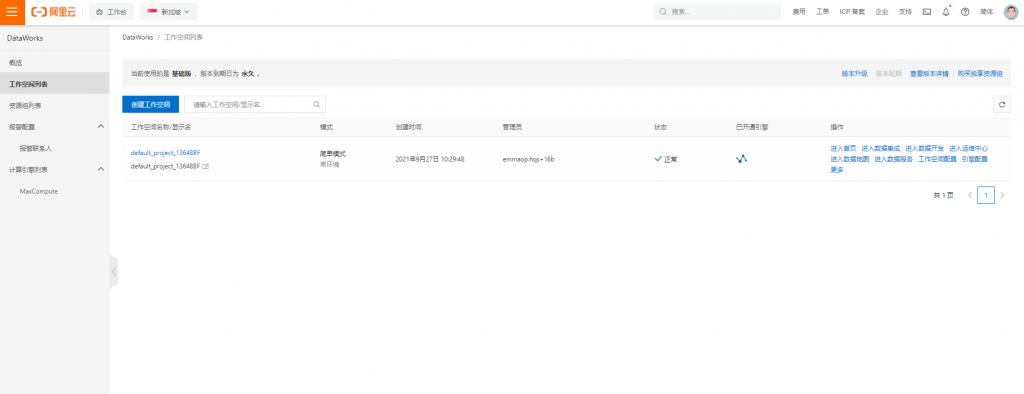
上述步驟完成後,點選Dataworks首頁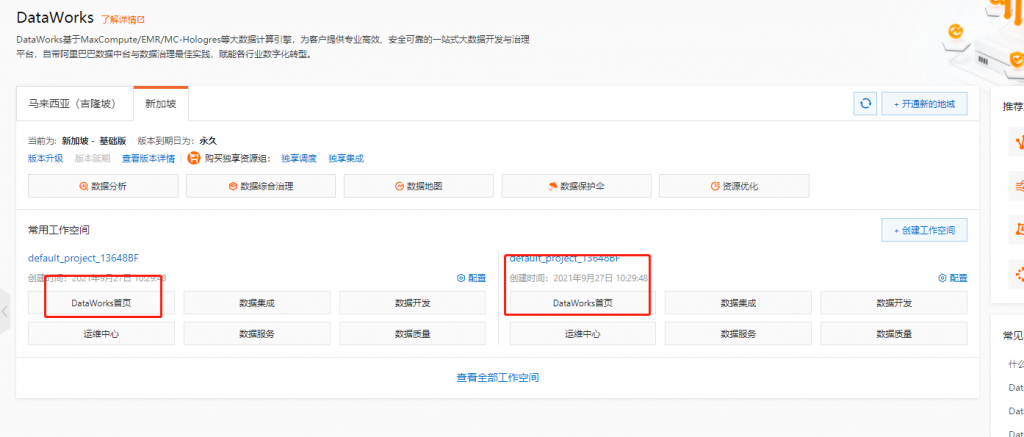
進入Dataworks的操作頁面,選擇左邊欄的DataStudio數據開發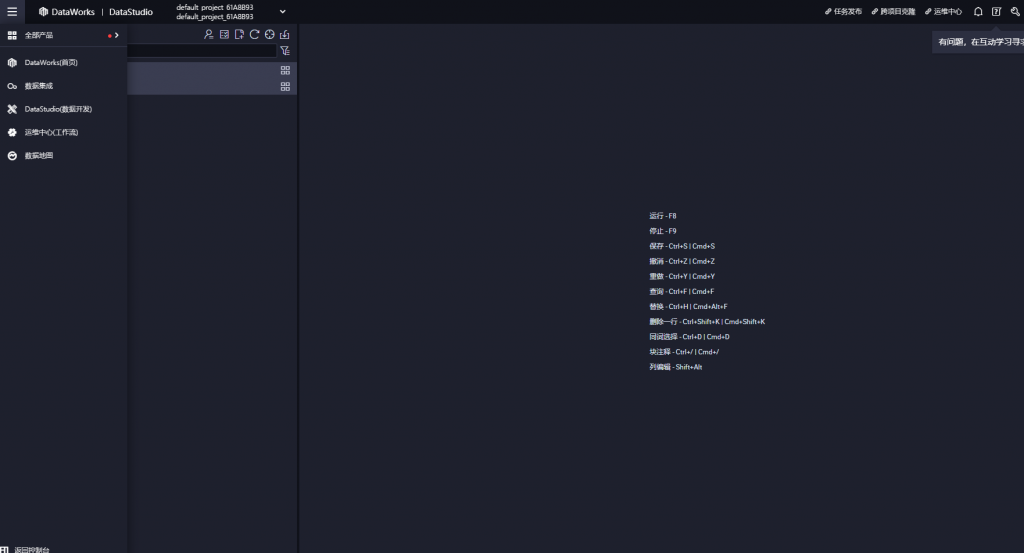
