Hugging Face 有完整的生態系和社群,我們幾乎可以只使用 Hugging Face ,就做完大部份最困難的 Transformer 的部份。其主要的 git repository Transformer,有高達 7 萬個星星,並且有超過 1 萬 6 千個 forks,可以說是社群能量相當的驚人。
Hugging Face 是開源的,其授權是 Apache-2.0 license,也就是說完全免費且可以商用,並且不會被開源感染而要強迫開源。用如此開放的開源授權,加上解決了做 Transformer 應用程式的最大痛點,也難怪整個生態系可以如此的壯大。
存放 Git repo 的地方叫 Github,存放 A 片的地方叫 Pornhub,那麼 Hugging Face Hub 又是什麼呢?
沒錯,就是存放 Hugging Face 的 AI model 的地方!在 Hugging Face Hub,你可以找到上萬個人家訓練好的 AI 模型。
如下圖所示,我們可以在 Models 這個選單,看到很多預訓好的 Models。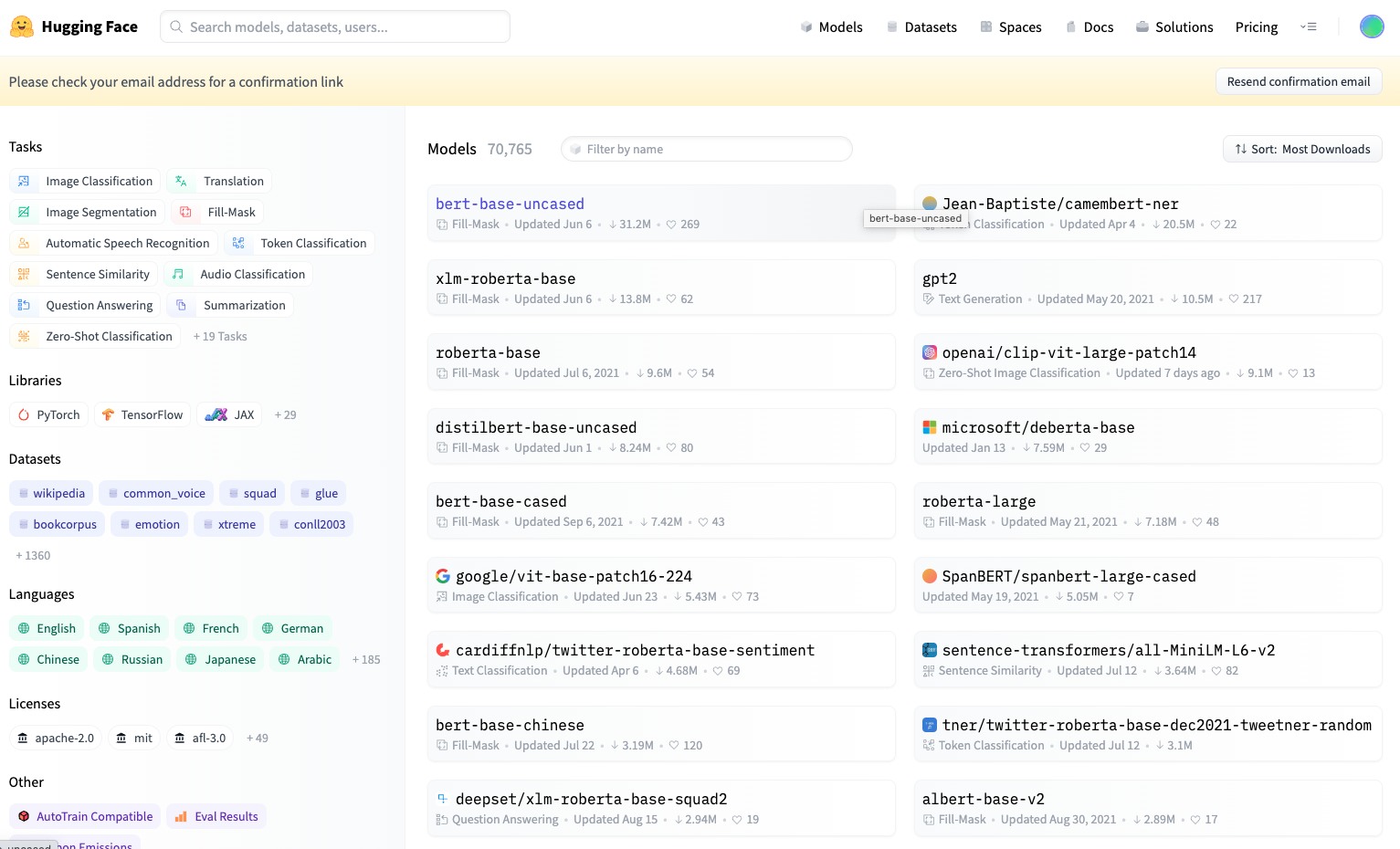
