所謂的機器學習, 就是要讓機器學習數據間的關係, 並且用學習到的結果對新數據做預測
機器會透過學習不斷修改自己的模型, 學習時便會用到訓練集裡的資料
因此當我們拿到一份數據, 我們需要將資料切割成訓練集與數據集
舉例來說:
在學校老師會透過一些課堂範例讓我們練習一些數學公式 >> 課堂範例相當於“訓練集”
當我們學會後老師就會出一些小考讓我們用公式算出答案 >> 小考題目相當於“測試集”
當我們考完後學會的是公式而不是單純答案而已 >> 機器也是一樣, 學習到的是模型, 而不是硬背答案
python 中我們可以用 train_test_split() 來達到分類的目的
python 中我們可以用 train_test_split() 來達到分類的目的
arrays: 一開始需帶入欲分類的資料(list of data)
test_size: 測試集的比重, 應介於0-1, 若等於1代表資料全部都是測試集. 一般正常比重會是0.2, 0.25(default), 特殊情況可分配0.3, 但很少會超過0.4, 因為還是希望將大部分的資料都放入訓練集, 機器需要足夠的訊息來學習之間的關係
train_size: 訓練集比重, 跟test_size 合起來為1, 因此當我們填入test_size後train_size可以忽略
random_state: 此方法會隨機選取數據並分配到訓練集和測試集, random_state可以決定隨機數怎麼生成, 設成0 可以得到一樣結果
執行完可以看到x_train, y_train, x_test, y_test 的值如下
10筆資料裡有8筆被切成training data, 2筆是test data
在機器學習過程中, 機器會學習x_train 和y_train 之間的關係, 並利用學習到的關係改進模型, 這樣的過程稱作”擬合“, 再用擬合好的模型來預測測試集的結果, 把預測模型放在x_test, 就可以拿預測好的結果和y_test 比較, 若結果差距大, 稱為過度擬合, 表示訓練得太多, 可能富含太多訓練訊息, 後面課程會在介紹, 若結果很好, 代表預測效果佳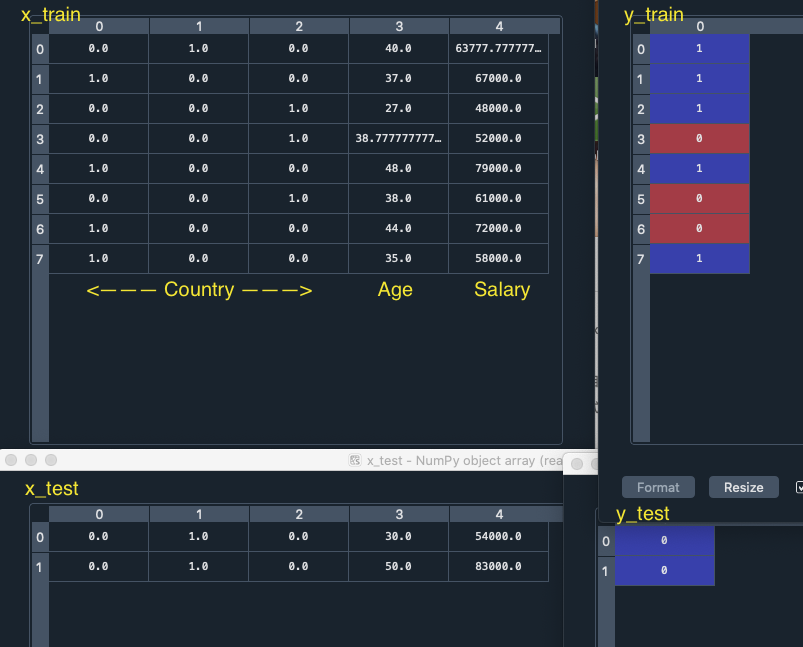
先來複習一下歐式距離
歐式距離就是算兩點間的距離
假設有兩個點 P1=(x1,y1), P2=(x2,y2)
那distance = (x1-x2)^2 + (y1-y2)^2 的開根號
歐式距離代表一種重要的關係, 因此在機器學習中, 可用來量化數據間的關係
以下我們在sample dataset中取兩點 P1, P2
並且利用歐式距離算法算出(x1-x2)^2 和 (y1-y2)^2
x 代表Age , y 代表Salary
可以發現Age的數量集太小, 跟Salary相比之下根本不重要
因此為了解決這種問題, 才需要做資料的特徵縮放, 將資料間的數量集變得一致
此外用特徵縮放的話, 算法的收斂速度會快很多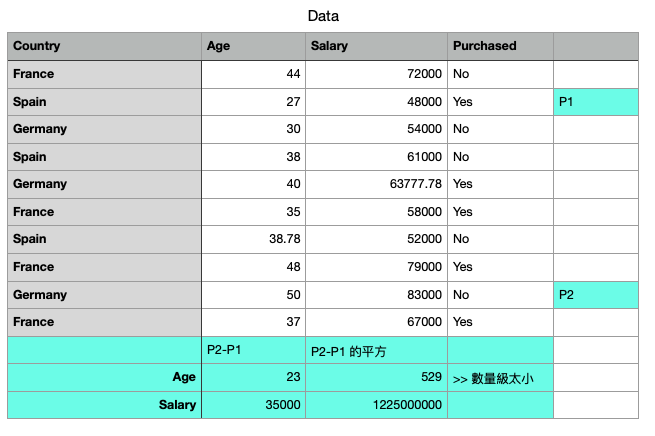
特徵縮放方法主要有兩個
x 代表自變量
mean(x) = average of x
StandardDeviation(x) 衡量數據中的浮動性
(x 跟最小值的差距)佔(最大與最小的差距)多少比例
python 中可以使用StandardScaler做特徵縮放
x_test 可以直接transform 是因為 sc_x 已經fit 過了
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
x_train = sc_x.fit_transform(x_train)
x_test = sc_x.transform(x_test)
Run 完可以看到 x_train 已經成功被轉化成特徵縮放的資料了
所有資料量級都一致了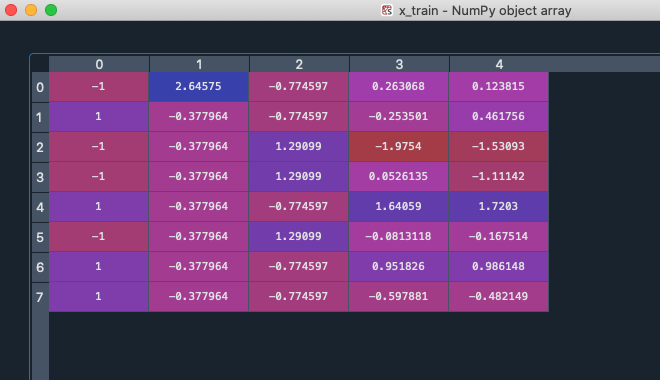
另外 y_train & y_test 需要特徵縮放嗎?
老師的回答是應變量不需要做特徵縮放, 因為sample 中的y 是purchased(only yes or no) 有明確的類別, 若應變量有回歸問題的時候就需要做特徵縮放(是連續準確的數據, 不是分類類別)


 iThome鐵人賽
iThome鐵人賽