點選表管理,以及上方欄位的新增表按鈕,並創建新表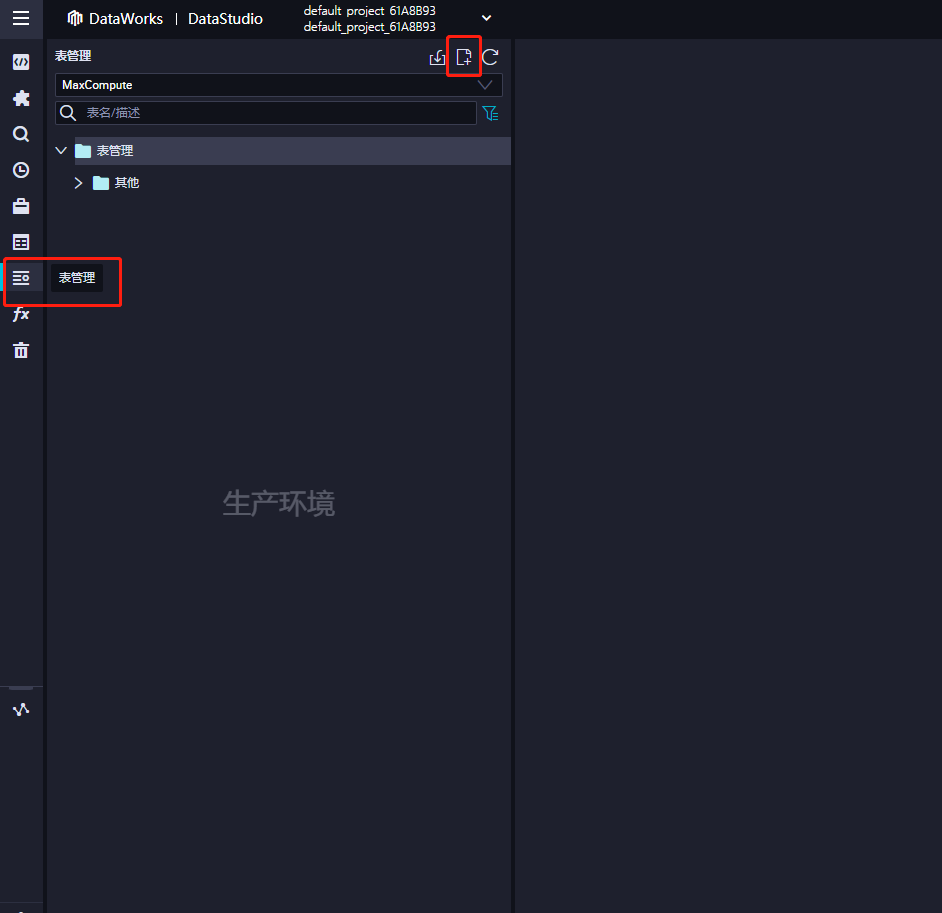
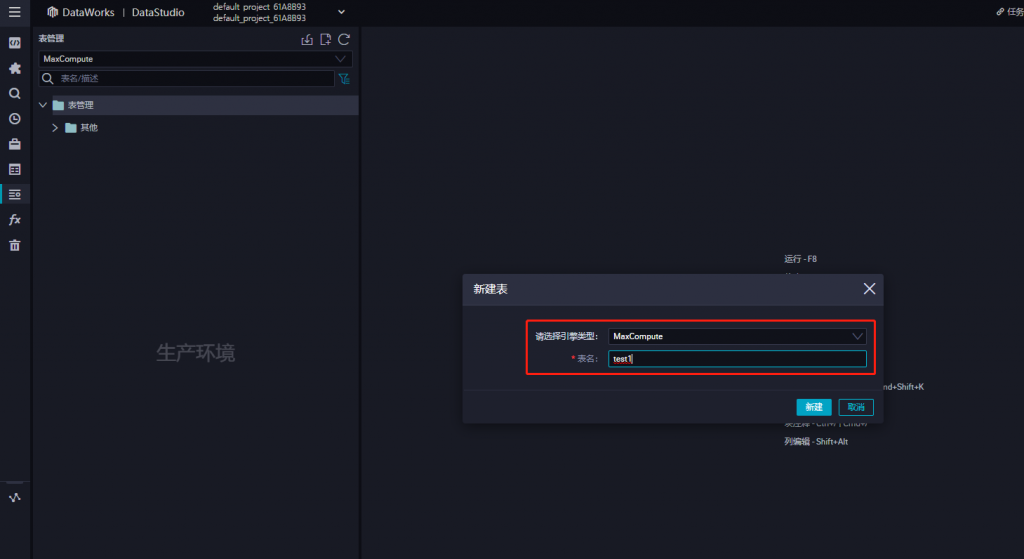
中文名為表的名稱,輸入後,請先新增主題*(主題是用以分類的資料夾而已,也可以不新增)*