我們可以再進一步點一個 Model,看更多得細節。像是下圖這個 distilbert-base-uncased 是個簡化版的 BERT model。我們可以看到很多的資訊、包含了可用的
AI 框架、授權、引用的論文等等的資訊。
在右邊的面版還有一個 Hosted inference API,你可以在這裡玩一下這個 Model。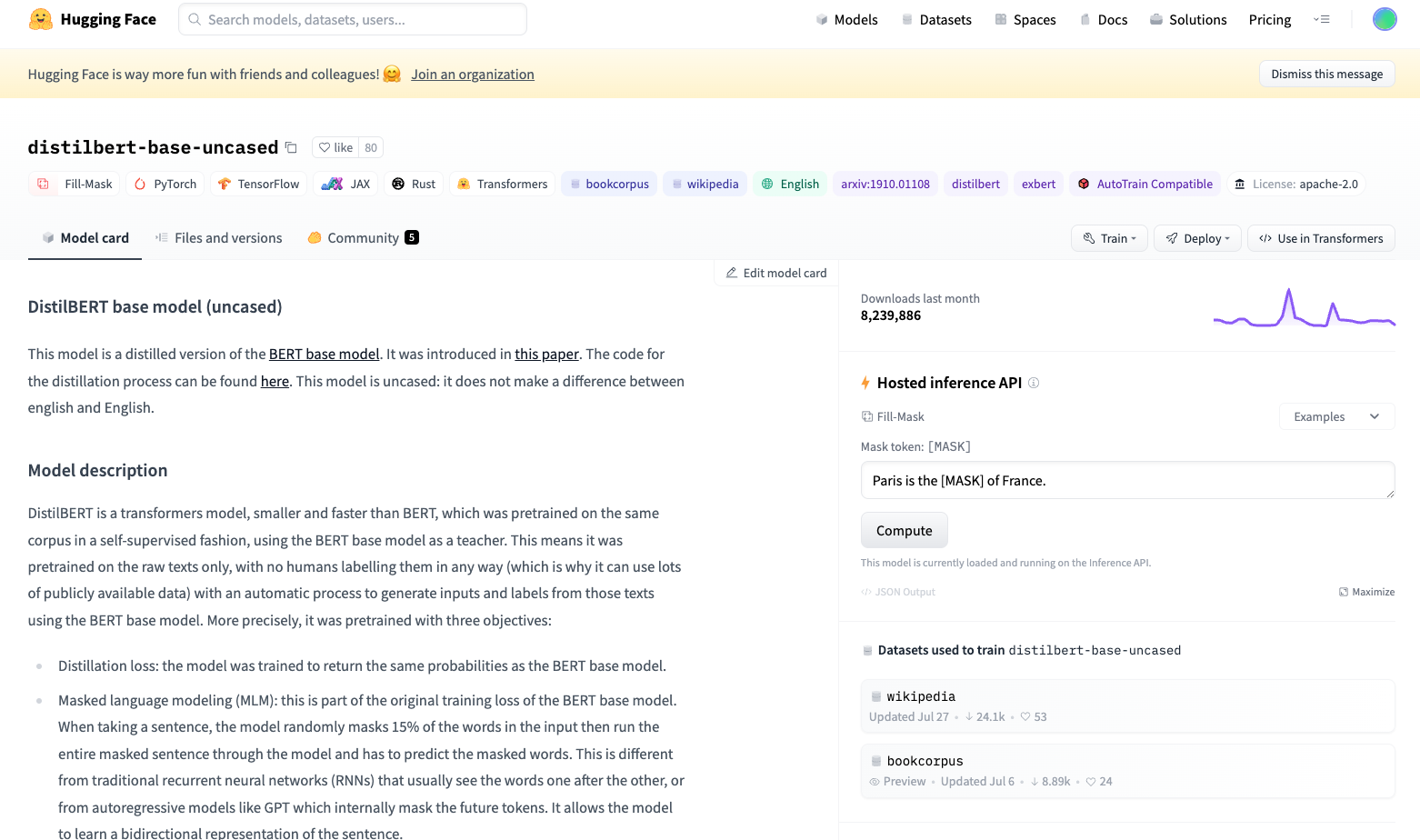
另外還有 Datasets 的部份,很多資料集可以取得。未來我們也會再用到許多 Hugging Face Hub 的功能。
那麼我們就立刻去註冊一個帳號吧!
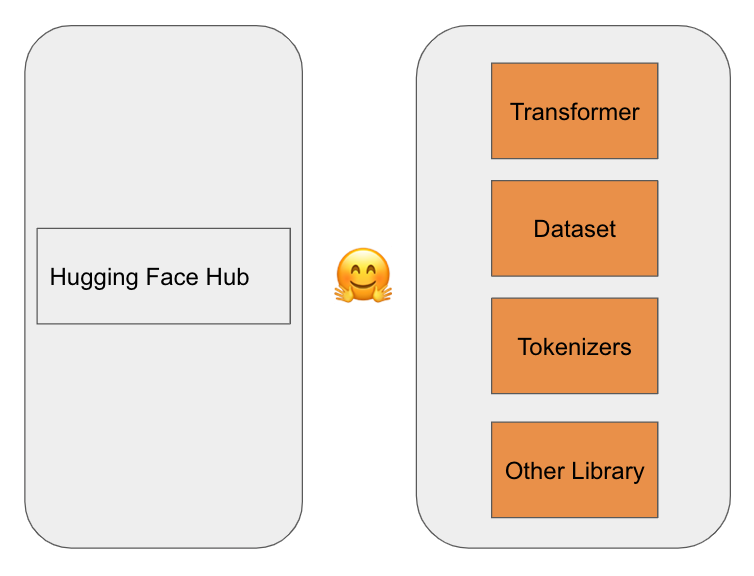
除了 Hub 以外,最重要的就是 Hugging Face 提供的 Library 啦!有了這些 Library,我們才有辦法更方便地來使用 Transformer 做自然語言處理的應用程式。這些 Library 中,有三個會是最常使用到的,我們稱之為三大神器。
Transformer 是三大神器之首,Hugging Face 就是靠這個 Library 讓 Transformer 更容易被大家使用和進一步開發應用程式。
https://github.com/huggingface/transformers
Tokenize 一般翻譯為斷詞,就是把一個句子裡面的每個字都拆出來。Tokenizers 還提供了很多 tokenization 的策略、還有前處理及後處理等功能。
https://github.com/huggingface/tokenizers
大家都知道,要訓練 AI 模型,最大的困難點往往在於資料的收集。而 Hugging Face Datasets 提供了和 Hub 取得資料集的 API,還可以和 Pandas 做交互使用,讓工程師輕鬆處理資料。
https://github.com/huggingface/datasets
當然除了三神器之外,還有其他用的Library,如加速用的 Accelerate、Optimum 等等,未來有機會也會介紹。
綜合上面所述,我畫一張簡單的圖來表示 Hub 和 Library 兩部份。左邊是 Hub 的部份,右邊是 Library 的部份,其中三大神器我們放在上面。