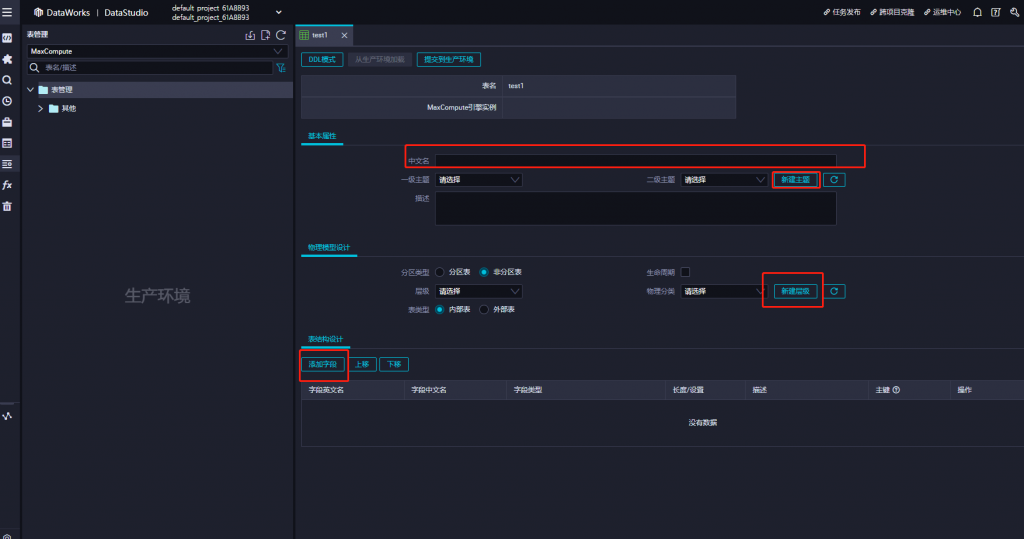
這邊有分成一級主題和二級主題,我們僅新建一級主題即可,二級主題是除非有其他考量,需要特別進行分類,再建立二級主題即可
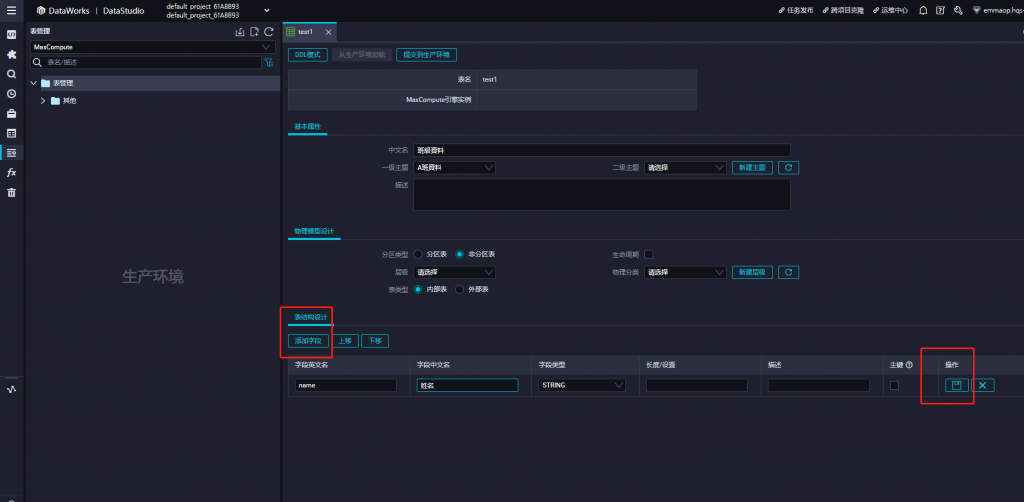
點選左下角圖標,回到原本的頁面選擇添加字段,進行表的結構設計,設計完成後點選右邊的儲存按鈕;物理模型設計可以暫時不必理會,僅是做分類用而已
完成設置後,選擇提交到生產環境,建表完成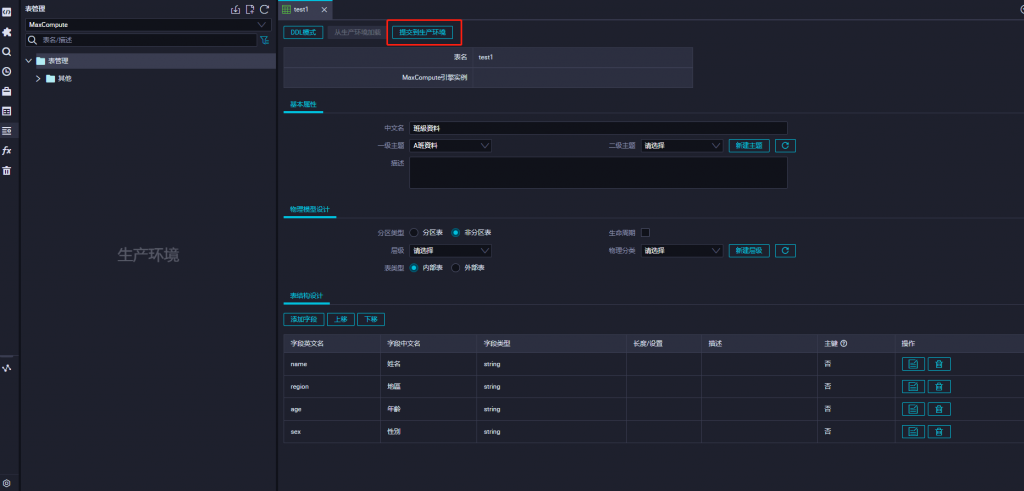
表建立完成後,點選匯入資料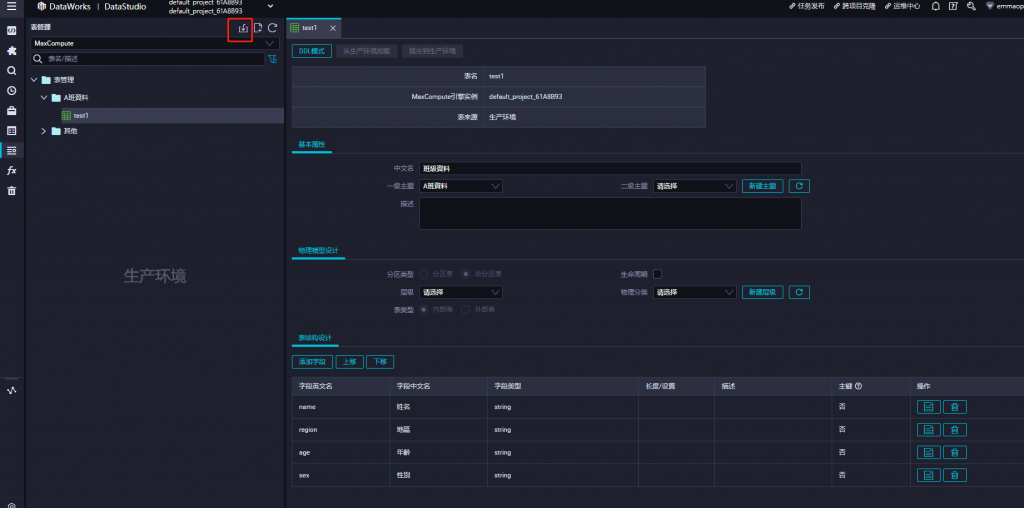
輸入表名,查到test1,選擇下一步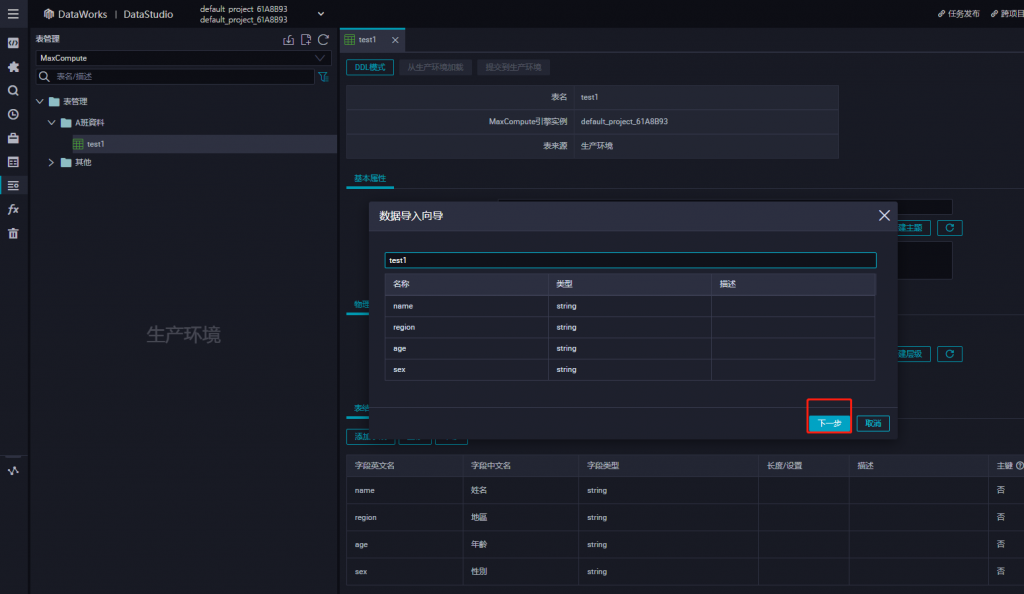
上傳csv檔,可以預覽到數據,選擇下一步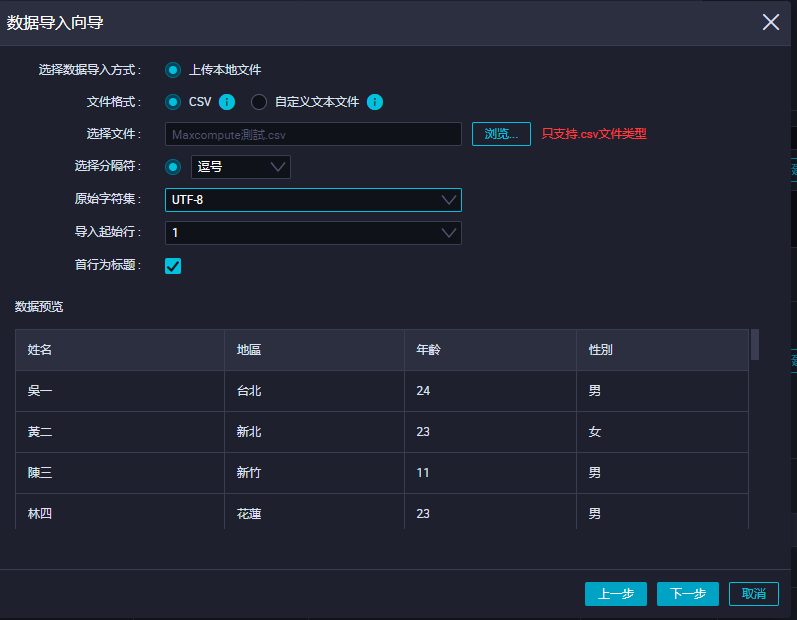
做表抬頭與值的配對,選擇導入數據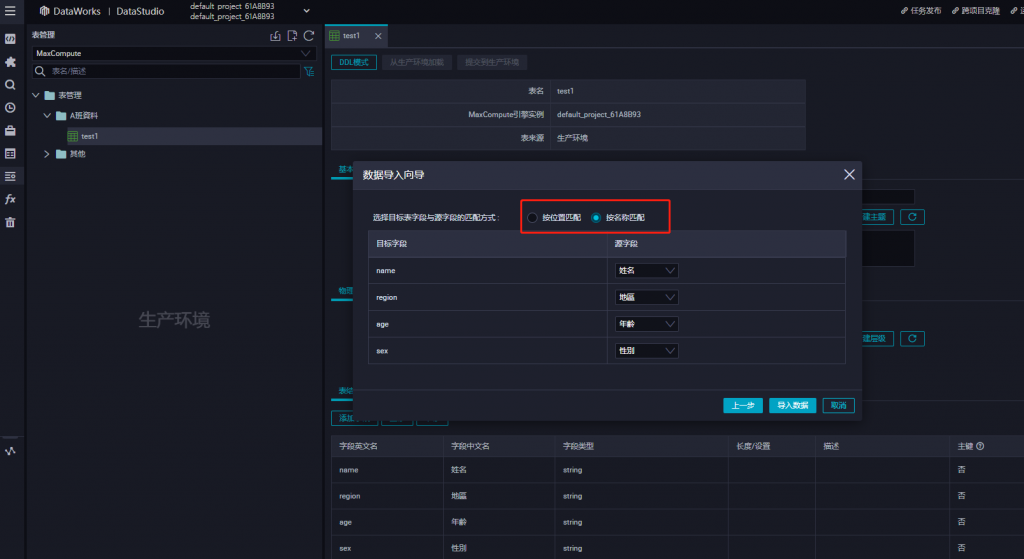
導入成功後,直接來做SQL分析,選擇左上角放大鏡符號,新建一個臨時查詢任務 ,並選擇ODPS SQL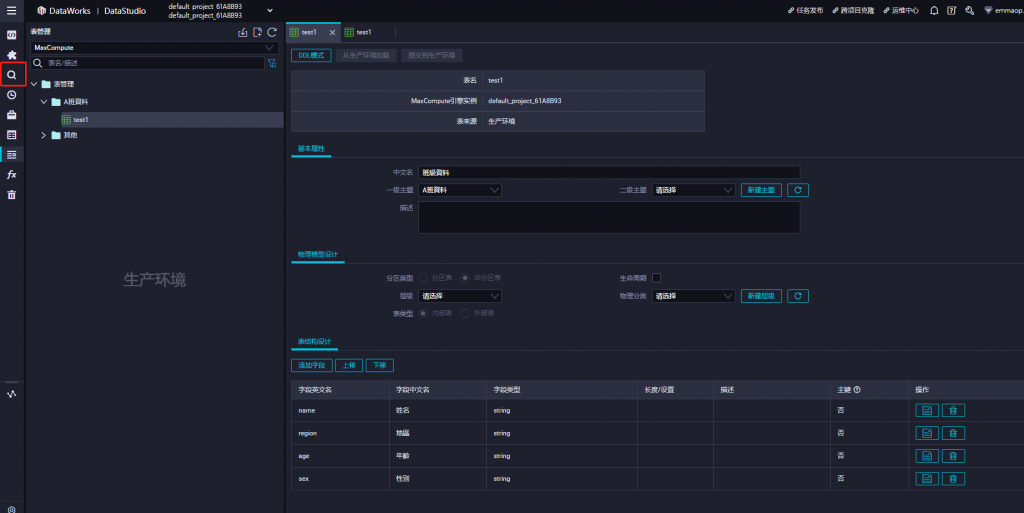
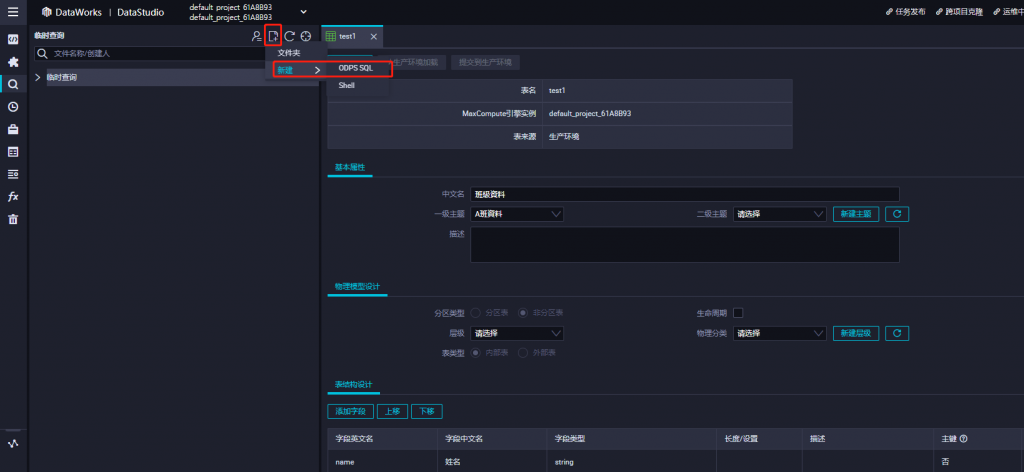
建立運算節點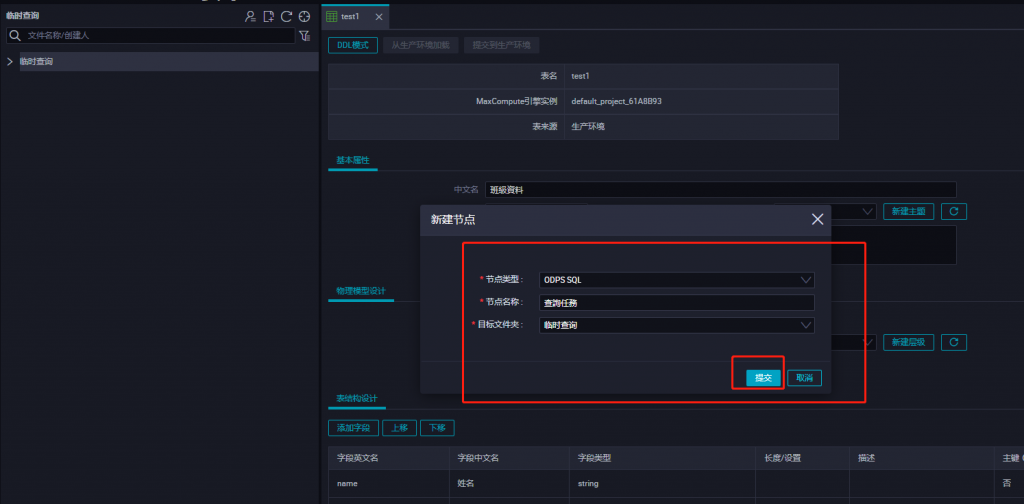
建立完成後,即可點選左上角儲存,並滑鼠右移選擇執行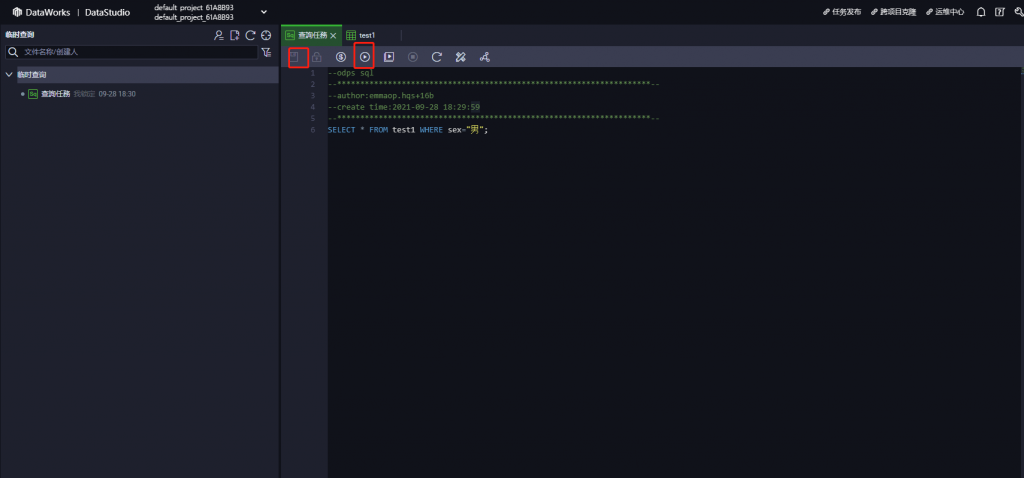
每次運行都是通過MaxCompute來進行運算,所以都會按量收費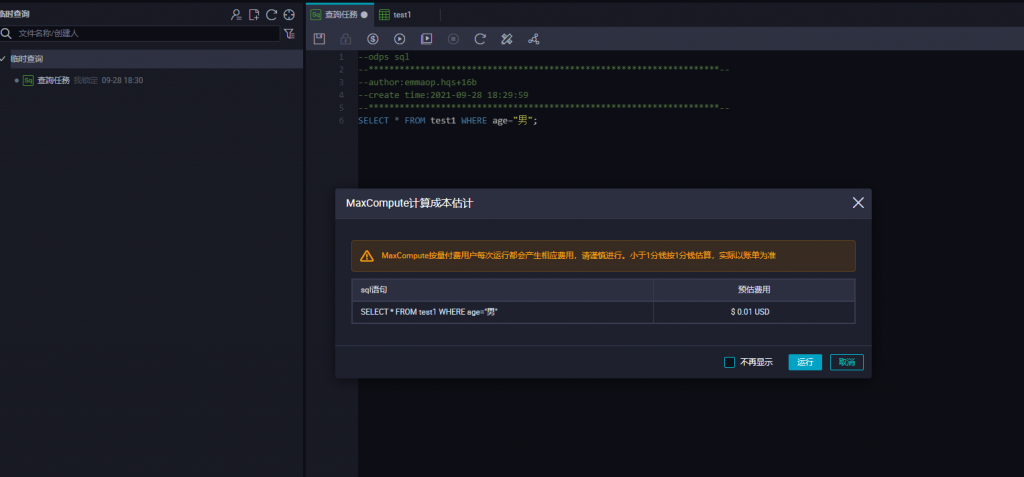
完成運行結果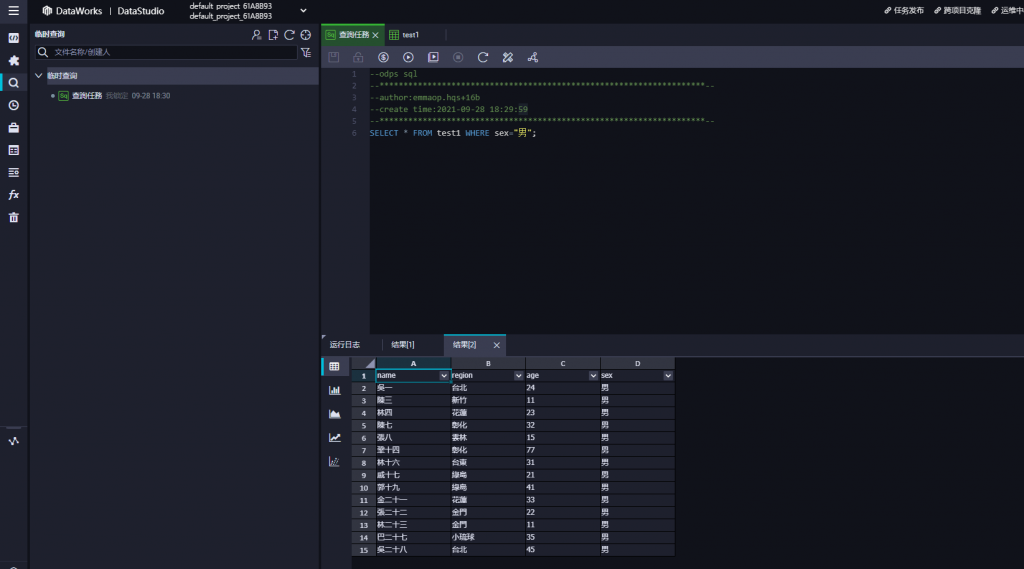
本次實作到這邊結束,Dataworks搭配Maxcompute還有相當多有趣的東西可以進行實作,本次礙於篇幅僅介紹其中一小段服務,個人認為若要進行數據相關的開發,透過Dataworks的確能有效率的完成任務,也算是拋磚引玉,若有興趣的人可以再自行嘗試囉


 iThome鐵人賽
iThome鐵人賽